MLflow
MLflow er en åpen kildekode-plattform designet for å forenkle og administrere livssyklusen til maskinlæring (ML). Den tilbyr verktøy for eksperimentsporing, kod...
5 min lesing
MLflow
Machine Learning
+3
Kubeflow er en åpen kildekode ML-plattform bygget på Kubernetes som effektiviserer utrulling, administrasjon og skalering av maskinlæringsarbeidsflyter på tvers av ulike infrastrukturer.
Kubeflows oppdrag er å gjøre skalering av ML-modeller og utrulling til produksjon så enkelt som mulig ved å utnytte Kubernetes sine muligheter. Dette inkluderer enkle, repeterbare og portable utrullinger på tvers av ulike infrastrukturer. Plattformen startet som en metode for å kjøre TensorFlow-jobber på Kubernetes og har siden utviklet seg til et allsidig rammeverk som støtter et bredt spekter av ML-rammeverk og verktøy.
Kubeflow Pipelines er en kjernekomponent som lar brukere definere og kjøre ML-arbeidsflyter som rettede asykliske grafer (DAGer). Den gir en plattform for å bygge portable og skalerbare maskinlæringsarbeidsflyter ved bruk av Kubernetes. Pipelines-komponenten består av:
Disse funksjonene gjør det mulig for dataforskere å automatisere hele prosessen med datapreprosessering, modelltrening, evaluering og utrulling, noe som fremmer reproduserbarhet og samarbeid i ML-prosjekter. Plattformen støtter gjenbruk av komponenter og pipelines, og gjør dermed opprettelsen av ML-løsninger mer strømlinjeformet.
Kubeflows sentrale dashbord fungerer som hovedgrensesnittet for tilgang til Kubeflow og dets økosystem. Det samler brukergrensesnittet til ulike verktøy og tjenester i klyngen, og gir et samlet tilgangspunkt for administrasjon av maskinlæringsaktiviteter. Dashbordet tilbyr funksjonaliteter som brukergodkjenning, flerbrukerisolasjon og ressursstyring.
Kubeflow integreres med Jupyter Notebooks og tilbyr et interaktivt miljø for datautforskning, eksperimentering og modellutvikling. Notebooks støtter ulike programmeringsspråk og lar brukere opprette og kjøre ML-arbeidsflyter i samarbeid.
Kubeflow Metadata er et sentralisert lager for sporing og administrasjon av metadata knyttet til ML-eksperimenter, kjøringer og artefakter. Det sikrer reproduserbarhet, samarbeid og styring i ML-prosjekter ved å gi et konsistent syn på ML-metadata.
Katib er en komponent for automatisert maskinlæring (AutoML) i Kubeflow. Den støtter hyperparametertuning, tidlig stopp og søk etter nevrale arkitekturer, og optimaliserer ytelsen til ML-modeller ved å automatisere søket etter optimale hyperparametre.
Kubeflow brukes av organisasjoner i ulike bransjer for å effektivisere sine ML-operasjoner. Noen vanlige bruksområder inkluderer:
Spotify benytter Kubeflow for å styrke sine dataforskere og ingeniører i utvikling og utrulling av maskinlæringsmodeller i stor skala. Ved å integrere Kubeflow med eksisterende infrastruktur har Spotify effektivisert sine ML-arbeidsflyter, redusert tiden til markedet for nye funksjoner og forbedret effektiviteten i anbefalingssystemene sine.
Kubeflow lar organisasjoner skalere sine ML-arbeidsflyter opp eller ned etter behov og rulle dem ut på ulike infrastrukturer, inkludert lokalt, i skyen og i hybride miljøer. Denne fleksibiliteten bidrar til å unngå leverandørlåsing og muliggjør sømløse overganger mellom ulike datamiljøer.
Kubeflows komponentbaserte arkitektur legger til rette for reproduksjon av eksperimenter og modeller. Den tilbyr verktøy for versjonering og sporing av datasett, kode og modellparametre, som sikrer konsistens og samarbeid mellom dataforskere.
Kubeflow er designet for å være utvidbar og muliggjør integrasjon med ulike andre verktøy og tjenester, inkludert skybaserte ML-plattformer. Organisasjoner kan tilpasse Kubeflow med ekstra komponenter og dra nytte av eksisterende verktøy og arbeidsflyter for å styrke sitt ML-økosystem.
Ved å automatisere mange av oppgavene knyttet til utrulling og administrasjon av ML-arbeidsflyter, frigjør Kubeflow dataforskere og ingeniører slik at de kan fokusere på mer verdiskapende oppgaver, som modellutvikling og optimalisering, noe som gir økt produktivitet og effektivitet.
Kubeflows integrasjon med Kubernetes gir mer effektiv ressursutnyttelse, optimaliserer tildeling av maskinvare og reduserer kostnader knyttet til kjøring av ML-arbeidsbelastninger.
For å begynne å bruke Kubeflow kan brukere rulle det ut på et Kubernetes-kluster, enten lokalt eller i skyen. Det finnes ulike installasjonsguider som dekker forskjellige kunnskapsnivåer og infrastrukturbehov. For nybegynnere på Kubernetes finnes det administrerte tjenester som Vertex AI Pipelines, som gjør det enklere å komme i gang ved å håndtere infrastrukturen og la brukeren fokusere på å bygge og kjøre ML-arbeidsflyter.
Denne detaljerte gjennomgangen av Kubeflow gir innsikt i funksjonalitetene, fordelene og bruksområdene, og tilbyr en helhetlig forståelse for organisasjoner som ønsker å styrke sine maskinlæringsmuligheter.
Kubeflow er et åpen kildekode-prosjekt laget for å legge til rette for utrulling, orkestrering og administrasjon av maskinlæringsmodeller på Kubernetes. Det tilbyr en komplett ende-til-ende-stakk for maskinlæringsarbeidsflyter, som gjør det enklere for dataforskere og ingeniører å bygge, distribuere og administrere skalerbare maskinlæringsmodeller.
Deployment of ML Models using Kubeflow on Different Cloud Providers
Forfattere: Aditya Pandey m.fl. (2022)
Denne artikkelen utforsker utrulling av maskinlæringsmodeller ved bruk av Kubeflow på ulike skyplattformer. Studien gir innsikt i oppsettprosessen, distribusjonsmodeller og ytelsesmålinger for Kubeflow, og fungerer som en nyttig guide for nybegynnere. Forfatterne fremhever verktøyets funksjoner og begrensninger og demonstrerer bruken i opprettelse av ende-til-ende maskinlæringspipelines. Artikkelen har som mål å hjelpe brukere med minimal Kubernetes-erfaring å ta i bruk Kubeflow for modellutrulling.
Les mer
CLAIMED, a visual and scalable component library for Trusted AI
Forfattere: Romeo Kienzler og Ivan Nesic (2021)
Dette arbeidet fokuserer på integrasjon av pålitelige AI-komponenter med Kubeflow. Det tar for seg problemstillinger som forklarbarhet, robusthet og rettferdighet i AI-modeller. Artikkelen introduserer CLAIMED, et gjenbrukbart komponentrammeverk som inkorporerer verktøy som AI Explainability360 og AI Fairness360 i Kubeflow-pipelines. Denne integrasjonen legger til rette for utvikling av produksjonsklare maskinlæringsapplikasjoner ved bruk av visuelle redaktører som ElyraAI.
Les mer
Jet energy calibration with deep learning as a Kubeflow pipeline
Forfattere: Daniel Holmberg m.fl. (2023)
Kubeflow benyttes til å lage en maskinlæringspipeline for kalibrering av jetenergimålinger ved CMS-eksperimentet. Forfatterne bruker dyp læringsmodeller for å forbedre jetenergikalibrering, og viser hvordan Kubeflows muligheter kan utvides til anvendelser innen høyenergifysikk. Artikkelen diskuterer pipeline-effektiviteten i skalering av hyperparametertuning og tjenestegjøring av modeller effektivt på skyressurser.
Les mer
Kubeflow er en åpen plattform bygget på Kubernetes, utformet for å effektivisere utrulling, administrasjon og skalering av maskinlæringsarbeidsflyter. Den tilbyr et omfattende sett med verktøy for hele ML-livssyklusen.
Nøkkelkomponenter inkluderer Kubeflow Pipelines for arbeidsflytorchestrering, et sentralt dashbord, Jupyter Notebooks-integrasjon, distribuert modelltrening og -tjenester, metadatahåndtering og Katib for hyperparametertuning.
Ved å utnytte Kubernetes muliggjør Kubeflow skalerbare ML-arbeidsbelastninger på tvers av ulike miljøer og gir verktøy for eksperimentsporing og gjenbruk av komponenter, noe som sikrer reproduserbarhet og effektivt samarbeid.
Organisasjoner på tvers av bransjer bruker Kubeflow for å administrere og skalere sine ML-operasjoner. Kjente brukere som Spotify har integrert Kubeflow for å effektivisere modellutvikling og utrulling.
For å komme i gang, distribuer Kubeflow på et Kubernetes-kluster – enten lokalt eller i skyen. Installasjonsguider og administrerte tjenester er tilgjengelige for å hjelpe brukere på alle nivåer.
Oppdag hvordan Kubeflow kan forenkle dine maskinlæringsarbeidsflyter på Kubernetes, fra skalerbar trening til automatisert utrulling.
MLflow er en åpen kildekode-plattform designet for å forenkle og administrere livssyklusen til maskinlæring (ML). Den tilbyr verktøy for eksperimentsporing, kod...
Run Flow-komponenten i FlowHunt lar deg trigge og kjøre en annen arbeidsflyt innenfor din nåværende flyt. Send inn data, variabler og kontroller hvordan flyter ...
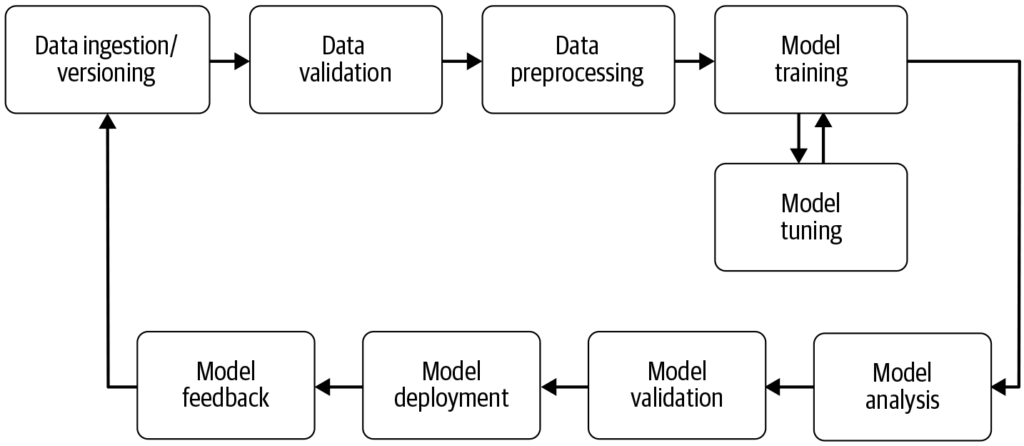
En maskinlærings-pipeline er en automatisert arbeidsflyt som strømlinjeformer og standardiserer utvikling, trening, evaluering og utrulling av maskinlæringsmode...