
Maskinlæring
Maskinlæring (ML) er en underkategori av kunstig intelligens (AI) som gjør det mulig for maskiner å lære fra data, identifisere mønstre, lage prediksjoner og fo...
3 min lesing
Machine Learning
AI
+4
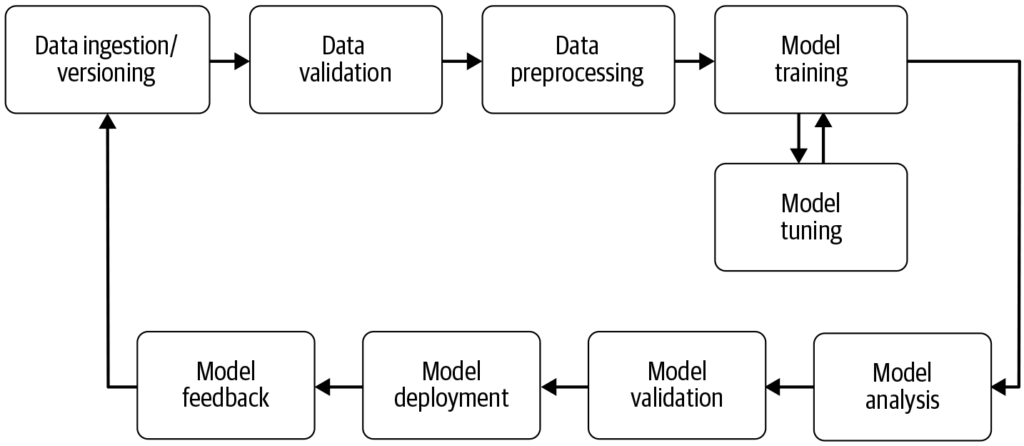
En maskinlærings-pipeline automatiserer stegene fra datainnsamling til utrulling av modell, og forbedrer effektivitet, reproduserbarhet og skalerbarhet i maskinlæringsprosjekter.
En maskinlærings-pipeline er en automatisert arbeidsflyt som strømlinjeformer utvikling, trening, evaluering og utrulling av modeller. Den øker effektiviteten, reproduserbarheten og skalerbarheten, og forenkler oppgaver fra datainnsamling til modellutrulling og vedlikehold.
En maskinlærings-pipeline er en automatisert arbeidsflyt som omfatter en serie steg involvert i utvikling, trening, evaluering og utrulling av maskinlæringsmodeller. Den er utformet for å strømlinjeforme og standardisere prosessene som kreves for å forvandle rådata til handlingsrettet innsikt gjennom maskinlæringsalgoritmer. Pipeline-tilnærmingen gir effektiv håndtering av data, modelltrening og utrulling, og gjør det enklere å administrere og skalere maskinlæringsoperasjoner.
Kilde: Building Machine Learning
Datainnsamling: Den innledende fasen hvor data samles inn fra ulike kilder som databaser, API-er eller filer. Datainnsamling er en metodisk praksis for å skaffe meningsfull informasjon for å bygge et konsistent og komplett datasett for et spesifikt forretningsformål. Disse rådataene er essensielle for å bygge maskinlæringsmodeller, men krever ofte forbehandling for å bli nyttige. Som fremhevet av AltexSoft, innebærer datainnsamling systematisk akkumulering av informasjon for å støtte analyse og beslutningstaking. Denne prosessen er avgjørende fordi den legger grunnlaget for alle påfølgende steg i pipelinen, og er ofte kontinuerlig for å sikre at modellene trenes på relevante og oppdaterte data.
Datapreprosessering: Rådata renses og transformeres til et egnet format for modelltrening. Vanlige forbehandlingssteg inkluderer håndtering av manglende verdier, koding av kategoriske variabler, skalering av numeriske egenskaper, og deling av data i trenings- og testsett. Dette stadiet sikrer at dataene har korrekt format og er fri for uoverensstemmelser som kan påvirke modellens ytelse.
Feature Engineering: Opprettelse av nye egenskaper eller utvelgelse av relevante egenskaper fra dataene for å forbedre modellens prediktive kraft. Dette steget kan kreve domenespesifikk kunnskap og kreativitet. Feature engineering er en kreativ prosess som omformer rådata til meningsfulle egenskaper som bedre representerer det underliggende problemet og øker ytelsen til maskinlæringsmodeller.
Modellvalg: Den riktige maskinlæringsalgoritmen(e) velges basert på problemtypen (f.eks. klassifisering, regresjon), datakarakteristikk og ytelseskrav. Hyperparametertuning kan også vurderes på dette stadiet. Valg av riktig modell er avgjørende da det påvirker nøyaktigheten og effektiviteten til prediksjonene.
Modelltrening: Den valgte modellen(e) trenes ved bruk av treningsdatasettet. Dette innebærer å lære de underliggende mønstrene og sammenhengene i dataene. Ferdigtrente modeller kan også brukes i stedet for å trene en ny modell fra bunnen av. Trening er et viktig steg hvor modellen lærer fra dataene for å kunne gjøre informerte prediksjoner.
Modellevaluering: Etter trening vurderes modellens ytelse ved bruk av et separat testdatasett eller gjennom kryssvalidering. Evalueringsmetrikker avhenger av det spesifikke problemet, men kan inkludere nøyaktighet, presisjon, recall, F1-score, gjennomsnittlig kvadrert feil, blant andre. Dette steget er avgjørende for å sikre at modellen presterer godt på ukjente data.
Modellutrulling: Når en tilfredsstillende modell er utviklet og evaluert, kan den rulles ut i et produksjonsmiljø for å gjøre prediksjoner på nye, ukjente data. Utrulling kan innebære å opprette API-er og integrere med andre systemer. Utrulling er siste trinn i pipelinen hvor modellen gjøres tilgjengelig for reell bruk.
Overvåkning og vedlikehold: Etter utrulling er det viktig å kontinuerlig overvåke modellens ytelse og trene den på nytt etter behov for å tilpasse seg endringer i datapunkter, og sikre at modellen forblir nøyaktig og pålitelig i virkelige omgivelser. Denne pågående prosessen sikrer at modellen forblir relevant og nøyaktig over tid.
Naturlig språkprosessering (NLP): NLP-oppgaver involverer ofte flere repeterende steg som datainnhenting, tekstvask, tokenisering og sentimentanalyse. Pipelines hjelper til å modulere disse stegene, noe som gjør det enkelt å endre og oppdatere uten å påvirke andre komponenter.
Prediktivt vedlikehold: I industrier som produksjon kan pipelines brukes til å forutsi utstyrsfeil ved å analysere sensordata, noe som muliggjør proaktivt vedlikehold og reduserer nedetid.
Finans: Pipelines kan automatisere behandlingen av finansielle data for å oppdage svindel, vurdere kredittrisiko eller forutsi aksjekurser, og forbedre beslutningsprosesser.
Helsevesen: I helsevesenet kan pipelines behandle medisinske bilder eller pasientjournaler for å bistå i diagnostikk eller forutsi pasientutfall, og dermed forbedre behandlingsstrategier.
Maskinlærings-pipelines er sentrale for AI og automatisering ved å tilby en strukturert ramme for å automatisere maskinlæringsoppgaver. Innen AI-automatisering sikrer pipelines at modeller trenes og rulles ut effektivt, noe som gjør det mulig for AI-systemer som [chatboter] å lære og tilpasse seg nye data uten manuell inngripen. Denne automatiseringen er avgjørende for å skalere AI-applikasjoner og sikre at de leverer konsistent og pålitelig ytelse på tvers av ulike domener. Ved å utnytte pipelines kan organisasjoner forbedre sine AI-evner og sikre at maskinlæringsmodellene forblir relevante og effektive i skiftende omgivelser.
Forskning på maskinlærings-pipelines
“Deep Pipeline Embeddings for AutoML” av Sebastian Pineda Arango og Josif Grabocka (2023) fokuserer på utfordringene med å optimalisere maskinlærings-pipelines i Automated Machine Learning (AutoML). Denne artikkelen introduserer en ny nevrale arkitektur designet for å fange dype interaksjoner mellom pipeline-komponenter. Forfatterne foreslår å lage embedding-representasjoner av pipelines gjennom en unik per-komponent encoder-mekanisme. Disse embeddingene brukes innenfor et Bayesian Optimization-rammeverk for å søke etter optimale pipelines. Artikkelen understreker bruk av meta-læring for å finjustere parametrene til pipeline-embedding-nettverket, og viser til banebrytende resultater i pipeline-optimalisering på tvers av flere datasett. Les mer.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” av Tien-Dung Nguyen m.fl. (2020) tar for seg den tidkrevende evalueringen av maskinlærings-pipelines under AutoML-prosesser. Studien kritiserer tradisjonelle metoder som Bayesian- og genetiske optimaliseringer for deres ineffektivitet. For å motvirke dette presenterer forfatterne AVATAR, en surrogatmodell som effektivt evaluerer pipeline-gyldighet uten kjøring. Denne tilnærmingen akselererer betydelig sammensetningen og optimaliseringen av komplekse pipelines ved å filtrere ut ugyldige tidlig i prosessen. Les mer
“Data Pricing in Machine Learning Pipelines” av Zicun Cong m.fl. (2021) utforsker den avgjørende rollen data har i maskinlærings-pipelines og nødvendigheten av dataprising for å legge til rette for samarbeid mellom flere aktører. Artikkelen gir en oversikt over de nyeste utviklingene innen dataprising i sammenheng med maskinlæring, med fokus på betydningen gjennom ulike stadier av pipelinen. Den gir innsikt i prismodeller for innsamling av treningsdata, samarbeidende modelltrening og leveranse av maskinlæringstjenester, og fremhever dannelsen av et dynamisk økosystem. Les mer
En maskinlærings-pipeline er en automatisert sekvens av steg—fra datainnsamling og forbehandling til modelltrening, evaluering og utrulling—som strømlinjeformer og standardiserer prosessen med å bygge og vedlikeholde maskinlæringsmodeller.
Viktige komponenter inkluderer datainnsamling, datapreprosessering, feature engineering, modellvalg, modelltrening, modellevaluering, modellutrulling og kontinuerlig overvåkning og vedlikehold.
Maskinlærings-pipelines gir modularisering, effektivitet, reproduserbarhet, skalerbarhet, forbedret samarbeid og enklere utrulling av modeller til produksjonsmiljøer.
Bruksområder inkluderer naturlig språkprosessering (NLP), prediktivt vedlikehold i produksjon, finansiell risikovurdering og svindeldeteksjon, samt helsediganostikk.
Utfordringer inkluderer å sikre datakvalitet, håndtere pipeline-kompleksitet, integrasjon med eksisterende systemer og kontroll av kostnader knyttet til databehandlingsressurser og infrastruktur.
Bestill en demo for å oppdage hvordan FlowHunt kan hjelpe deg å automatisere og skalere dine maskinlæringsarbeidsflyter enkelt.
Maskinlæring (ML) er en underkategori av kunstig intelligens (AI) som gjør det mulig for maskiner å lære fra data, identifisere mønstre, lage prediksjoner og fo...
MLflow er en åpen kildekode-plattform designet for å forenkle og administrere livssyklusen til maskinlæring (ML). Den tilbyr verktøy for eksperimentsporing, kod...
Kubeflow er en åpen kildekode-plattform for maskinlæring (ML) på Kubernetes, som forenkler utrulling, administrasjon og skalering av ML-arbeidsflyter. Den tilby...
