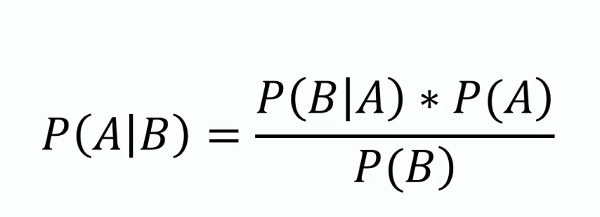
Bayesiske nettverk
Et Bayesisk nettverk (BN) er en sannsynlighetsbasert grafmodell som representerer variabler og deres betingede avhengigheter via en rettet asyklisk graf (DAG). ...
3 min lesing
Bayesian Networks
AI
+3
Naiv Bayes er en enkel, men kraftig familie av klassifiseringsalgoritmer som utnytter Bayes’ teorem, ofte brukt for skalerbare oppgaver som spamdeteksjon og tekstklassifisering.
Naiv Bayes er en familie av enkle, effektive klassifiseringsalgoritmer basert på Bayes’ teorem, med antakelse om betinget uavhengighet mellom egenskaper. Den brukes mye til spamdeteksjon, tekstklassifisering og mer, på grunn av sin enkelhet og skalerbarhet.
Naiv Bayes er en familie av klassifiseringsalgoritmer basert på Bayes’ teorem, som anvender prinsippet om betinget sannsynlighet. Begrepet “naiv” refererer til den forenklende antakelsen om at alle egenskaper i et datasett er betinget uavhengige av hverandre gitt klasseetiketten. Selv om denne antakelsen ofte blir brutt i virkelige data, er Naiv Bayes-klassifisatorer anerkjent for sin enkelhet og effektivitet i ulike applikasjoner, som tekstklassifisering og spamdeteksjon.
Bayes’ teorem
Dette teoremet danner grunnlaget for Naiv Bayes, og gir en metode for å oppdatere sannsynlighetsestimatet for en hypotese etter hvert som mer informasjon blir tilgjengelig. Matematisk uttrykkes det som:
hvor ( P(A|B) ) er den posterior sannsynligheten, ( P(B|A) ) er sannsynligheten, ( P(A) ) er prior sannsynlighet, og ( P(B) ) er evidensen.
Betinget uavhengighet
Den naive antakelsen om at hver egenskap er uavhengig av alle andre egenskaper gitt klasseetiketten. Denne antakelsen forenkler beregningene og gjør at algoritmen skalerer godt til store datasett.
Posterior sannsynlighet
Sannsynligheten for klasseetiketten gitt egenskapsverdiene, beregnet ved bruk av Bayes’ teorem. Dette er den sentrale komponenten i prediksjonene til Naiv Bayes.
Typer av Naiv Bayes-klassifisatorer
Naiv Bayes-klassifisatorer fungerer ved å beregne den posterior sannsynligheten for hver klasse gitt et sett med egenskaper, og velger klassen med høyest posterior sannsynlighet. Prosessen innebærer følgende steg:
Naiv Bayes-klassifisatorer er spesielt effektive i følgende applikasjoner:
Tenk deg en spamfiltreringsapplikasjon som bruker Naiv Bayes. Treningsdataene består av e-poster merket som “spam” eller “ikke spam”. Hver e-post representeres av et sett med egenskaper, slik som tilstedeværelse av bestemte ord. Under trening beregner algoritmen sannsynligheten for hvert ord gitt klasseetiketten. For en ny e-post beregner algoritmen posterior sannsynlighet for “spam” og “ikke spam” og tildeler etiketten med høyest sannsynlighet.
Naiv Bayes-klassifisatorer kan integreres i AI-systemer og chatboter for å forbedre deres evne til naturlig språkbehandling. For eksempel kan de brukes til å oppdage intensjonen bak brukerforespørsler, klassifisere tekster i forhåndsdefinerte kategorier eller filtrere upassende innhold. Denne funksjonaliteten forbedrer kvaliteten og relevansen til AI-drevne løsninger. I tillegg gjør algoritmens effektivitet den godt egnet for sanntidsapplikasjoner, noe som er viktig for AI-automatisering og chatbot-systemer.
Naiv Bayes er en familie av enkle, men kraftige sannsynlighetsbaserte algoritmer, basert på å anvende Bayes’ teorem med sterke uavhengighetsantakelser mellom egenskapene. Den brukes mye til klassifiseringsoppgaver på grunn av sin enkelhet og effektivitet. Her er noen vitenskapelige artikler som diskuterer ulike bruksområder og forbedringer av Naiv Bayes-klassifisatoren:
Improving spam filtering by combining Naive Bayes with simple k-nearest neighbor searches
Forfatter: Daniel Etzold
Publisert: 30. november 2003
Denne artikkelen utforsker bruk av Naiv Bayes for e-postklassifisering, og fremhever hvor enkel den er å implementere og hvor effektiv den er. Studien presenterer empiriske resultater som viser hvordan en kombinasjon av Naiv Bayes og k-nærmeste nabo-søk kan forbedre spamfilterets nøyaktighet. Kombinasjonen ga små forbedringer i nøyaktighet med mange egenskaper og betydelige forbedringer med færre egenskaper. Les artikkelen.
Locally Weighted Naive Bayes
Forfattere: Eibe Frank, Mark Hall, Bernhard Pfahringer
Publisert: 19. oktober 2012
Denne artikkelen tar opp hovedsvakheten til Naiv Bayes, nemlig antakelsen om at attributter er uavhengige. Den introduserer en lokalt vektet versjon av Naiv Bayes som lærer lokale modeller under prediksjon, og dermed slakker på uavhengighetsantakelsen. Eksperimentelle resultater viser at denne tilnærmingen sjelden reduserer nøyaktigheten og ofte forbedrer den betydelig. Metoden får ros for sin konseptuelle og beregningsmessige enkelhet sammenlignet med andre teknikker. Les artikkelen.
Naive Bayes Entrapment Detection for Planetary Rovers
Forfatter: Dicong Qiu
Publisert: 31. januar 2018
I denne studien diskuteres bruken av Naiv Bayes-klassifisatorer for å oppdage fastkjøring hos planet-rovere. Den definerer kriteriene for fastkjøring og viser bruk av Naiv Bayes for å oppdage slike scenarier. Artikkelen beskriver eksperimenter utført med AutoKrawler-rovere, og gir innsikt i effektiviteten til Naiv Bayes for autonome redningsprosedyrer. Les artikkelen.
Naiv Bayes er en familie av klassifiseringsalgoritmer basert på Bayes’ teorem, som antar at alle egenskaper er betinget uavhengige gitt klassetilhørigheten. Den brukes mye til tekstklassifisering, spamfiltrering og sentimentanalyse.
Hovedtypene er Gaussian Naiv Bayes (for kontinuerlige egenskaper), Multinomial Naiv Bayes (for diskrete egenskaper som ordtellinger) og Bernoulli Naiv Bayes (for binære/boolean egenskaper).
Naiv Bayes er enkel å implementere, beregningseffektiv, kan skaleres til store datasett og håndterer høy-dimensjonale data godt.
Hovedbegrensningen er antakelsen om uavhengighet mellom egenskaper, noe som ofte ikke stemmer for data fra virkeligheten. Den kan også tildele nullsannsynlighet til uobserverte egenskaper, men dette kan motvirkes med teknikker som Laplace-utjevning.
Naiv Bayes brukes i AI-systemer og chatboter for intensjonsgjenkjenning, tekstklassifisering, spamfiltrering og sentimentanalyse, noe som forbedrer evnene til naturlig språkbehandling og muliggjør sanntidsbeslutninger.
Smarte chatboter og AI-verktøy samlet på ett sted. Koble intuitive blokker for å gjøre ideene dine om til automatiserte Flows.
Et Bayesisk nettverk (BN) er en sannsynlighetsbasert grafmodell som representerer variabler og deres betingede avhengigheter via en rettet asyklisk graf (DAG). ...
En AI-klassifiserer er en maskinlæringsalgoritme som tildeler klasselapper til inndata, og kategoriserer informasjon i forhåndsdefinerte klasser basert på mønst...
K-nærmeste naboer (KNN) er en ikke-parametrisk, veiledet læringsalgoritme som brukes for klassifisering og regresjon i maskinlæring. Algoritmen predikerer utfal...