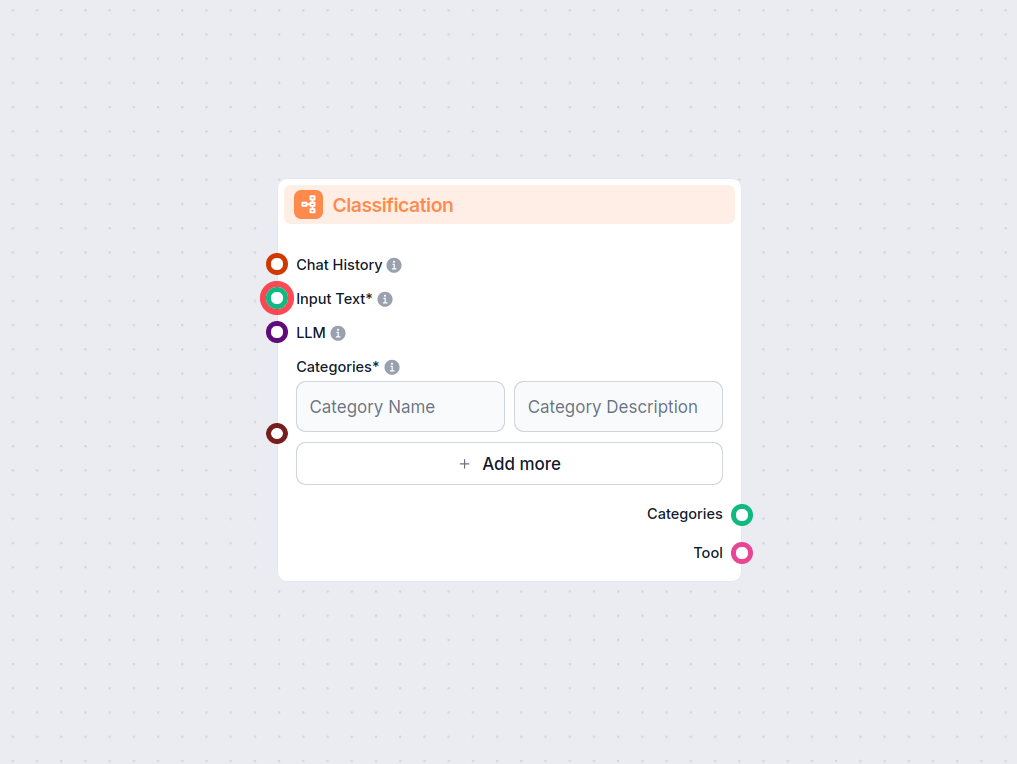
Tekstklassifisering
Tekstklassifisering, også kjent som tekstkategorisering eller tekstmerking, er en kjerneoppgave innen NLP som tildeler forhåndsdefinerte kategorier til tekstdok...
6 min lesing
NLP
Text Classification
+4
Ordklassemerking tilordner grammatiske kategorier som substantiv og verb til ord i tekst, slik at maskiner kan tolke og behandle menneskespråk bedre for NLP-oppgaver.
Ordklassemerking (POS tagging) er en sentral oppgave innen beregningslingvistikk og naturlig språkprosessering som bygger bro mellom menneske-maskin-interaksjon. Oppdag nøkkelaspektene, hvordan det fungerer, og bruksområder i dag! Det innebærer å tilordne hvert ord i en tekst dets tilsvarende ordklasse, basert på definisjon og kontekst i setningen. Hovedmålet er å kategorisere ord i grammatiske kategorier som substantiv, verb, adjektiv, adverb osv., slik at maskiner bedre kan behandle og forstå menneskespråk. Denne oppgaven kalles også grammatisk tagging eller ordklasse-disambiguering, og utgjør ryggraden i ulike avanserte språkanalyser.
Før vi går dypere inn i POS-tagging, er det viktig å forstå noen grunnleggende ordklasser på engelsk:
POS-tagging er avgjørende for å gjøre det mulig for maskiner å tolke og samhandle med menneskespråk nøyaktig. Det danner grunnlaget for ulike NLP-applikasjoner, inkludert:
Vurder setningen:
“The quick brown fox jumps over the lazy dog.”
Etter POS-tagging er hvert ord merket slik:
Denne merkingen gir innsikt i setningens grammatiske struktur og hjelper videre NLP-oppgaver ved å synliggjøre forholdet mellom ordene.
Det finnes flere metoder for ordklassemerking, hver med sine fordeler og utfordringer:
Regelbasert tagging:
Statistisk tagging:
Transformasjonsbasert tagging:
Maskinlæringsbasert tagging:
Hybride metoder:
POS-tagging spiller en sentral rolle i utviklingen av AI-systemer som samhandler med menneskespråk, som chatboter og virtuelle assistenter. Ved å forstå den grammatiske strukturen i brukerens inndata kan AI-systemer gi mer presise svar og forbedre brukeropplevelsen. Innen AI-automatisering hjelper POS-tagging med oppgaver som dokumentklassifisering, sentimentanalyse og innholdsmoderering ved å gi syntaktiske og semantiske innsikter om teksten.
Ordklassemerking (POS-tagging) er en grunnleggende prosess innen naturlig språkprosessering (NLP) hvor hvert ord i en tekst merkes med sin tilsvarende ordklasse, som substantiv, verb, adjektiv osv. Denne prosessen hjelper til med å forstå setningers syntaktiske struktur, noe som er avgjørende for ulike NLP-applikasjoner som tekstanalyse, sentimentanalyse og maskinoversettelse.
Viktige forskningsartikler:
Method for Customizable Automated Tagging
Denne artikkelen av Maharshi R. Pandya og kolleger tar for seg utfordringene med over- og undertagging i tekstdokumenter. Forfatterne foreslår en taggingsmetode ved bruk av IBM Watsons NLU-tjeneste for å generere et universelt sett med tagger anvendelig på store dokumentkorpuser. De demonstrerer metodens effektivitet ved å bruke den på 87 397 dokumenter og oppnår høy taggingsnøyaktighet. Forskningen fremhever viktigheten av effektive taggesystemer for håndtering av store tekstmengder.
Les mer
A Joint Named-Entity Recognizer for Heterogeneous Tag-sets Using a Tag Hierarchy
Genady Beryozkin og hans team utforsker domenetilpasning i navngitt enhetsgjenkjenning med flere heterogent taggede treningssett. De foreslår å bruke en tagghierarki for å lære et nevralt nettverk som tilpasser seg ulike taggsett. Eksperimentene viser forbedret ytelse ved konsolidering av taggsett, og fremhever fordelene ved en hierarkisk tilnærming til tagging.
Les mer
Who Ordered This?: Exploiting Implicit User Tag Order Preferences for Personalized Image Tagging
Amandianeze O. Nwana og Tsuhan Chen undersøker betydningen av taggrekkefølgepreferanser i bildemerking. De foreslår en ny objektiv funksjon som tar hensyn til brukernes foretrukne taggrekkefølger for å forbedre automatiserte bildetaggesystemer. Metoden gir bedre resultat på personlige tagging-oppgaver og understreker innvirkningen av brukeratferd på taggesystemer.
Les mer
Ordklassemerking (POS tagging) er prosessen med å tilordne hvert ord i en tekst dets grammatiske kategori, som substantiv, verb, adjektiv eller adverb, basert på definisjon og kontekst. Det er grunnleggende for NLP-oppgaver som maskinoversettelse og navngitt enhetsgjenkjenning.
POS-tagging gjør det mulig for maskiner å tolke og behandle menneskespråk nøyaktig. Det ligger til grunn for applikasjoner som maskinoversettelse, informasjonsutvinning, tekst-til-tale-konvertering og chatbot-interaksjoner ved å klargjøre setningers grammatiske struktur.
De viktigste metodene inkluderer regelbasert tagging, statistisk tagging med sannsynlighetsmodeller, transformasjonsbasert tagging, metoder basert på maskinlæring og hybride systemer som kombinerer disse teknikkene for høyere nøyaktighet.
Utfordringer inkluderer behandling av tvetydige ord som kan tilhøre flere kategorier, idiomatiske uttrykk, ord som ikke finnes i vokabularet, og tilpasning av modeller til ulike domener eller teksttyper.
Begynn å bygge smartere AI-løsninger ved å bruke avanserte NLP-teknikker som ordklassemerking. Automatiser språkforståelse med FlowHunt.
Tekstklassifisering, også kjent som tekstkategorisering eller tekstmerking, er en kjerneoppgave innen NLP som tildeler forhåndsdefinerte kategorier til tekstdok...
Lås opp automatisert tekstkategorisering i arbeidsflytene dine med Tekstklassifiseringskomponenten for FlowHunt. Klassifiser enkelt innkommet tekst i brukerdefi...
Et token i sammenheng med store språkmodeller (LLM-er) er en sekvens av tegn som modellen konverterer til numeriske representasjoner for effektiv prosessering. ...