
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) er et avansert AI-rammeverk som kombinerer tradisjonelle informasjonshentingssystemer med generative store språkmodeller (L...
4 min lesing
RAG
AI
+4

Spørsmål og svar med RAG forbedrer LLM-er ved å integrere sanntids datainnhenting og naturlig språk-generering for presise, kontekstuelt relevante svar.
Spørsmål og svar med Retrieval-Augmented Generation (RAG) forbedrer språkmodeller ved å integrere sanntids eksterne data for nøyaktige og relevante svar. Det optimaliserer ytelsen i dynamiske fagfelt, og tilbyr forbedret nøyaktighet, dynamisk innhold og økt relevans.
Spørsmål og svar med Retrieval-Augmented Generation (RAG) er en innovativ metode som kombinerer styrkene til informasjonsinnhenting og naturlig språk-generering for å skape menneskelignende tekst fra data, og forbedrer AI, chatboter, rapporter og personaliserte opplevelser. Denne hybride tilnærmingen utvider mulighetene til store språkmodeller (LLM-er) ved å supplere svarene deres med relevant, oppdatert informasjon hentet fra eksterne datakilder. I motsetning til tradisjonelle metoder som kun stoler på forhåndstrente modeller, integrerer RAG dynamisk eksterne data, slik at systemene kan gi mer nøyaktige og kontekstuelt relevante svar, særlig i domener som krever den nyeste informasjonen eller spesialisert kunnskap.
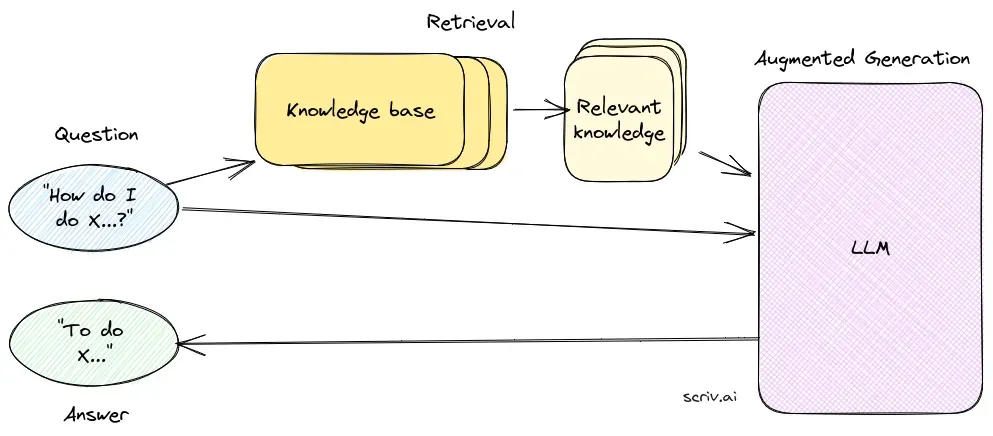
RAG optimerer ytelsen til LLM-er ved å sikre at svarene ikke bare genereres fra et internt datasett, men også informeres av sanntids, autoritative kilder. Denne tilnærmingen er avgjørende for spørsmål-og-svar-oppgaver i dynamiske fagfelt der informasjon stadig utvikles.
Innhentingskomponenten har ansvar for å hente relevant informasjon fra store datasett, vanligvis lagret i en vektordatabase. Denne komponenten benytter semantiske søketeknikker for å identifisere og trekke ut tekstsegmenter eller dokumenter som er svært relevante for brukerens forespørsel.
Genereringskomponenten, vanligvis en LLM som GPT-3 eller BERT, syntetiserer et svar ved å kombinere brukerens opprinnelige forespørsel med den innhentede konteksten. Denne komponenten er avgjørende for å generere sammenhengende og kontekstuelt riktige svar.
Implementering av et RAG-system innebærer flere tekniske steg:
Forskning på Spørsmål og svar med Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) er en metode som forbedrer spørsmål-og-svar-systemer ved å kombinere innhentingsmekanismer med generative modeller. Nyere forskning har undersøkt effektiviteten og optimaliseringen av RAG i ulike sammenhenger.
RAG er en metode som kombinerer informasjonsinnhenting og naturlig språk-generering for å gi presise, oppdaterte svar ved å integrere eksterne datakilder i store språkmodeller.
Et RAG-system består av en innhentingskomponent, som henter relevant informasjon fra vektordatabaser ved hjelp av semantisk søk, og en genereringskomponent, vanligvis en LLM, som lager svar ved å bruke både brukerforespørselen og innhentet kontekst.
RAG forbedrer nøyaktigheten ved å hente kontekstuelt relevant informasjon, støtter dynamiske innholdsoppdateringer fra eksterne kunnskapsbaser, og øker relevansen og kvaliteten på genererte svar.
Vanlige bruksområder inkluderer AI-chatboter, kundesupport, automatisert innholdsproduksjon og utdanningsverktøy som krever nøyaktige, kontekstsensitive og oppdaterte svar.
RAG-systemer kan være ressurskrevende, krever nøye integrasjon for optimal ytelse, og må sikre faktuell nøyaktighet i den innhentede informasjonen for å unngå villedende eller utdaterte svar.
Oppdag hvordan Retrieval-Augmented Generation kan styrke din chatbot og supportløsninger med sanntids, presise svar.
Retrieval Augmented Generation (RAG) er et avansert AI-rammeverk som kombinerer tradisjonelle informasjonshentingssystemer med generative store språkmodeller (L...
Oppdag de viktigste forskjellene mellom Retrieval-Augmented Generation (RAG) og Cache-Augmented Generation (CAG) innen AI. Lær hvordan RAG henter sanntidsinform...
Dokument-omrangering er prosessen med å omorganisere hentede dokumenter basert på hvor relevante de er for en brukers søk, slik at søkeresultater forbedres ved ...

