Transformer
En transformer-modell er en type nevralt nettverk spesielt utviklet for å håndtere sekvensielle data, som tekst, tale eller tidsseriedata. I motsetning til trad...
3 min lesing
Transformer
Neural Networks
+3
Transformatorer er banebrytende nevrale nettverk som utnytter self-attention for parallell databehandling, og driver modeller som BERT og GPT innen NLP, bildebehandling og mer.
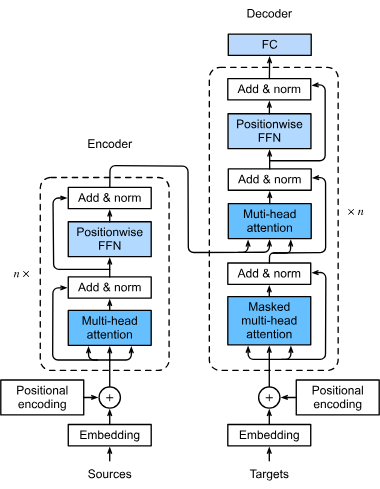
Det første trinnet i en transformer-modells prosesseringslinje innebærer å konvertere ord eller tokens i en inngangssekvens til numeriske vektorer, kjent som embeddinger. Disse embeddingene fanger opp semantiske betydninger og er avgjørende for at modellen skal forstå relasjoner mellom tokens. Denne transformasjonen er essensiell, da den gjør det mulig for modellen å bearbeide tekstdata i matematisk form.
Transformatorer behandler ikke data sekvensielt av natur; derfor brukes posisjonell koding for å tilføre informasjon om posisjonen til hvert token i sekvensen. Dette er viktig for å opprettholde rekkefølgen i sekvensen, noe som er avgjørende for oppgaver som oversettelse der kontekst kan være avhengig av rekkefølgen på ordene.
Multi-head attention-mekanismen er en sofistikert komponent i transformatorer som gjør det mulig for modellen å fokusere på ulike deler av inngangssekvensen samtidig. Ved å beregne flere attention-poeng kan modellen fange opp ulike relasjoner og avhengigheter i dataene, noe som styrker dens evne til å forstå og generere komplekse datamønstre.
Transformatorer følger typisk en encoder-decoder-arkitektur:
Etter attention-mekanismen går dataene gjennom fremovermatete nevrale nettverk, som påfører ikke-lineære transformasjoner på dataene og hjelper modellen å lære komplekse mønstre. Disse nettverkene bearbeider dataene videre for å finpusse resultatet generert av modellen.
Disse teknikkene er integrert for å stabilisere og øke hastigheten på treningsprosessen. Lag-normalisering sikrer at utgangene forblir innenfor et visst område, noe som legger til rette for effektiv modelltrening. Residualforbindelser lar gradienter flyte gjennom nettverkene uten å forsvinne, noe som forbedrer treningen av dype nevrale nettverk.
Transformatorer arbeider på sekvenser av data, som kan være ord i en setning eller annen sekvensiell informasjon. De benytter self-attention for å avgjøre relevansen av hver del av sekvensen i forhold til de andre, slik at modellen kan fokusere på avgjørende elementer som påvirker utgangen.
I self-attention sammenlignes hvert token i sekvensen med alle andre tokens for å beregne attention-poeng. Disse poengene indikerer viktigheten av hvert token i sammenheng med de andre, slik at modellen kan fokusere på de mest relevante delene av sekvensen. Dette er avgjørende for å forstå kontekst og mening i språkopppgaver.
Dette er byggeklossene i en transformer-modell, bestående av self-attention- og fremovermatete lag. Flere blokker stables oppå hverandre for å danne dype læringsmodeller som kan fange opp intrikate mønstre i dataene. Denne modulære utformingen gjør det mulig for transformatorer å skaleres effektivt med oppgavens kompleksitet.
Transformatorer er mer effektive enn RNN-er og CNN-er fordi de kan behandle hele sekvenser samtidig. Denne effektiviteten gjør det mulig å skalere opp til svært store modeller, som GPT-3, som har 175 milliarder parametere. Skalerbarheten til transformatorer gjør dem i stand til å håndtere enorme mengder data effektivt.
Tradisjonelle modeller sliter med langtrekkende avhengigheter på grunn av sin sekvensielle natur. Transformatorer overkommer denne begrensningen gjennom self-attention, som kan ta hensyn til alle deler av sekvensen samtidig. Dette gjør dem spesielt effektive for oppgaver som krever forståelse av kontekst over lange tekstsekvenser.
Selv om de opprinnelig ble utviklet for NLP, har transformatorer blitt tilpasset til ulike applikasjoner, inkludert bildebehandling, proteinfolding og til og med tidsserieprognoser. Denne allsidigheten viser hvor bredt transformatorer kan brukes på tvers av ulike domener.
Transformatorer har betydelig forbedret ytelsen til NLP-oppgaver som oversettelse, oppsummering og sentimentanalyse. Modeller som BERT og GPT er fremtredende eksempler som benytter transformer-arkitektur for å forstå og generere menneskelignende tekst, og setter nye standarder innen NLP.
Innen maskinoversettelse utmerker transformatorer seg ved å forstå konteksten til ord i en setning, noe som gir mer presise oversettelser sammenlignet med tidligere metoder. Deres evne til å behandle hele setninger på en gang gir mer sammenhengende og kontekstuelt korrekte oversettelser.
Transformatorer kan modellere sekvenser av aminosyrer i proteiner, noe som hjelper til med å forutsi proteinstrukturer — avgjørende for legemiddelutvikling og forståelse av biologiske prosesser. Denne anvendelsen understreker potensialet til transformatorer i vitenskapelig forskning.
Ved å tilpasse transformer-arkitekturen er det mulig å forutsi fremtidige verdier i tidsseriedata, som prognoser for strømforbruk, ved å analysere tidligere sekvenser. Dette åpner nye muligheter for transformatorer innen områder som finans og ressursstyring.
BERT-modeller er designet for å forstå konteksten til et ord ved å se på de omkringliggende ordene, noe som gjør dem svært effektive for oppgaver som krever forståelse av ordrelasjoner i en setning. Denne toveis tilnærmingen lar BERT fange opp kontekst mer effektivt enn enveis modeller.
GPT-modeller er autoregressive, og genererer tekst ved å forutsi det neste ordet i en sekvens basert på de foregående ordene. De brukes mye i applikasjoner som tekstfullføring og dialoggenerering, og viser deres evne til å produsere menneskelignende tekst.
Opprinnelig utviklet for NLP, har transformatorer blitt tilpasset for bildebehandlingsoppgaver. Vision transformers behandler bildedata som sekvenser, slik at de kan bruke transformer-teknikker på visuelle innganger. Denne tilpasningen har ført til fremskritt innen bildegenkjenning og -prosessering.
Trening av store transformer-modeller krever betydelige datakraftressurser, ofte med store datasett og kraftig maskinvare som GPU-er. Dette utgjør en utfordring når det gjelder kostnad og tilgjengelighet for mange organisasjoner.
Etter hvert som transformatorer blir mer utbredte, blir temaer som skjevhet i AI-modeller og etisk bruk av AI-generert innhold stadig viktigere. Forskere arbeider med metoder for å redusere disse problemene og sikre ansvarlig AI-utvikling, noe som understreker behovet for etiske rammeverk i AI-forskning.
Transformatorenes allsidighet fortsetter å åpne nye muligheter for forskning og anvendelse — fra å forbedre AI-drevne chatboter til å forbedre dataanalyse innen helsevesen og finans. Fremtiden for transformatorer byr på spennende muligheter for innovasjon på tvers av ulike industrier.
Avslutningsvis representerer transformatorer et betydelig fremskritt innen AI-teknologi, og tilbyr enestående evner til å behandle sekvensielle data. Deres nyskapende arkitektur og effektivitet har satt en ny standard i feltet og løftet AI-applikasjoner til nye høyder. Enten det gjelder språkforståelse, vitenskapelig forskning eller behandling av visuelle data, fortsetter transformatorer å omdefinere hva som er mulig innen kunstig intelligens.
Transformatorer har revolusjonert feltet kunstig intelligens, spesielt innen naturlig språkbehandling og forståelse. Artikkelen “AI Thinking: A framework for rethinking artificial intelligence in practice” av Denis Newman-Griffis (publisert i 2024) utforsker et nytt konseptuelt rammeverk kalt AI Thinking. Dette rammeverket modellerer sentrale beslutninger og hensyn involvert i bruk av AI på tvers av faglige perspektiver, og adresserer ferdigheter i å motivere AI-bruk, formulere AI-metoder og plassere AI i sosiotekniske kontekster. Målet er å bygge bro mellom akademiske disipliner og forme fremtiden for AI i praksis. Les mer.
En annen viktig bidragsyter er “Artificial intelligence and the transformation of higher education institutions” av Evangelos Katsamakas m.fl. (publisert i 2024), som bruker en komplekse systemtilnærming for å kartlegge de kausale tilbakemeldingsmekanismene for AI-transformasjon i høyere utdanningsinstitusjoner (HEI-er). Studien diskuterer kreftene som driver AI-transformasjon og dens innvirkning på verdiskaping, og understreker behovet for at HEI-er tilpasser seg AI-teknologiske fremskritt samtidig som de håndterer akademisk integritet og endringer i arbeidsmarkedet. Les mer.
Innen programvareutvikling undersøker artikkelen “Can Artificial Intelligence Transform DevOps?” av Mamdouh Alenezi og kolleger (publisert i 2022) skjæringspunktet mellom AI og DevOps. Studien fremhever hvordan AI kan forbedre funksjonaliteten til DevOps-prosesser og legge til rette for effektiv programvareleveranse. Den understreker de praktiske implikasjonene for programvareutviklere og virksomheter i å utnytte AI for å transformere DevOps-praksis. Les mer
Transformatorer er en nevralt nettverksarkitektur introdusert i 2017 som bruker self-attention-mekanismer for parallell prosessering av sekvensielle data. De har revolusjonert kunstig intelligens, spesielt innen naturlig språkbehandling og bildebehandling.
I motsetning til RNN-er og CNN-er, behandler transformatorer alle elementer i en sekvens samtidig ved bruk av self-attention, noe som gir høyere effektivitet, skalerbarhet og evne til å fange opp langtrekkende avhengigheter.
Transformatorer brukes mye i NLP-oppgaver som oversettelse, oppsummering og sentimentanalyse, samt innen bildebehandling, prediksjon av proteinstruktur og tidsserieprognoser.
Kjente transformator-modeller inkluderer BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) og Vision Transformers for bildebehandling.
Transformatorer krever betydelige datakraftressurser for trening og implementering. De reiser også etiske spørsmål, som potensiell skjevhet i AI-modeller og ansvarlig bruk av generert AI-innhold.
Smarte chatboter og AI-verktøy samlet på ett sted. Koble sammen intuitive blokker for å gjøre ideene dine om til automatiserte Flows.
En transformer-modell er en type nevralt nettverk spesielt utviklet for å håndtere sekvensielle data, som tekst, tale eller tidsseriedata. I motsetning til trad...
En Generativ Forhåndstrent Transformator (GPT) er en KI-modell som bruker dyp læring for å produsere tekst som ligner menneskelig skriving. Basert på transforme...
Tekstgenerering med store språkmodeller (LLMs) innebærer avansert bruk av maskinlæringsmodeller for å produsere menneskelignende tekst fra forespørsler. Utforsk...