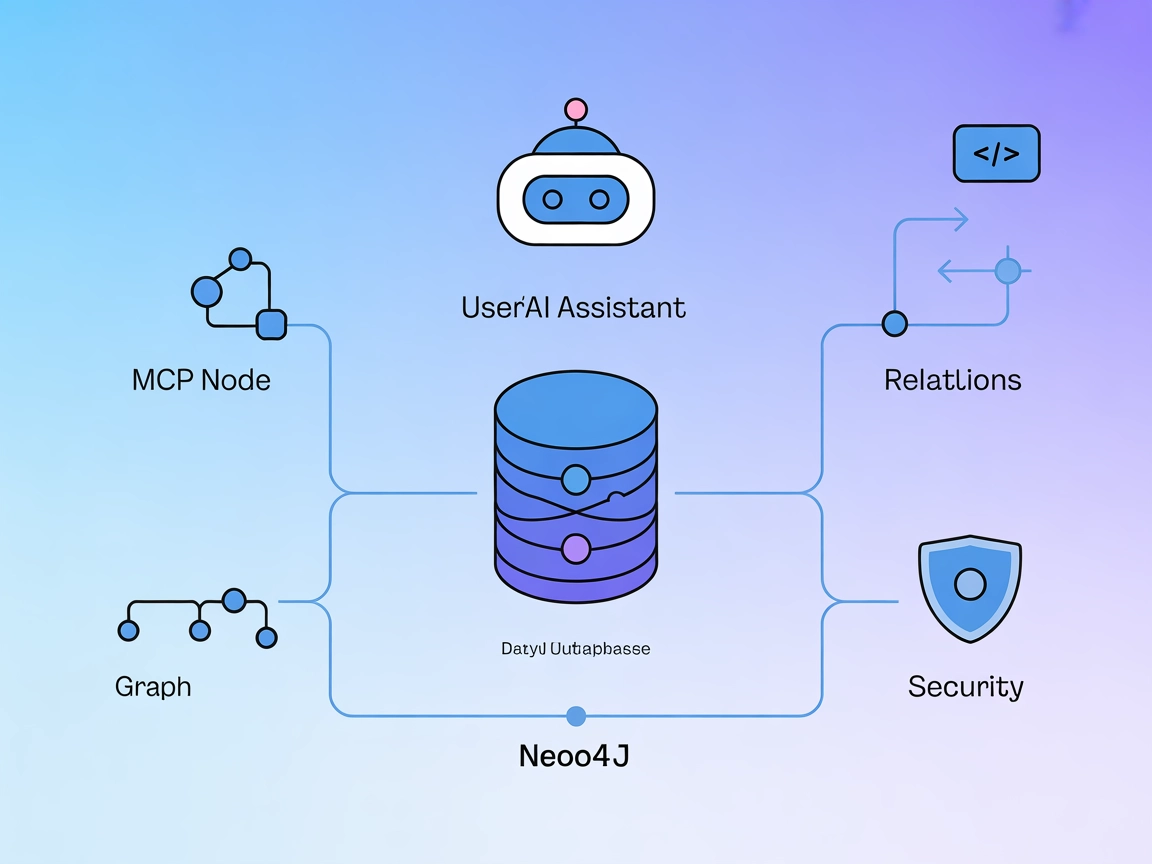
Neo4j MCP Server-integrasjon
Neo4j MCP Server fungerer som bro mellom AI-assistenter og Neo4j grafdatabase, og muliggjør sikre, naturlig språk-drevne grafoperasjoner, Cypher-spørringer og a...
4 min lesing
AI
Graph Database
+5
Neo4j MCP Server fungerer som bro mellom AI-assistenter og Neo4j grafdatabase, og muliggjør sikre, naturlig språk-drevne grafoperasjoner, Cypher-spørringer og a...
NASA MCP-serveren gir en samlet grensesnitt for AI-modeller og utviklere til å få tilgang til over 20 NASA-datakilder. Den standardiserer innhenting, behandling...
Data Exploration MCP-serveren kobler AI-assistenter til eksterne datasett for interaktiv analyse. Den gir brukere mulighet til å utforske CSV- og Kaggle-dataset...
MCP Code Executor MCP Server gjør det mulig for FlowHunt og andre LLM-drevne verktøy å kjøre Python-kode sikkert i isolerte miljøer, håndtere avhengigheter og d...
Reexpress MCP Server gir statistisk verifisering til LLM-arbeidsflyter. Ved å bruke Similarity-Distance-Magnitude (SDM) estimatoren leverer den robuste tillitse...
Databricks Genie MCP-serveren gjør det mulig for store språkmodeller å samhandle med Databricks-miljøer via Genie API-et, og støtter samtalebasert datautforskni...
JupyterMCP muliggjør sømløs integrasjon av Jupyter Notebook (6.x) med AI-assistenter gjennom Model Context Protocol. Automatiser kodekjøring, administrer celler...
En AI Data Analyst samordner tradisjonelle dataanalyseferdigheter med kunstig intelligens (KI) og maskinlæring (ML) for å hente ut innsikter, forutsi trender og...
Anaconda er en omfattende, åpen kildekode-distribusjon av Python og R, designet for å forenkle pakkehåndtering og distribusjon for vitenskapelig databehandling,...
Arealet under kurven (AUC) er en grunnleggende metrikk i maskinlæring som brukes til å evaluere ytelsen til binære klassifiseringsmodeller. Den kvantifiserer mo...
Et beslutningstre er et kraftig og intuitivt verktøy for beslutningstaking og prediktiv analyse, brukt både i klassifisering og regresjonsoppgaver. Den treligne...
BigML er en maskinlæringsplattform designet for å forenkle opprettelse og distribusjon av prediktive modeller. Siden oppstarten i 2011 har deres mål vært å gjør...
Datautvinning er en sofistikert prosess for å analysere store mengder rådata for å avdekke mønstre, sammenhenger og innsikter som kan informere forretningsstrat...
Datavask er den avgjørende prosessen med å oppdage og rette feil eller inkonsistenser i data for å forbedre kvaliteten, og sikre nøyaktighet, konsistens og påli...
Dimensjonsreduksjon er en sentral teknikk innen databehandling og maskinlæring, hvor antallet inputvariabler i et datasett reduseres samtidig som essensiell inf...
Utforsk hvordan funksjonsutvikling og -ekstraksjon forbedrer ytelsen til AI-modeller ved å forvandle rådata til verdifulle innsikter. Oppdag nøkkelteknikker som...
Google Colaboratory (Google Colab) er en skybasert Jupyter-notebook-plattform fra Google, som gjør det mulig for brukere å skrive og kjøre Python-kode i nettles...
Gradient Boosting er en kraftig ensemble-teknikk innen maskinlæring for regresjon og klassifisering. Den bygger modeller sekvensielt, vanligvis med beslutningst...
Jupyter Notebook er en åpen kildekode nettapplikasjon som gjør det mulig for brukere å opprette og dele dokumenter med levende kode, ligninger, visualiseringer ...
Justert R-kvadrat er et statistisk mål som brukes for å evaluere hvor godt en regresjonsmodell passer dataene, ved å ta hensyn til antall prediktorer for å unng...
K-Means-klynging er en populær usupervisert maskinlæringsalgoritme for å dele datasett inn i et forhåndsdefinert antall distinkte, ikke-overlappende klynger ved...
K-nærmeste naboer (KNN) er en ikke-parametrisk, veiledet læringsalgoritme som brukes for klassifisering og regresjon i maskinlæring. Algoritmen predikerer utfal...
Kaggle er et nettbasert fellesskap og plattform for dataforskere og maskinlæringsingeniører til å samarbeide, lære, konkurrere og dele innsikt. Oppkjøpt av Goog...
Kausal inferens er en metodisk tilnærming som brukes for å fastslå årsak-og-virkning-forhold mellom variabler, og er avgjørende i vitenskapen for å forstå kausa...
En AI-klassifiserer er en maskinlæringsalgoritme som tildeler klasselapper til inndata, og kategoriserer informasjon i forhåndsdefinerte klasser basert på mønst...
Lineær regresjon er en grunnleggende analytisk teknikk innen statistikk og maskinlæring, som modellerer forholdet mellom avhengige og uavhengige variabler. Kjen...
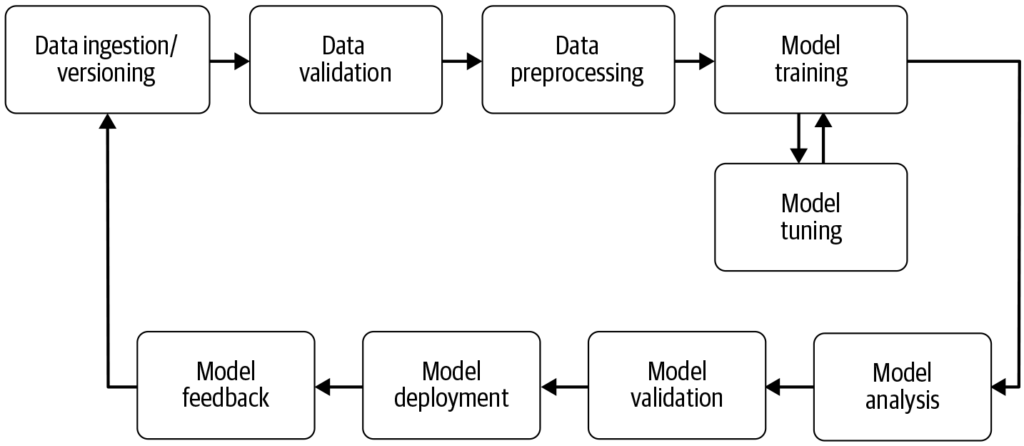
En maskinlærings-pipeline er en automatisert arbeidsflyt som strømlinjeformer og standardiserer utvikling, trening, evaluering og utrulling av maskinlæringsmode...
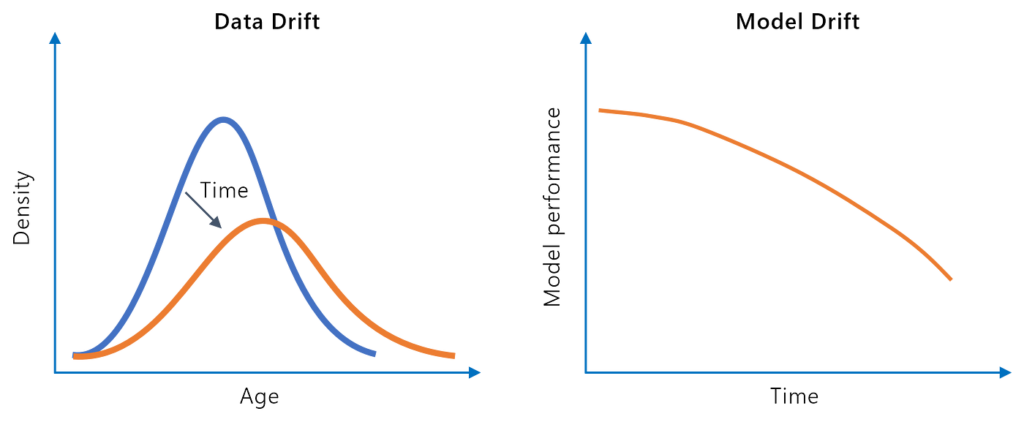
Modeldrift, eller modellforringelse, refererer til nedgangen i en maskinlæringsmodells prediktive ytelse over tid på grunn av endringer i det virkelige miljøet....
Modellkjeding er en maskinlæringsteknikk der flere modeller er koblet sammen sekvensielt, med hver modells utdata som inngang til neste modell. Denne tilnærming...
NumPy er et åpen kildekode Python-bibliotek som er avgjørende for numerisk databehandling, og tilbyr effektive array-operasjoner og matematiske funksjoner. Det ...
Pandas er et åpen kildekode-bibliotek for datamanipulering og analyse for Python, kjent for sin allsidighet, robuste datastrukturer og brukervennlighet i håndte...
Prediktiv modellering er en sofistikert prosess innen datavitenskap og statistikk som forutsier fremtidige utfall ved å analysere mønstre i historiske data. Den...
Scikit-learn er et kraftig, åpen kildekode maskinlæringsbibliotek for Python, som tilbyr enkle og effektive verktøy for prediktiv dataanalyse. Bredt brukt av da...
Semi-supervisert læring (SSL) er en maskinlæringsteknikk som utnytter både merkede og umerkede data for å trene modeller, noe som gjør det ideelt når det er upr...
Utforsk skjevhet i KI: forstå dens kilder, påvirkning på maskinlæring, eksempler fra virkeligheten, og strategier for å motvirke skjevhet for å bygge rettferdig...