input var
Szablon promptu używany do wydobycia nazwy języka docelowego ze wszystkich zmiennych wejściowych.
Get the name of the destination language from following variables:
{all_input_variables}
Ten przepływ pracy usprawnia tłumaczenie plików markdown HUGO na języki docelowe przy zachowaniu struktury pliku i formatowania. Wykorzystując modele językowe AI, zapewnia dokładne tłumaczenia treści, zachowuje integralność front matter TOML i stosuje najlepsze praktyki tłumaczeniowe dla generatorów statycznych stron.
Przepływy
Poniżej znajduje się pełna lista wszystkich promptów wykorzystanych w tym przepływie do osiągnięcia jego funkcjonalności. Prompty to instrukcje przekazywane modelowi AI w celu generowania odpowiedzi lub wykonywania działań. Kierują one AI w zrozumieniu intencji użytkownika i generowaniu odpowiednich wyników.
Szablon promptu używany do wydobycia nazwy języka docelowego ze wszystkich zmiennych wejściowych.
Get the name of the destination language from following variables:
{all_input_variables}
Szablon promptu do tłumaczenia plików HUGO markdown, obejmujący ograniczenia i przykładowe formatowanie.
You are professional translator translating HUGO markdown file to destination language, which is defined in input variables:
{all_input_variables}
-- TRANSLATION RESTRICTIONS --
{context}
-- END RESTRICTIONS --
Input file is HUGO file with Front matter section formatted with toml language (translated file should start with toml, than contains variables in toml format ), than file continue with markdown text
Keep the same formatting and structure as original input file, make sure all control characters are used in the same form as in original input.
Don't translate text, which are part of HTML tags or field names in the front matter section - translate just field values.
In the translation properly handle quotes
--
--EXAMPLE of file structure START:
title = "any title"
any other markdown text ...
-- EXAMPLE END
--
RETURN JUST TRANSLATED FILE, NOTHING ELSE!
INPUT FILE TO TRANSLATE:
{input}
This is a final line added for robust parsing.
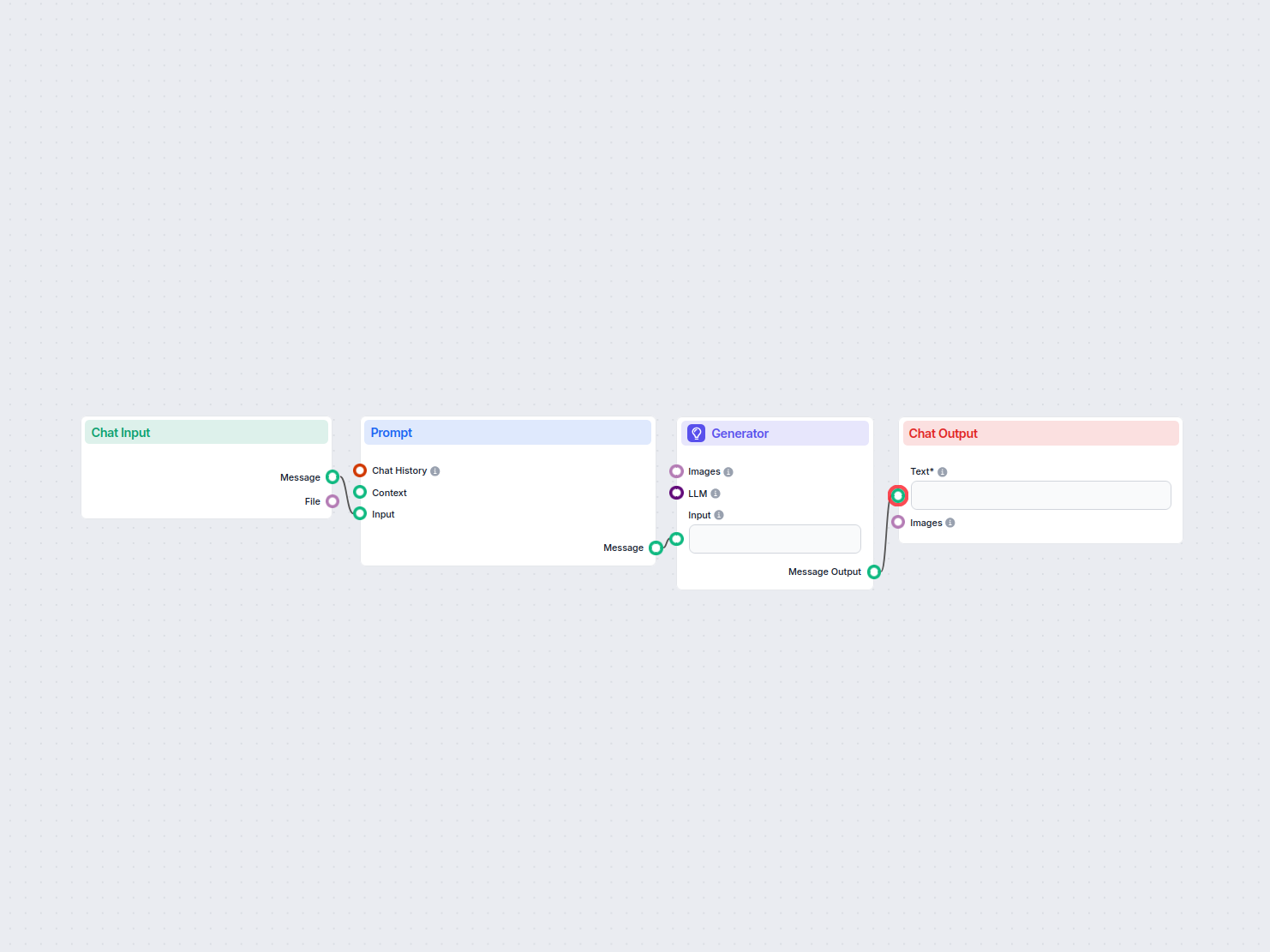
Poniżej znajduje się pełna lista wszystkich komponentów wykorzystanych w tym przepływie do osiągnięcia jego funkcjonalności. Komponenty są podstawowymi elementami każdego przepływu AI. Pozwalają tworzyć złożone interakcje i automatyzować zadania poprzez łączenie różnych funkcjonalności. Każdy komponent służy określonemu celowi, takiemu jak obsługa danych wejściowych użytkownika, przetwarzanie danych lub integracja z zewnętrznymi usługami.
Komponent Chat Input w FlowHunt inicjuje interakcje z użytkownikiem, przechwytując wiadomości z Playground. Służy jako punkt początkowy dla przepływów, umożliwiając przetwarzanie zarówno tekstowych, jak i plikowych wejść.
Dowiedz się, jak komponent Prompt w FlowHunt pozwala definiować rolę i zachowanie Twojego bota AI, zapewniając trafne i spersonalizowane odpowiedzi. Dostosuj prompty i szablony dla skutecznych, kontekstowych przepływów czatbota.
FlowHunt obsługuje dziesiątki modeli generowania tekstu, w tym modele OpenAI. Oto jak używać ChatGPT w swoich narzędziach AI i chatbotach.
Poznaj komponent Generator w FlowHunt — potężne generowanie tekstu oparte na AI z wykorzystaniem wybranego modelu LLM. Bez wysiłku twórz dynamiczne odpowiedzi chatbotów, łącząc prompty, opcjonalne instrukcje systemowe, a nawet obrazy jako wejście, czyniąc Generator kluczowym narzędziem do budowy inteligentnych, konwersacyjnych przepływów pracy.
Wyszukiwarka Dokumentów FlowHunt zwiększa dokładność AI, łącząc modele generatywne z Twoimi aktualnymi dokumentami i adresami URL, zapewniając wiarygodne i trafne odpowiedzi dzięki Retrieval-Augmented Generation (RAG).
Odkryj komponent Wynik czatu w FlowHunt—finalizuj odpowiedzi chatbota za pomocą elastycznych, wieloczęściowych wyjść. Niezbędny do płynnego kończenia przepływów i tworzenia zaawansowanych, interaktywnych chatbotów AI.
Komponent Notatka w FlowHunt pozwala dodawać komentarze i dokumentację bezpośrednio do Twojego workflow. Użyj go, aby wyjaśnić, opisać lub przekazać instrukcje w swoim przepływie, dzięki czemu złożone automatyzacje będą łatwiejsze do zrozumienia i utrzymania.
Opis przepływu
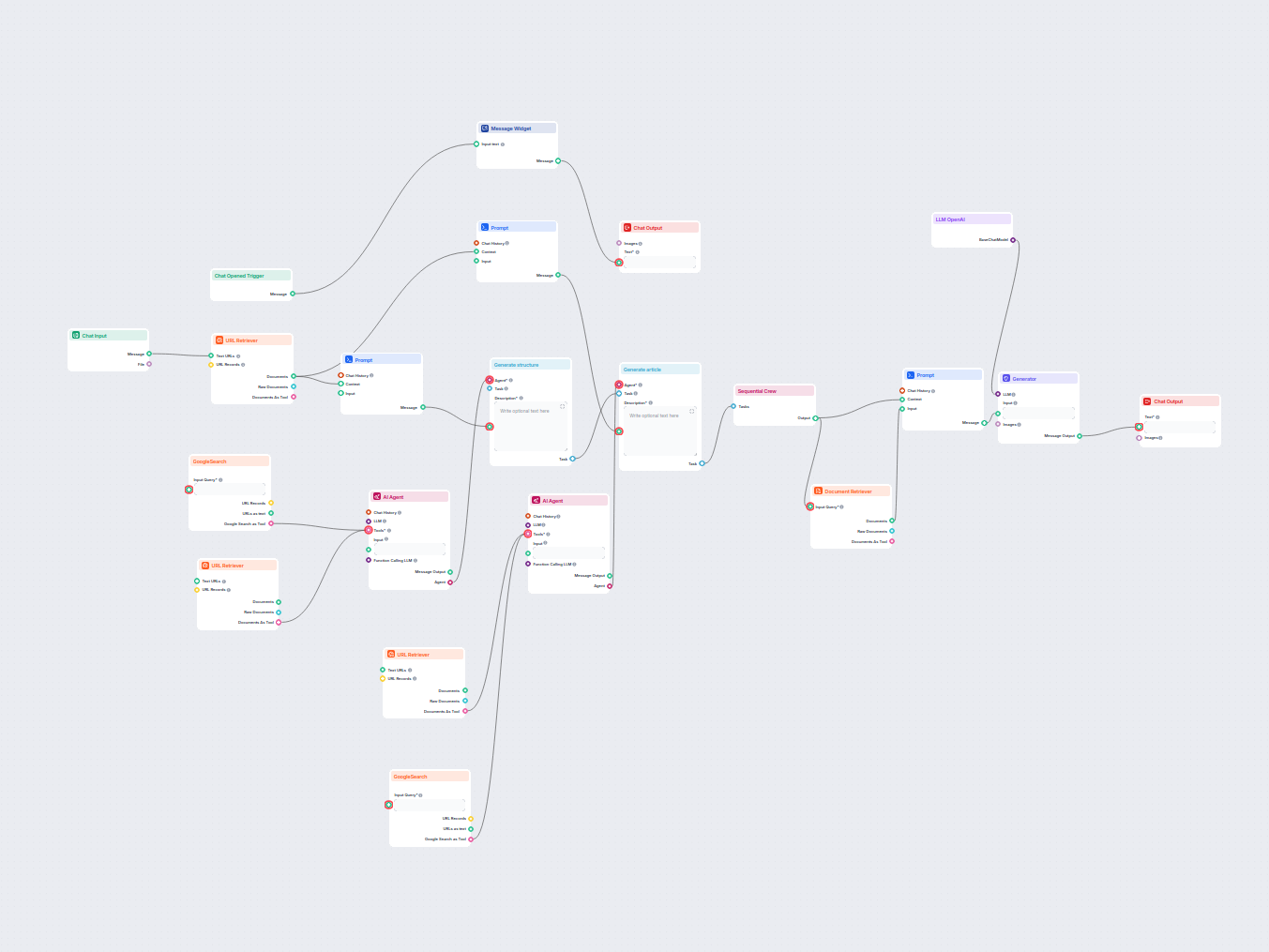
Ten przepływ pracy został zaprojektowany do automatyzacji tłumaczenia plików markdown używanych w projektach HUGO, ze szczególnym uwzględnieniem zachowania struktury pliku i formatowania. Przepływ gwarantuje, że tłumaczona jest tylko odpowiednia treść tekstowa, a elementy techniczne, takie jak front matter, struktura markdown i znaki sterujące, pozostają nienaruszone. Jest to szczególnie przydatne dla zespołów zarządzających wielojęzycznymi statycznymi stronami internetowymi budowanymi w HUGO i chcących skalować lokalizację treści przy zachowaniu wysokiej jakości i spójności.
Przepływ składa się z kilku powiązanych ze sobą komponentów. Oto krok po kroku:
| Krok | Komponent | Funkcja |
|---|---|---|
| 1 | Chat Input | Przyjmuje plik markdown do przetłumaczenia oraz wymagane zmienne (np. język docelowy). |
| 2 | Prompt Template (input var) | Wydobywa nazwę języka docelowego ze zmiennych wejściowych do dalszego użycia. |
| 3 | LLM OpenAI (nano) | Wykorzystuje lekki model GPT-4 do przetwarzania promptów. |
| 4 | Generator (get language name) | Generuje nazwę języka docelowego z dostarczonych zmiennych. |
| 5 | Document Retriever (GetBestTranslation) | Wyszukuje najlepsze istniejące tłumaczenia lub kontekst z wewnętrznych/źródłowych dokumentów. |
| 6 | Prompt Template (Prompt) | Tworzy szczegółowy prompt instruujący LLM, jak tłumaczyć, wraz z ograniczeniami i przykładami. |
| 7 | LLM OpenAI (full) | Wykorzystuje pełny model GPT-4 (z dużym kontekstem) do wykonania tłumaczenia. |
| 8 | Generator | Realizuje tłumaczenie używając powyższego promptu i modelu. |
| 9 | Chat Output | Wyświetla przetłumaczony plik markdown w interfejsie wyjściowym. |
+ + + oraz elementy markdown/HTML są zachowywane zgodnie z wymaganiami HUGO i TOML.Podsumowując, ten przepływ zapewnia kompleksowe, niezawodne i skalowalne rozwiązanie do tłumaczenia plików markdown HUGO, czyniąc go niezwykle wartościowym dla organizacji zarządzających wielojęzycznymi statycznymi stronami lub projektami dokumentacyjnymi.
Pomagamy firmom takim jak Twoja rozwijać inteligentne chatboty, serwery MCP, narzędzia AI lub inne rodzaje automatyzacji AI, aby zastąpić człowieka w powtarzalnych zadaniach w Twojej organizacji.
Tłumacz treści internetowych między językami z zachowaniem struktury HTML, korzystając z AI i wtyczki UrlsLab. Adresy e-mail oraz URL-e pozostają niezmienione, ...
Przekształć dokumentację techniczną z podanego adresu URL w atrakcyjny, zoptymalizowany pod SEO artykuł na swoją stronę internetową. Ten przepływ analizuje najl...
Automatycznie optymalizuj nagłówki i tytuł artykułu pod wybrane słowo kluczowe lub klaster słów kluczowych, aby poprawić wyniki SEO. Ten workflow analizuje Twój...