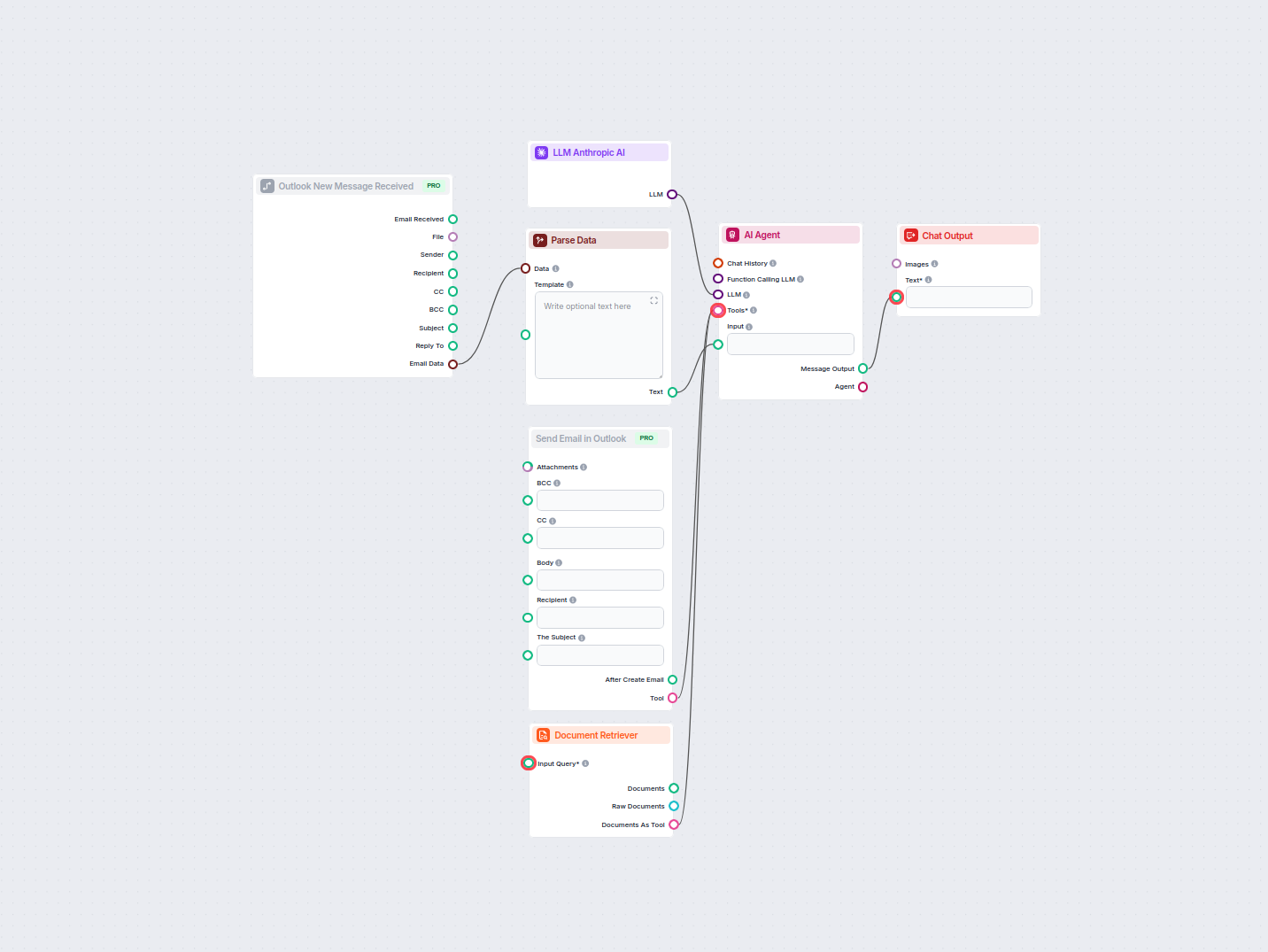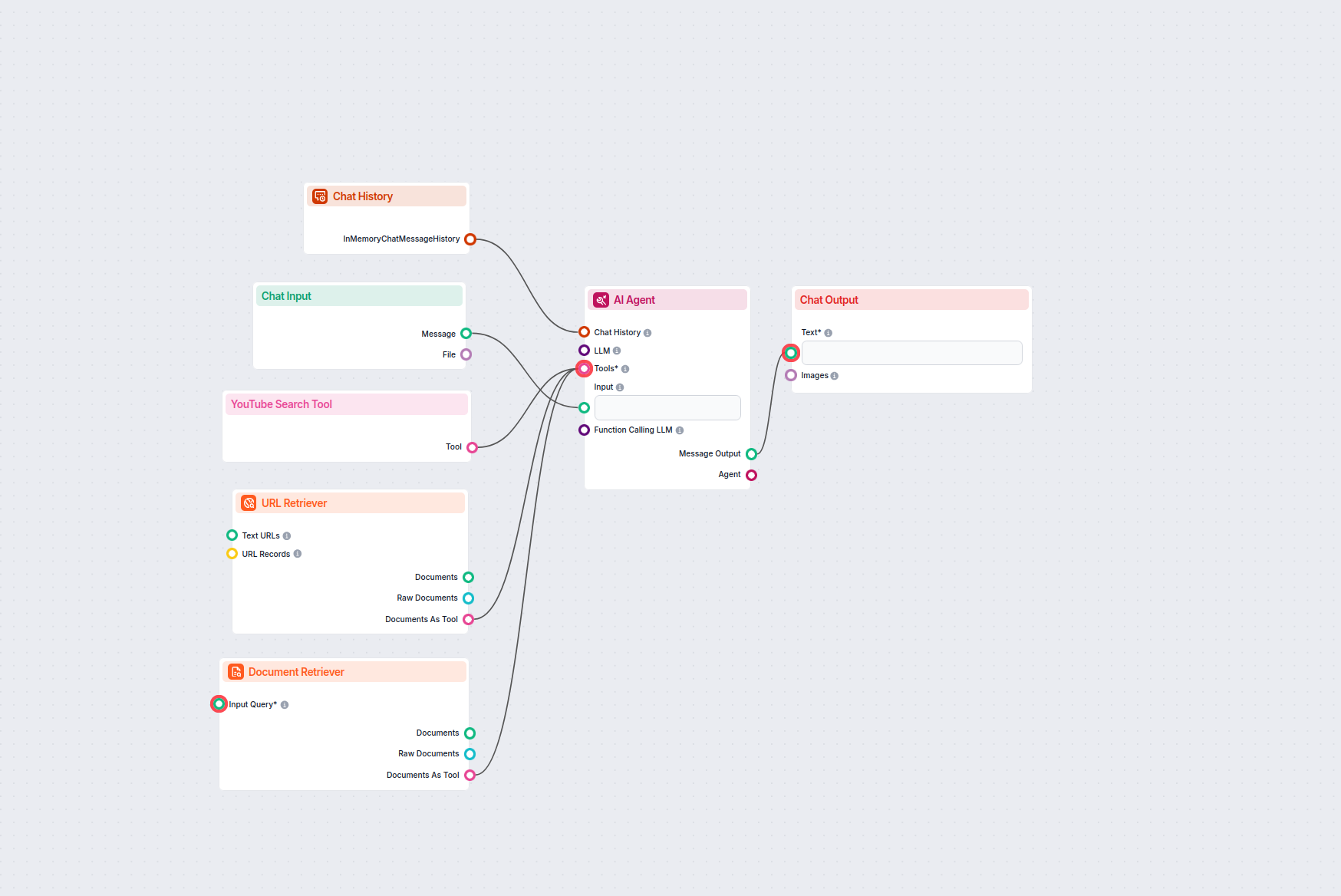
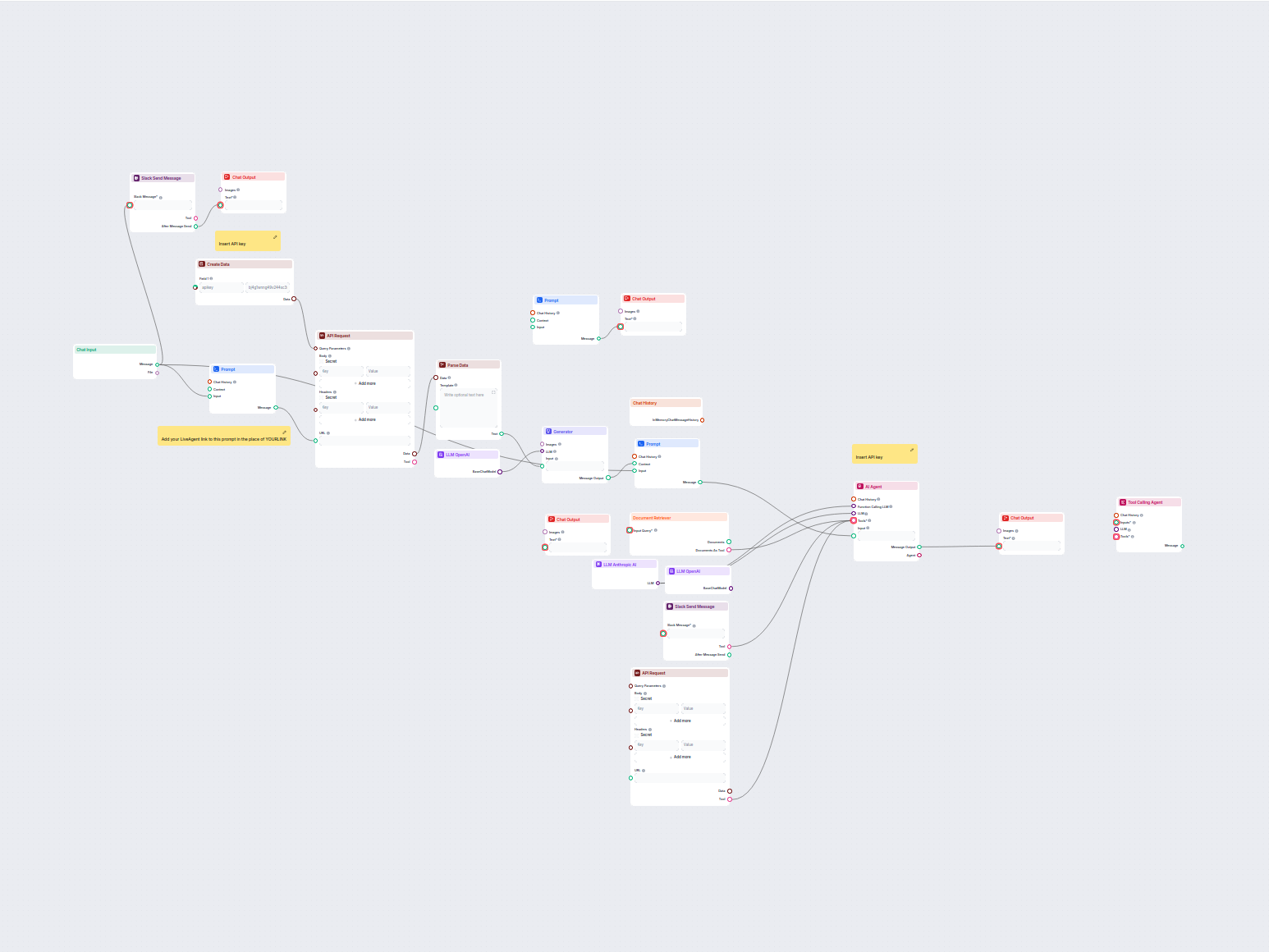
Agent AI do obsługi klienta dla LiveAgent
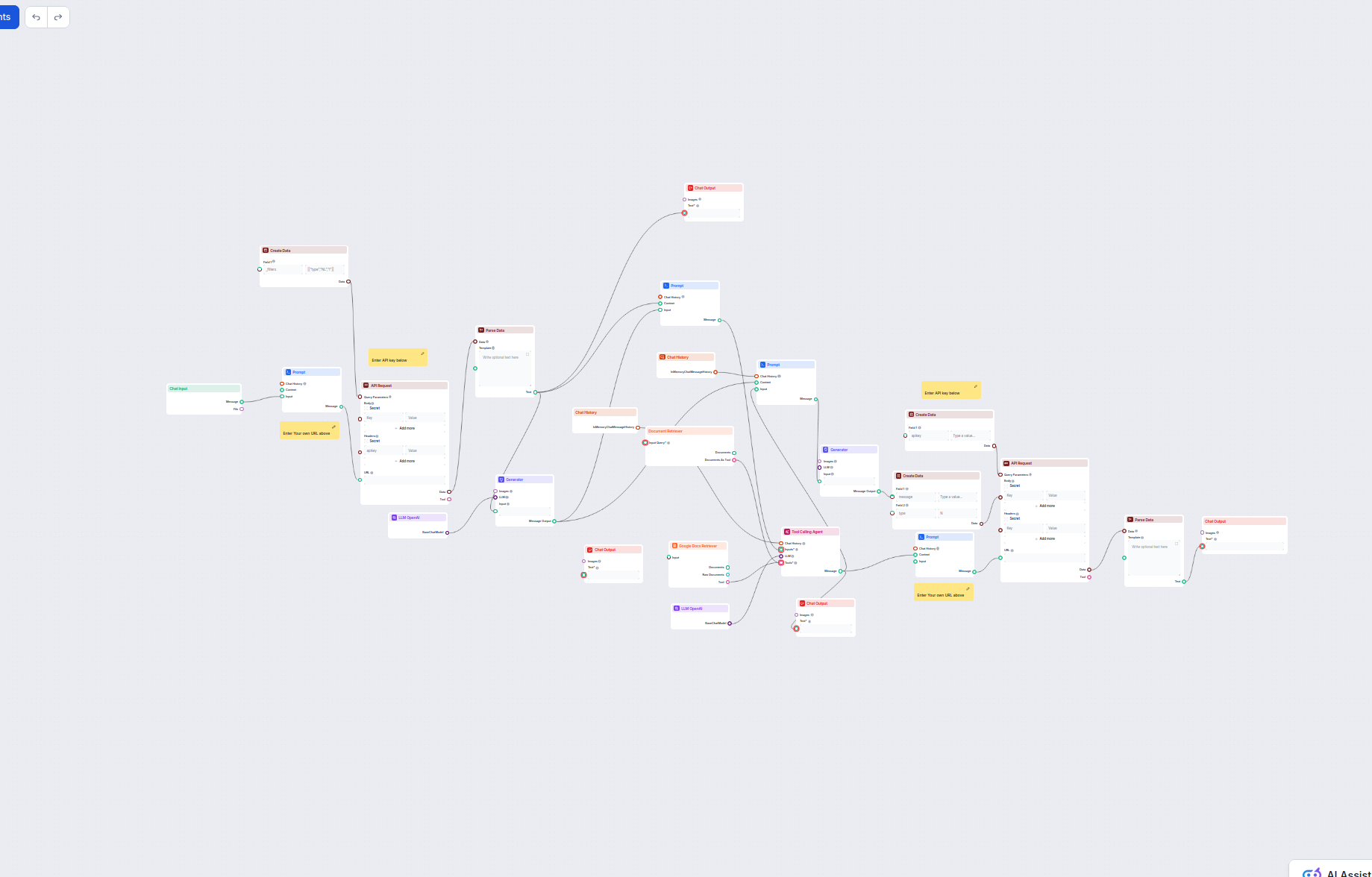
Ten workflow automatyzuje obsługę klienta w Twojej firmie poprzez integrację rozmów z LiveAgent, wydobywanie istotnych danych z konwersacji, generowanie odpowie...
4 min czytania
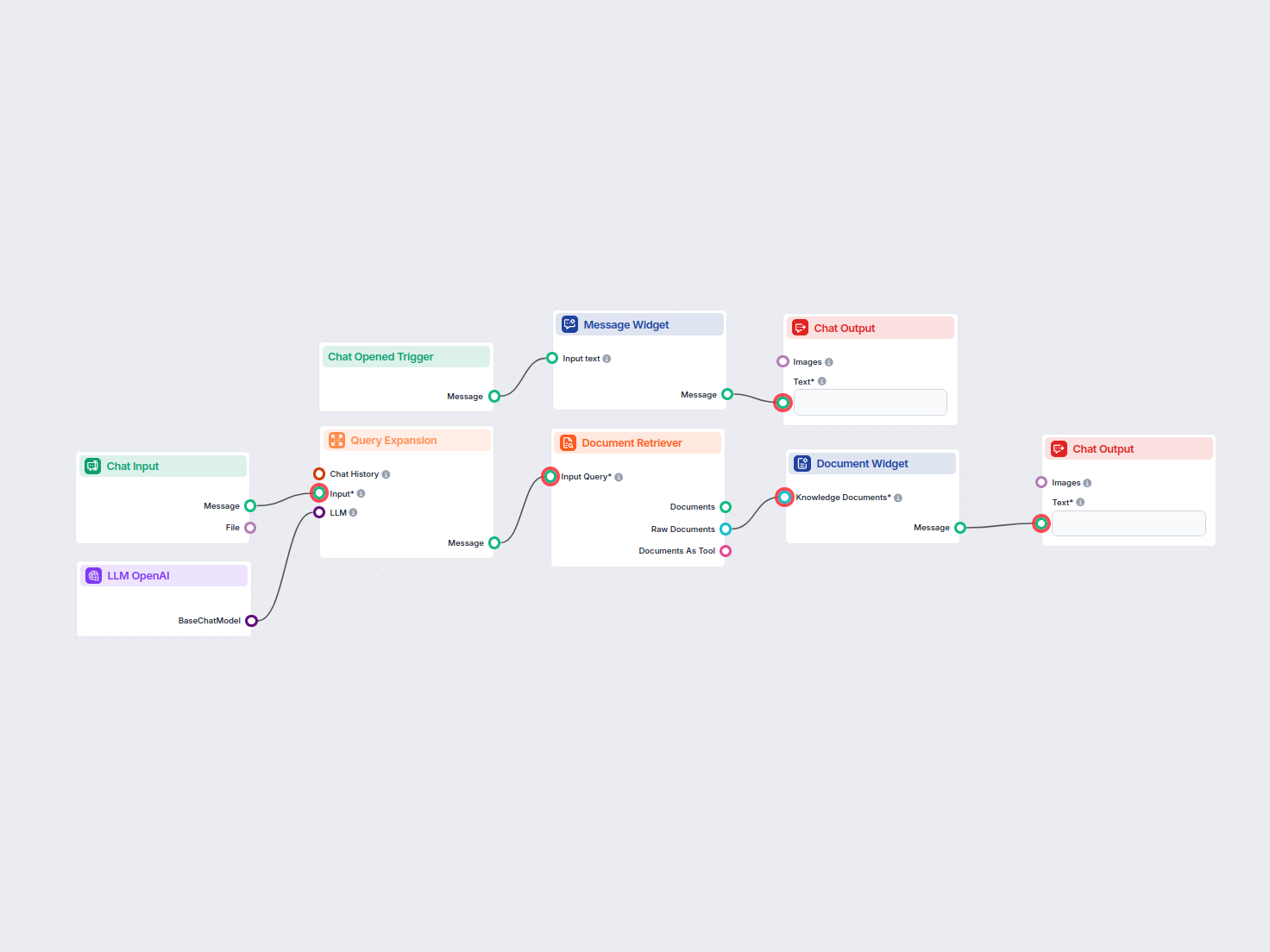
Wyszukiwarka Dokumentów łączy modele AI z wybranymi przez Ciebie dokumentami i adresami URL, umożliwiając precyzyjne, aktualne i trafne odpowiedzi AI dla Twojego konkretnego zastosowania.
Opis komponentu
The most significant setback of large language models is their tendency to present vague, outdated, or downright false information. To ensure the answers are always up to date and relevant to your use case, generative models need to be pointed to the right knowledge sources.
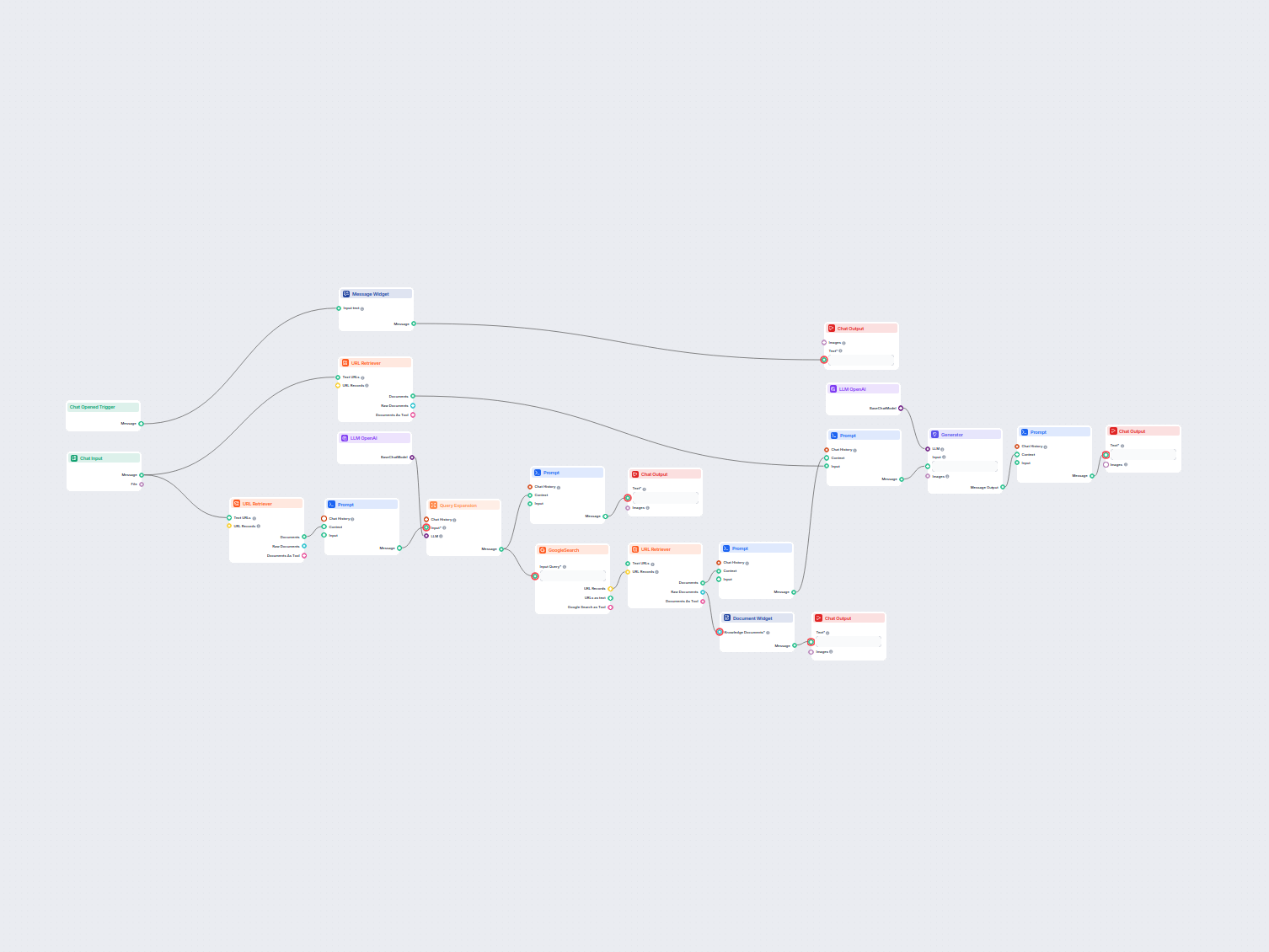
This approach, called the Retrieval-Augmented Generation (RAG), supplies generative models with your own knowledge sources. The retriever components, including the Document Retriever, allow you to use this method.
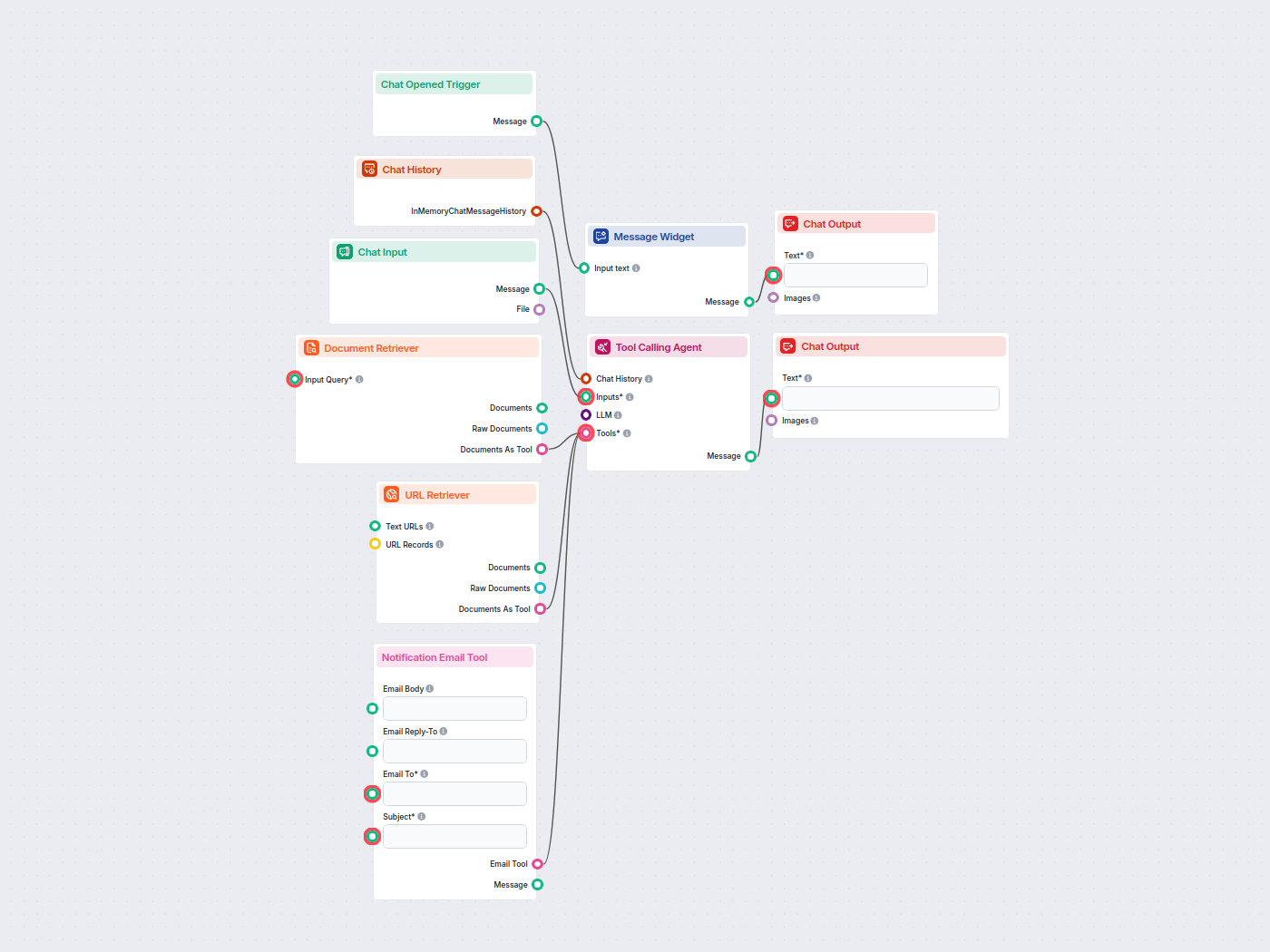
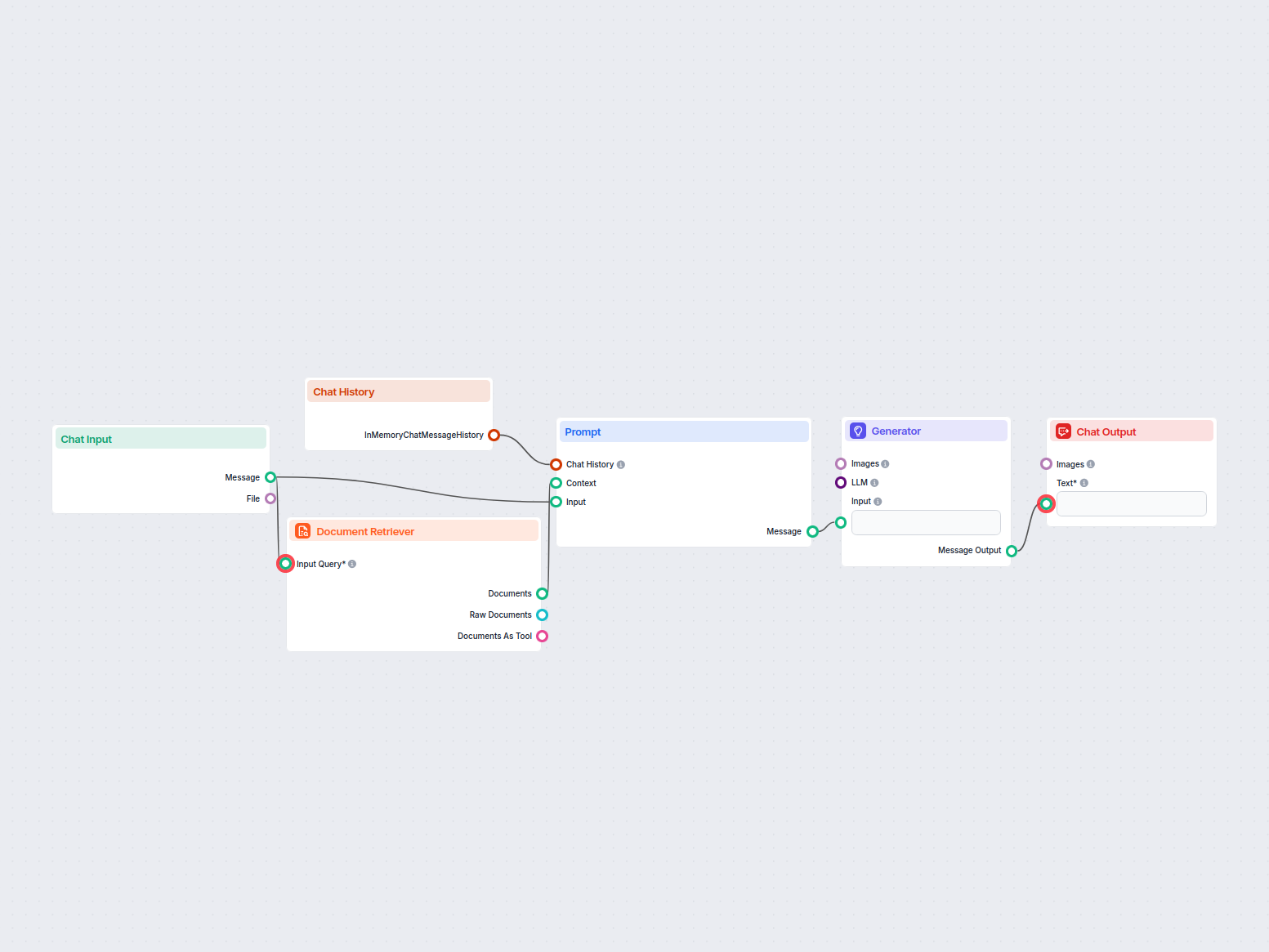
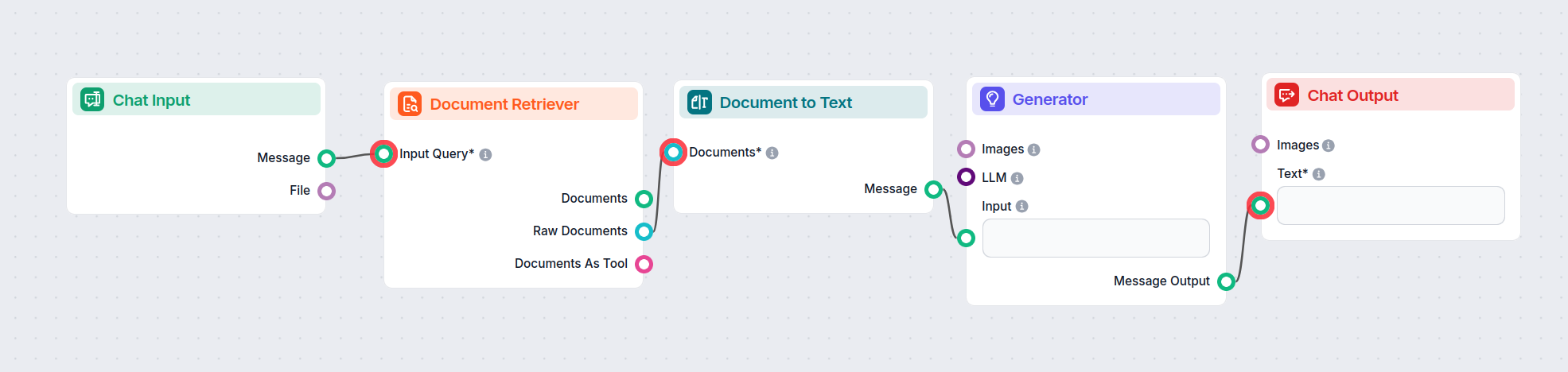
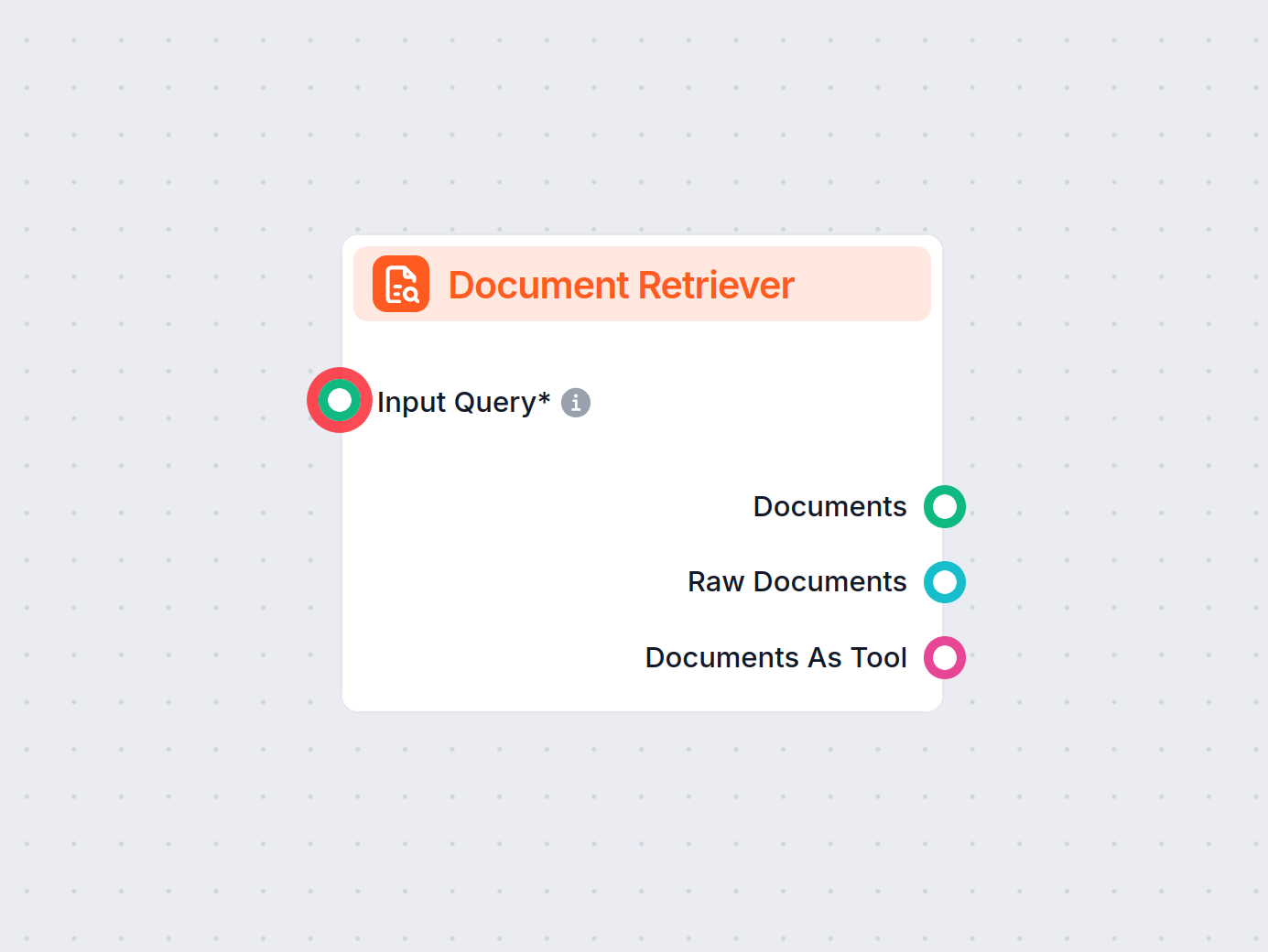
This component allows the chatbot to retrieve knowledge from your own sources, ensuring that the information is relevant, reliable, and up-to-date. This information comes directly from the sources you specified in the Documents and Schedules. The role of this component is to control the retrieval.
Specifies the query that’s used to look up relevant information. It can either be linked from a component or inputted manually. In most cases, your input query will be the Chat Input.
This setting limits the amount of documents the flow should retrieve from, making sure the results remain relevant and don’t take too long to generate.
This optional setting lets you limit the retrieval to one of the categories you’ve created in the Documents screen of Knowledge Sources.
Lets you limit the retrieval to one of the Schedules you’ve specified in the Schedules screen of Knowledge Sources.
The sources in your knowledge database will match the query to varying degrees. AI will rank these by relevance from 0 to 1. This setting lets you control how well the output must match the query.
The exact threshold depends on your use case, but generally, 0.7-0.8 is recommended for highly relevant answers from a reasonable amount of sources.
Imagine you set the threshold to 0.6 and have the following articles:
Only the articles with a relevance score of over 0.6 will make it into the output, that is, only A, B, and D.
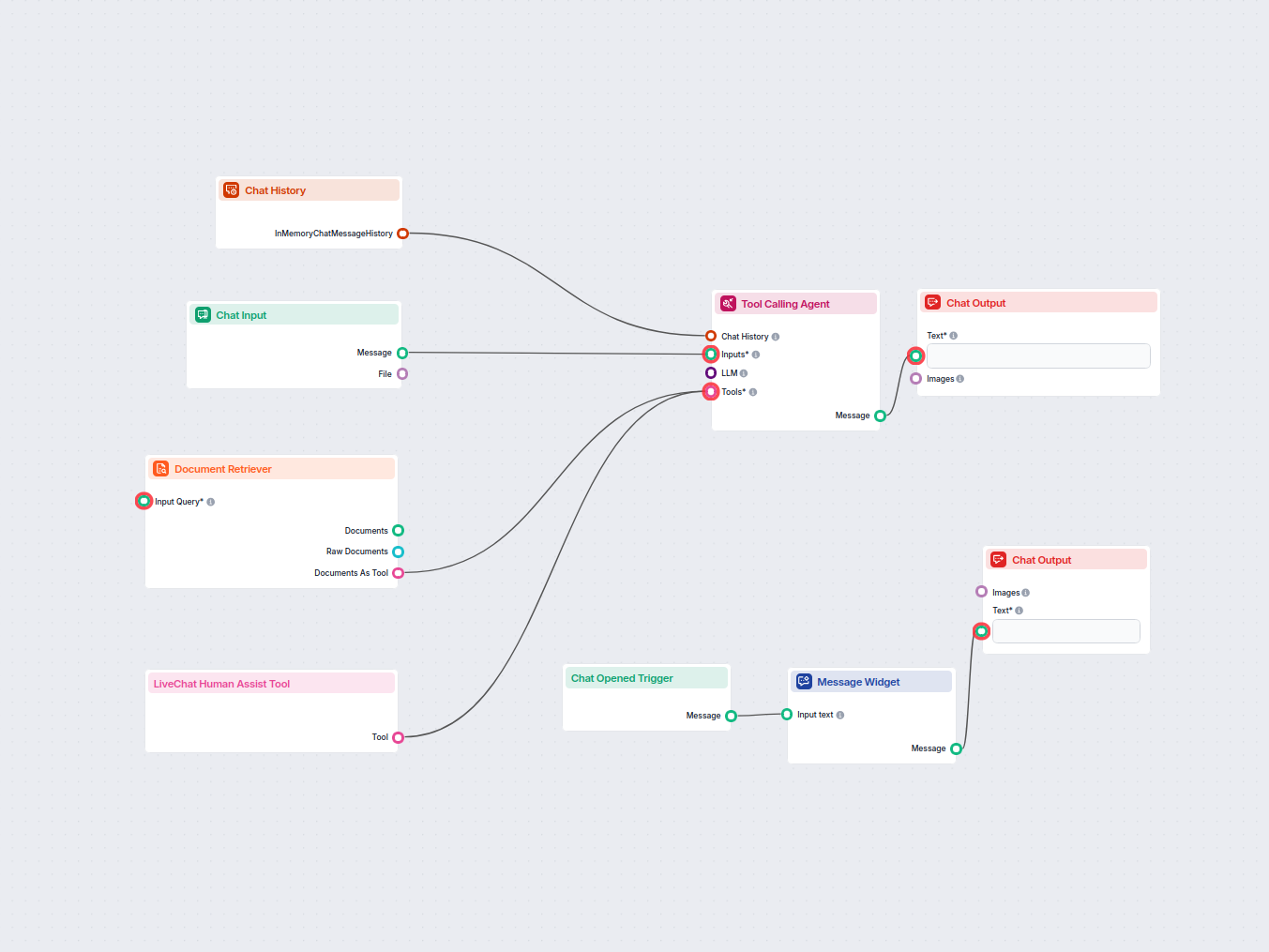
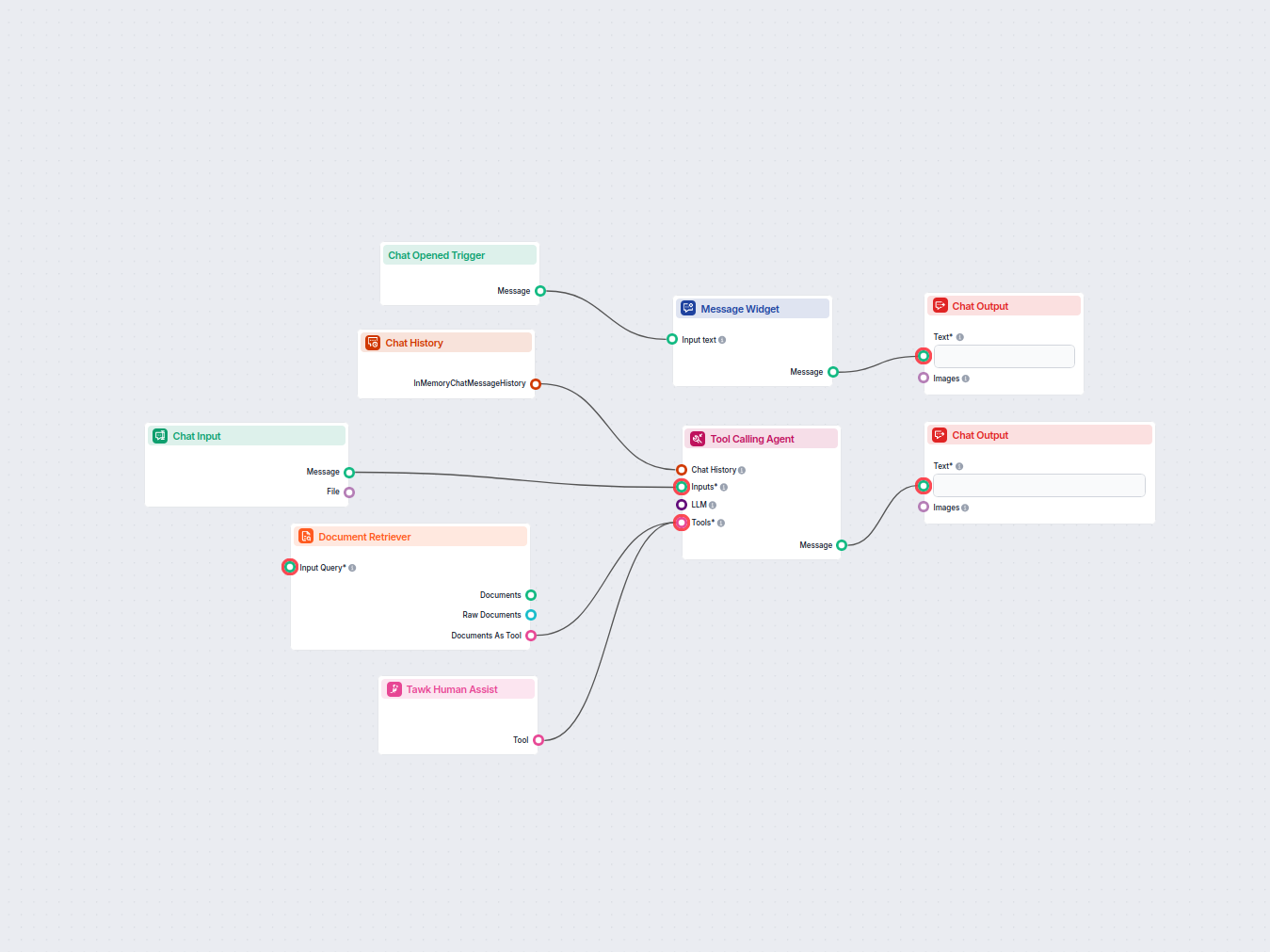
The component contains just one input and one output handle:
The Document output contains structured data unsuitable for the final chat output. All components that take Documents as their input transform them into a user-friendly format. These are either Widget components or the Document to Text transformer.
Let’s Try it Now! Before building the flow, we must ensure we have created relevant Documents or Schedules. If no good source is present, the chatbot will either apologize for being unable to answer.
Steps:
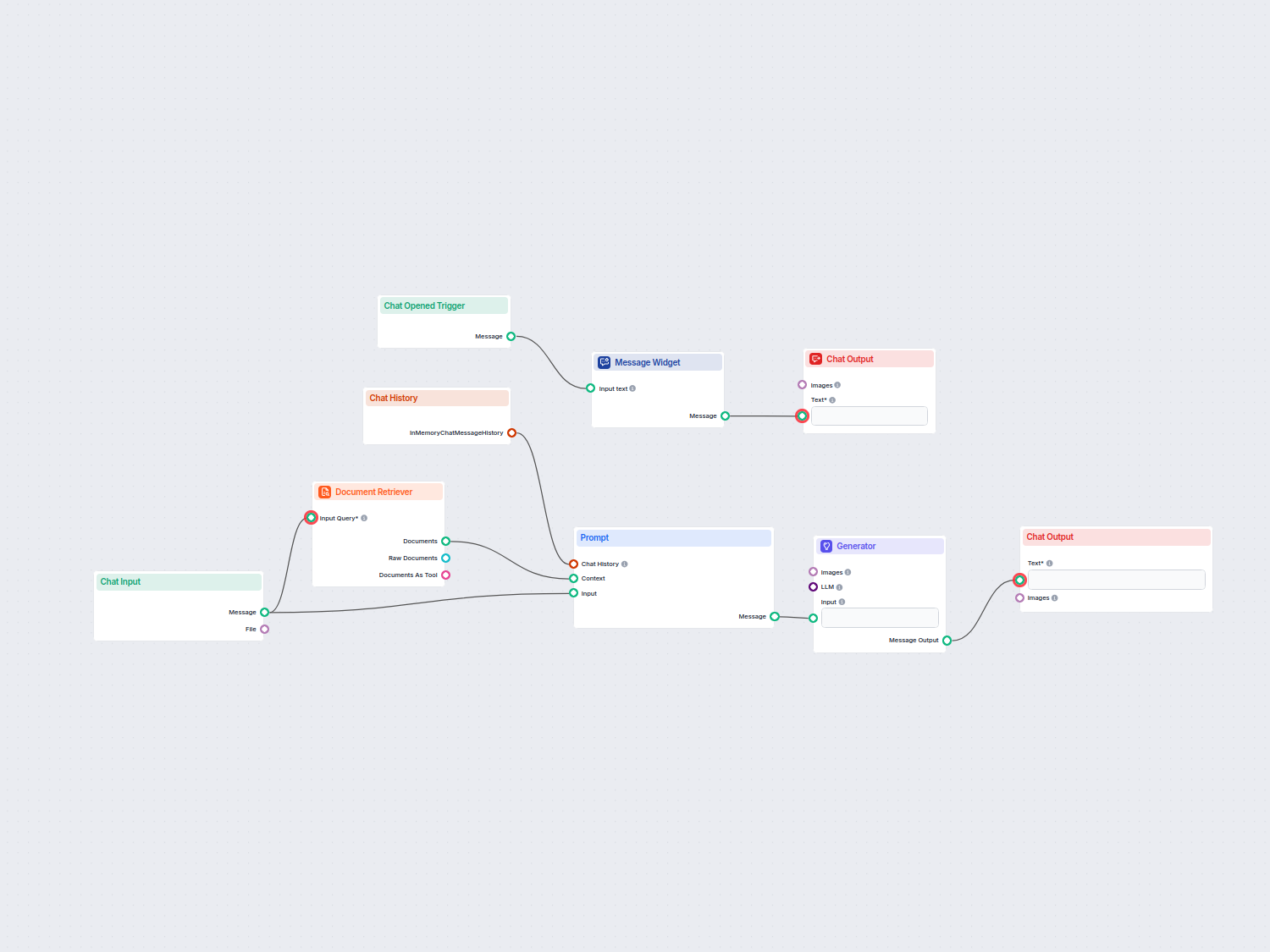
Now our Flow can search our sources based on a human query, transform the structured data into readable text, and pass it to AI to generate a user-friendly answer.
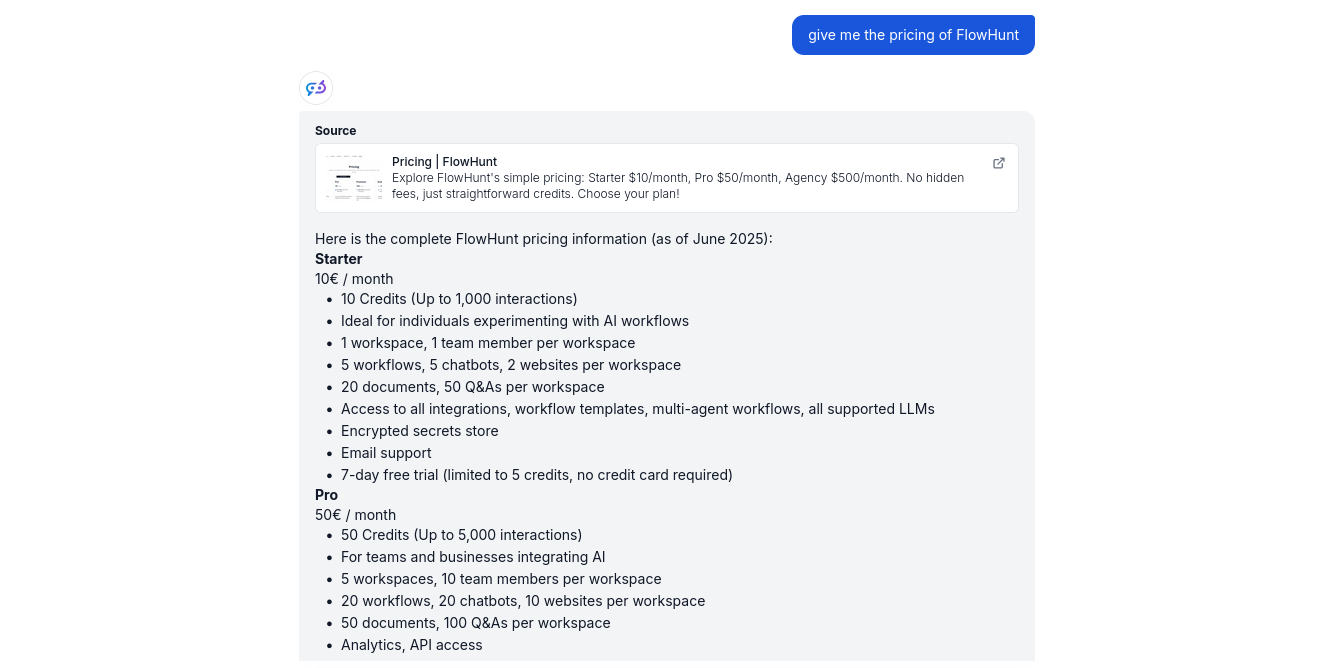
Our Knowledge Sources contain a Schedule set to crawl FlowHunt’s pricing page for up-to-date information. Let’s ask the bot about it:
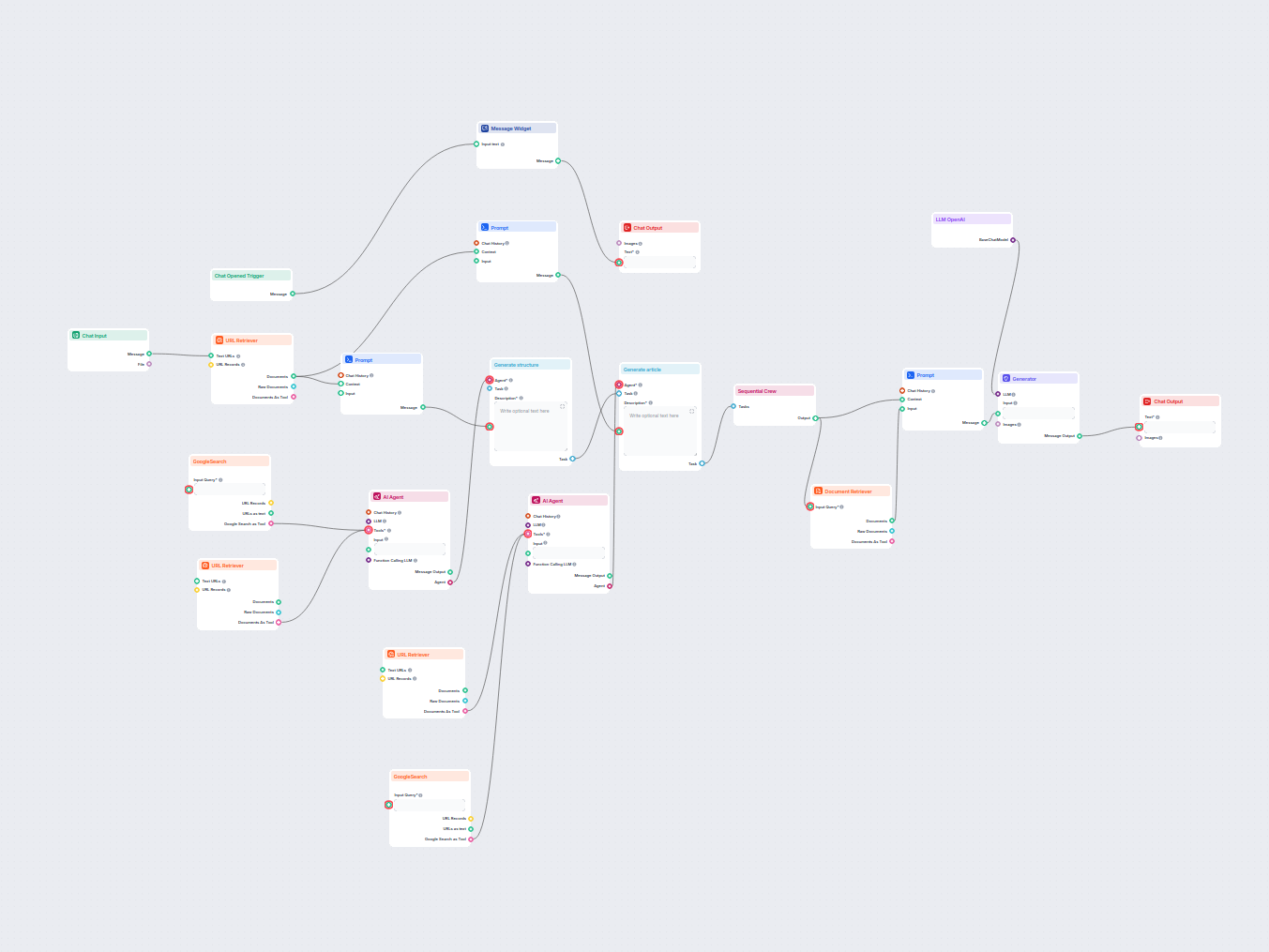
Aby pomóc Ci szybko zacząć, przygotowaliśmy kilka przykładowych szablonów przepływu, które pokazują, jak efektywnie używać komponentu Wyszukiwarka Dokumentów. Te szablony prezentują różne przypadki użycia i najlepsze praktyki, ułatwiając zrozumienie i implementację komponentu w Twoich własnych projektach.
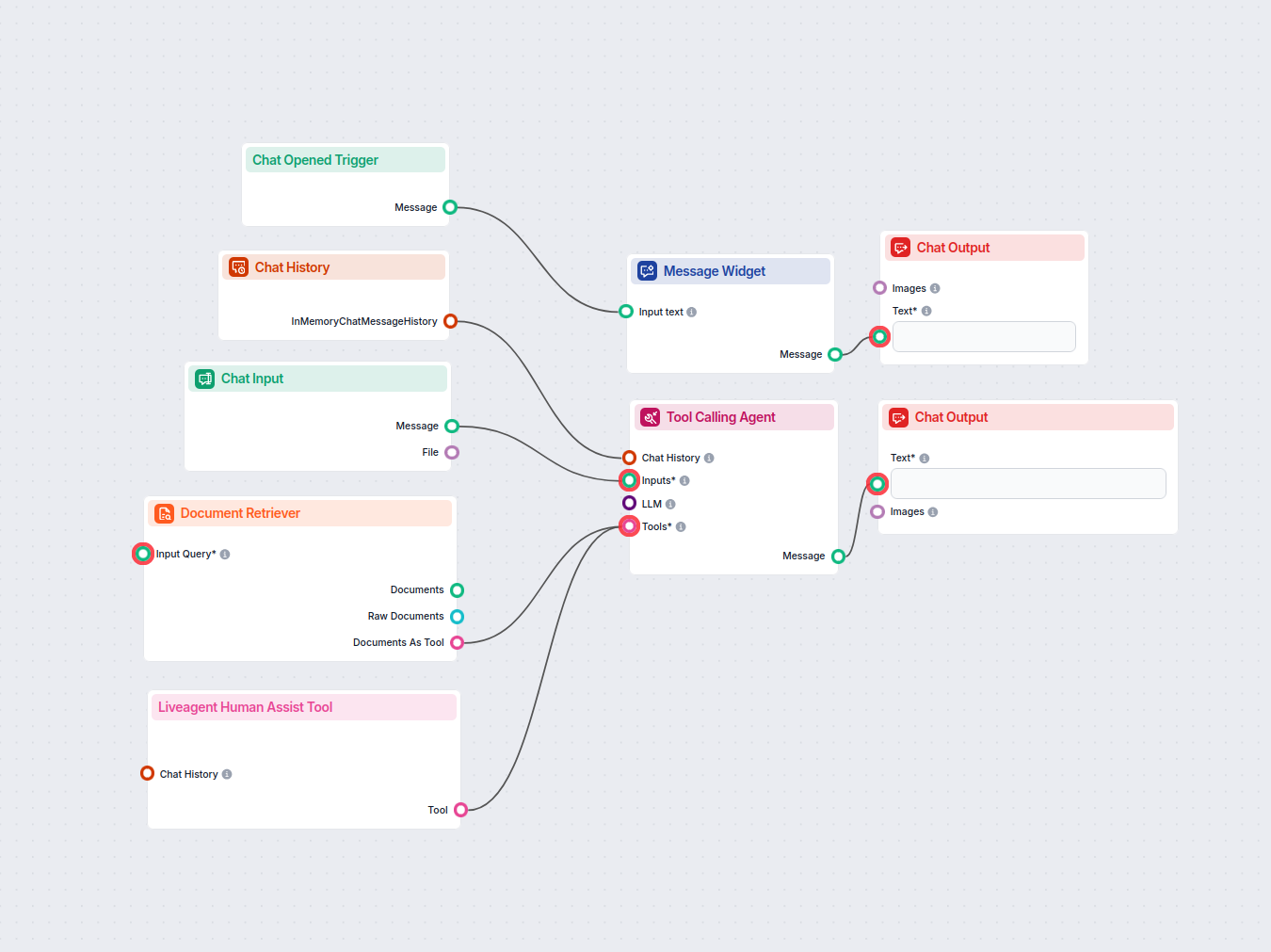
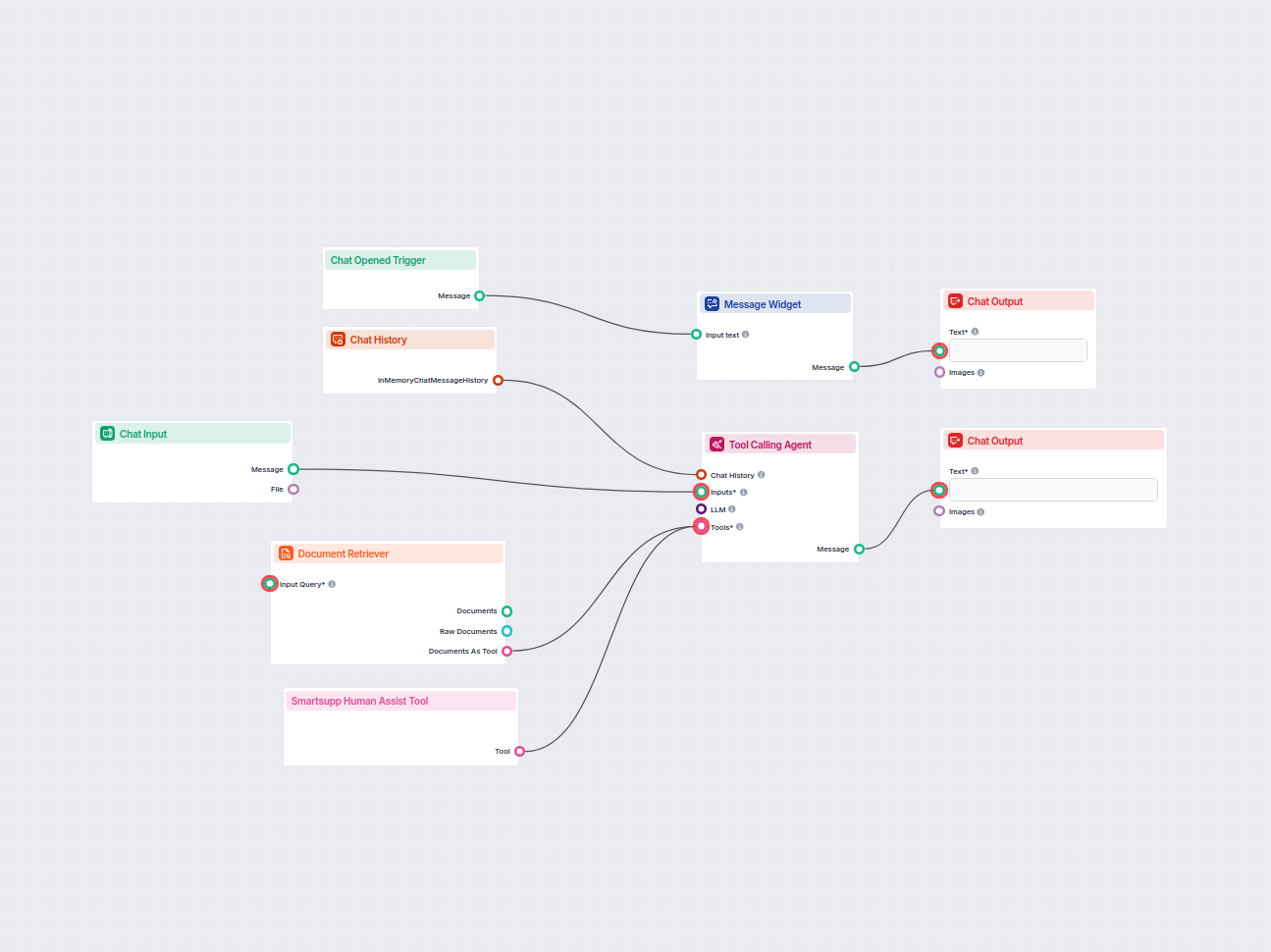
Ten workflow automatyzuje obsługę klienta w Twojej firmie poprzez integrację rozmów z LiveAgent, wydobywanie istotnych danych z konwersacji, generowanie odpowie...
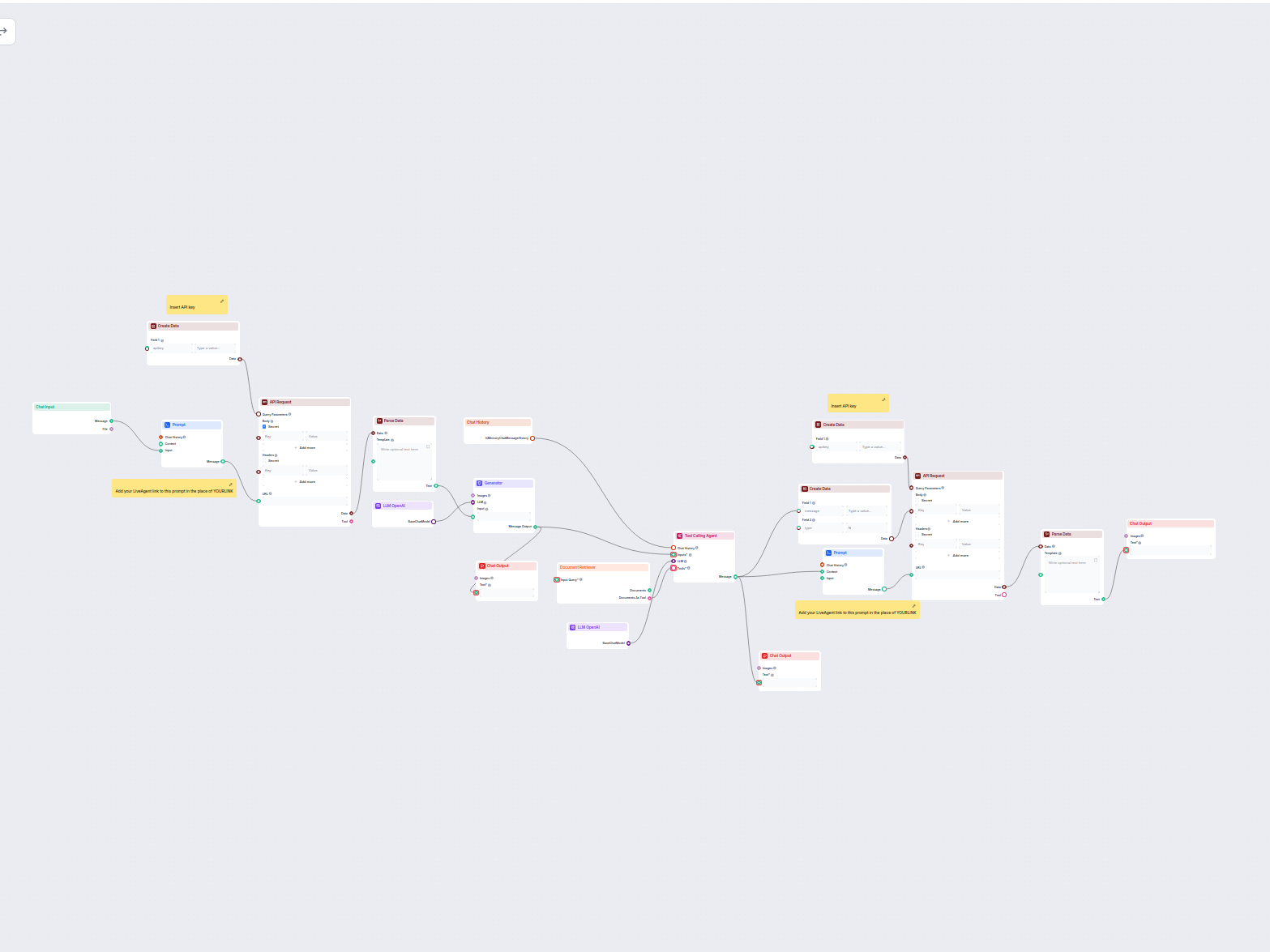
Ten oparty na AI workflow automatyzuje obsługę klienta poprzez łączenie wyszukiwania w wewnętrznej bazie wiedzy, pobierania informacji z Google Docs, integracji...
Ten zautomatyzowany przez AI workflow automatyzuje obsługę klienta poprzez łączenie zapytań użytkowników ze źródłami wiedzy firmy, zewnętrznymi API (takimi jak ...
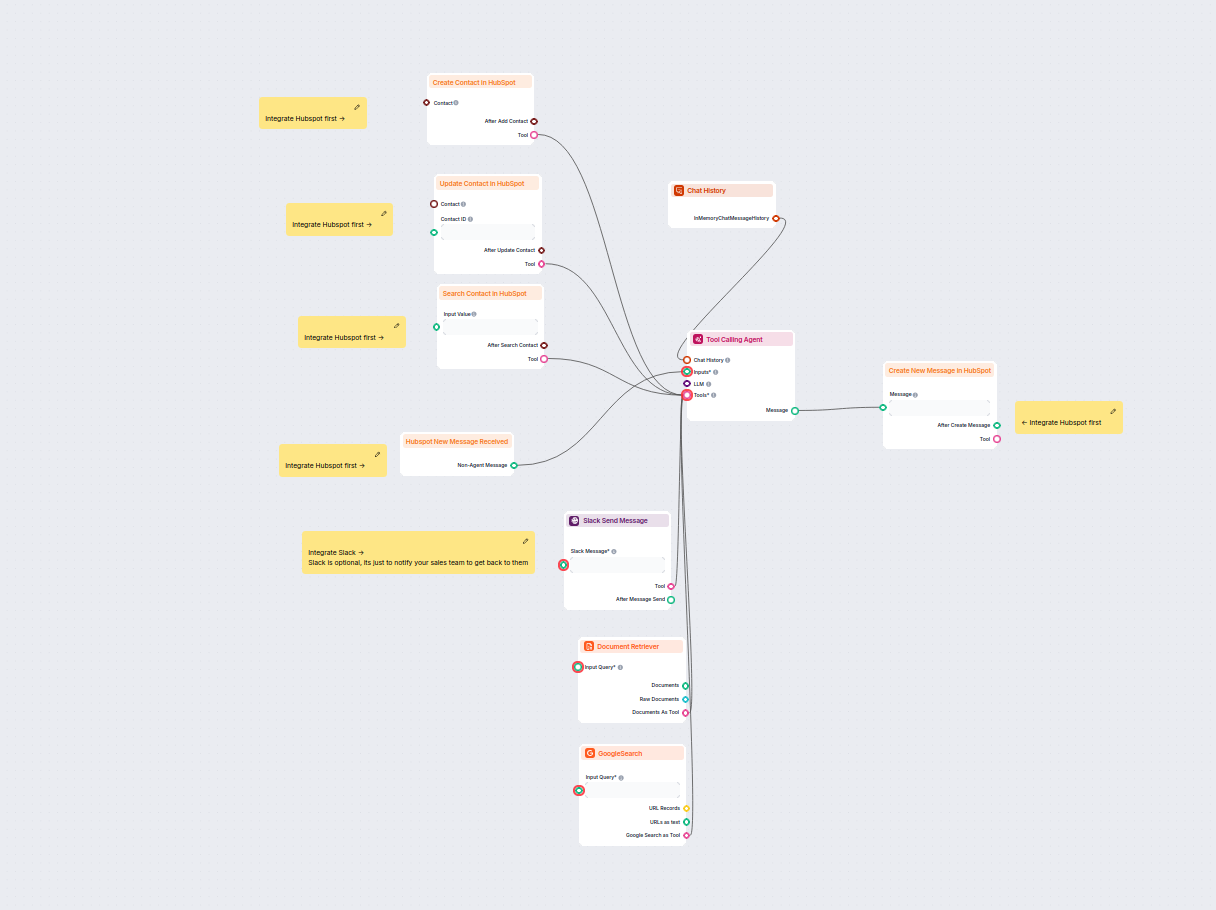
Ten workflow oparty na AI automatyzuje kwalifikację leadów i zarządzanie kontaktami w HubSpot. Chatbot zbiera informacje o użytkowniku, bada szczegóły firmy, id...
Ten chatbot do generowania leadów oparty na AI zapewnia spersonalizowane wsparcie klienta, wykorzystując Twoją wewnętrzną bazę wiedzy, identyfikuje potencjalnyc...
Czatujący bot obsługi klienta zasilany AI, który wykorzystuje Twoje wewnętrzne źródła wiedzy, aby zapewnić natychmiastowe, dokładne i pomocne odpowiedzi na zapy...
Ten workflow oparty na AI analizuje strukturę treści Twojej strony internetowej, porównuje ją ze stronami konkurencji o najwyższych pozycjach i przedstawia sper...
Asystent chatbot AI oparty na OpenAI GPT-4o, który automatycznie przeszukuje i wykorzystuje wewnętrzne dokumenty firmowe do odpowiadania na pytania użytkowników...
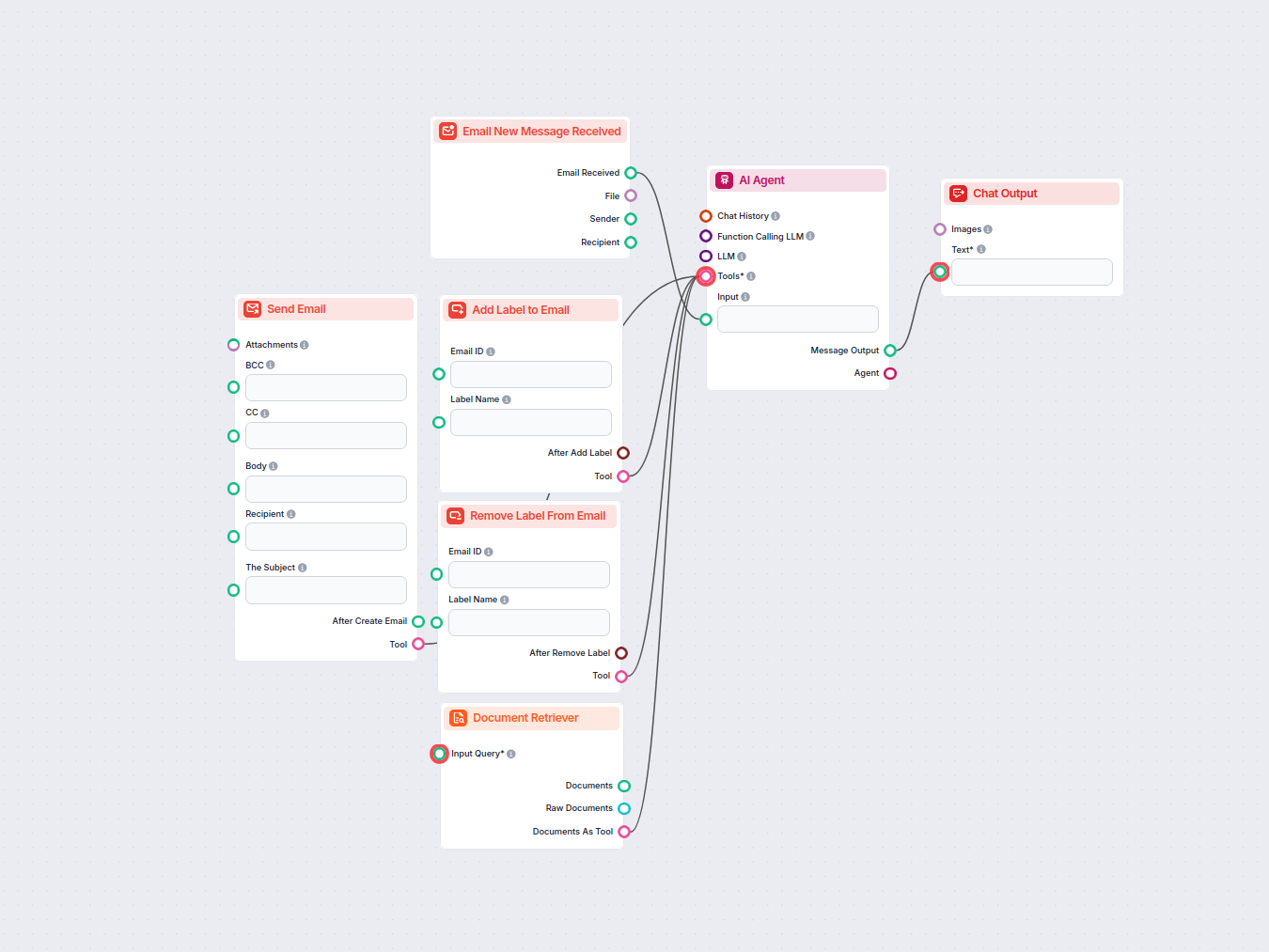
Automatyzuj zarządzanie skrzynką odbiorczą Gmaila za pomocą agenta AI, który czyta przychodzące e-maile, korzysta z Twojej bazy wiedzy do tworzenia profesjonaln...
Automatyzuj profesjonalne odpowiedzi na e-maile w Outlooku przy użyciu agenta AI, który wykorzystuje źródła wiedzy organizacyjnej. Przychodzące e-maile są odbie...
Wdróż chatbot AI na swojej stronie internetowej, który wykorzystuje wewnętrzną bazę wiedzy do odpowiadania na pytania klientów oraz płynnie przekazuje złożone l...
Czatbot wspierający obsługę klienta, oparty na AI, który odpowiada na pytania klientów, korzystając z wewnętrznej bazy wiedzy, a w przypadku skomplikowanych zap...
Chatbot obsługi klienta oparty na AI, który automatycznie wspiera użytkowników, pobiera informacje z wewnętrznych dokumentów i internetu oraz płynnie przekierow...
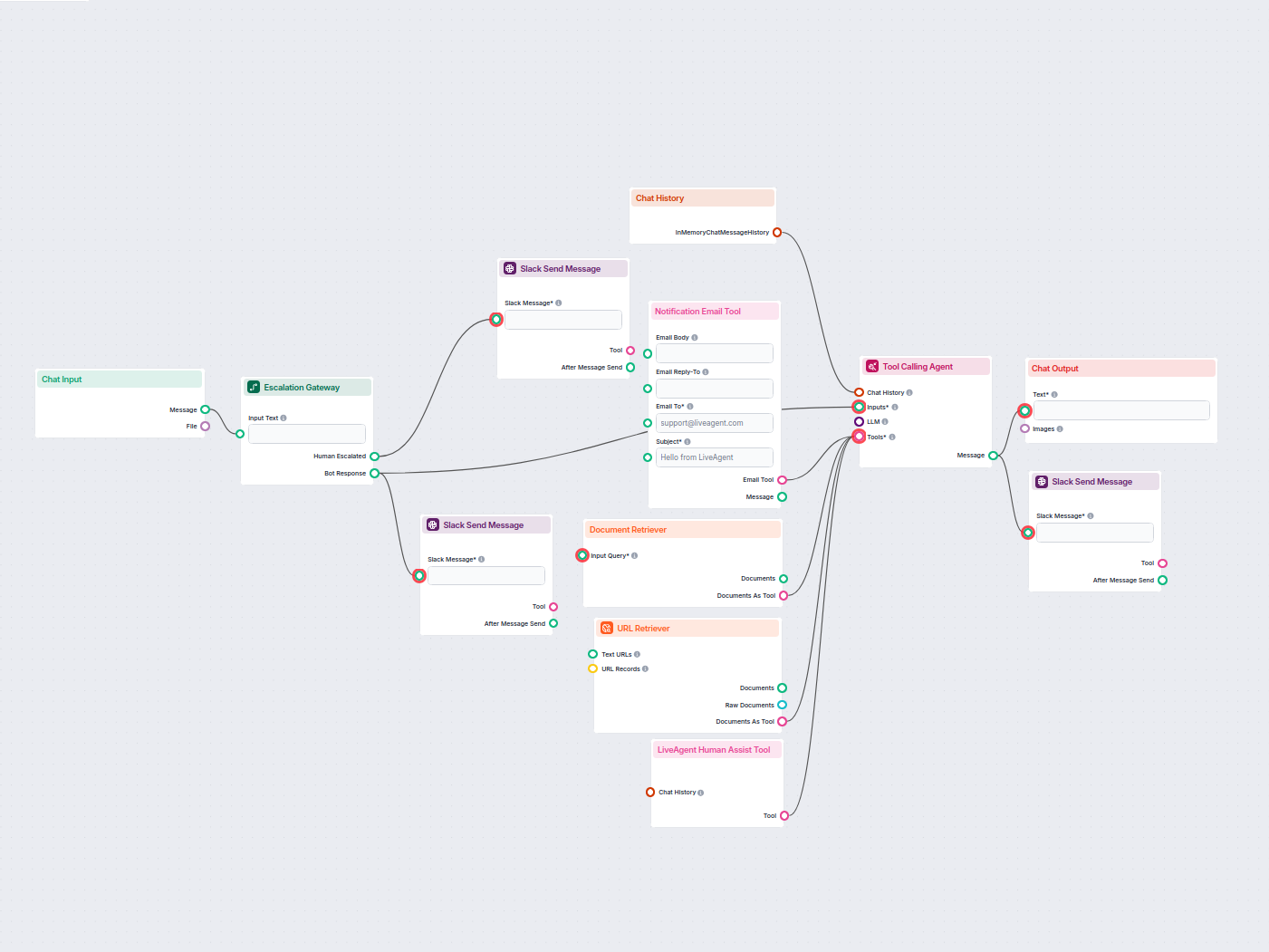
Automatyzuj obsługę klienta za pomocą chatbota AI, który odpowiada na pytania korzystając z wewnętrznej bazy wiedzy i w razie potrzeby płynnie łączy użytkownikó...
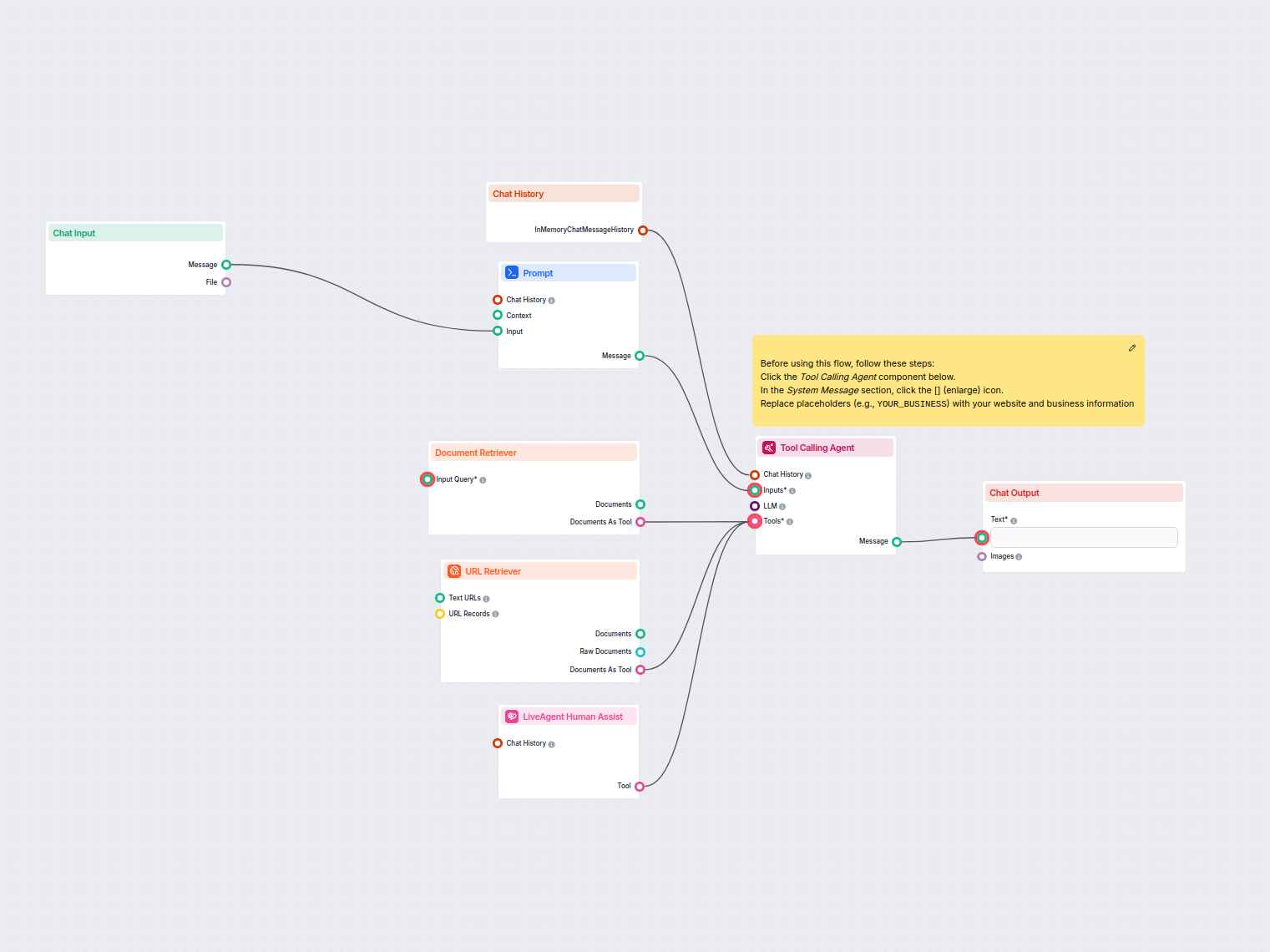
Wdrażaj inteligentnego czatbota do obsługi klienta w LiveAgent, który automatycznie odpowiada na pytania odwiedzających, pobiera dokumenty z bazy wiedzy i eskal...
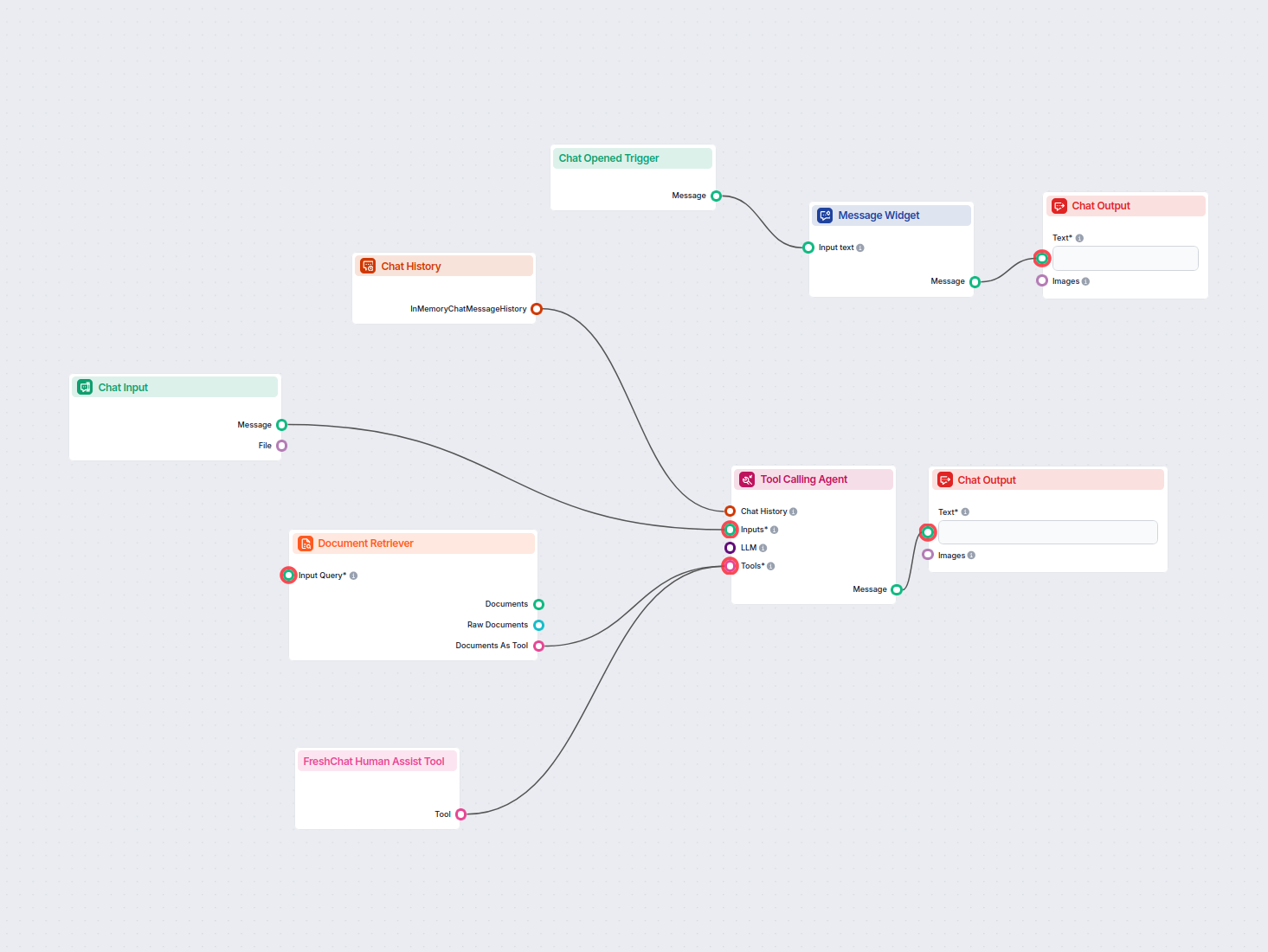
Wdróż inteligentnego czatbota AI, który bezproblemowo integruje się z FreshChat. Czatbot odpowiada na zapytania użytkowników, korzystając z Twojej wewnętrznej b...
Automatycznie generuje krótki, angażujący akapit na Twoją stronę internetową, zawierający linki do najbardziej powiązanych artykułów. Ten workflow oparty na AI ...
Generuj zwięzłe podsumowania ze stron internetowych, przesłanych dokumentów lub filmów z YouTube za pomocą AI. Idealny do szybkiego streszczania kluczowych wnio...
Przekształć dokumentację techniczną z podanego adresu URL w atrakcyjny, zoptymalizowany pod SEO artykuł na swoją stronę internetową. Ten przepływ analizuje najl...
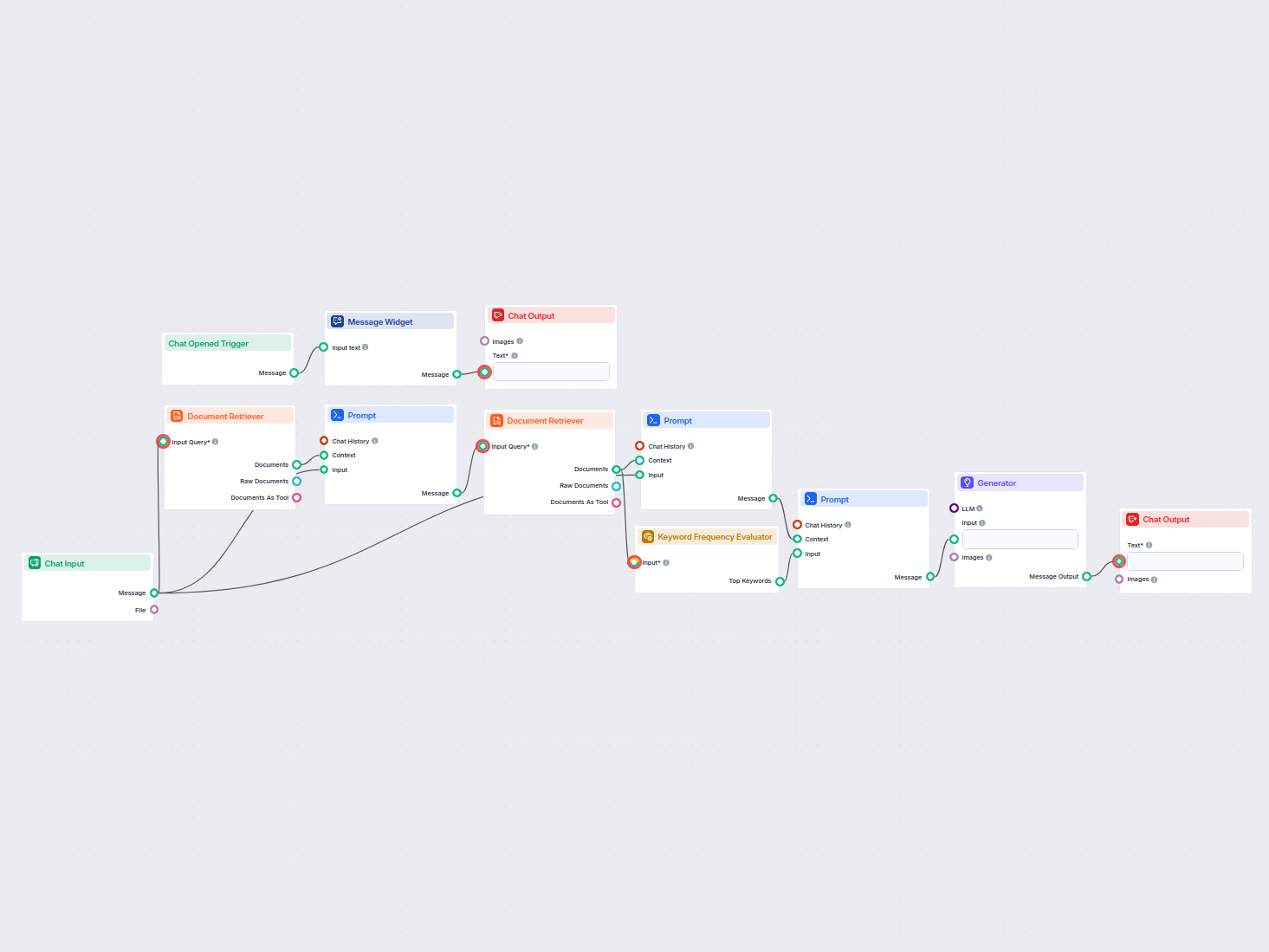
Łatwe wyszukiwanie i pobieranie informacji z prywatnych dokumentów bazy wiedzy dzięki semantycznemu wyszukiwaniu wspieranemu przez AI. Przepływ rozszerza zapyta...
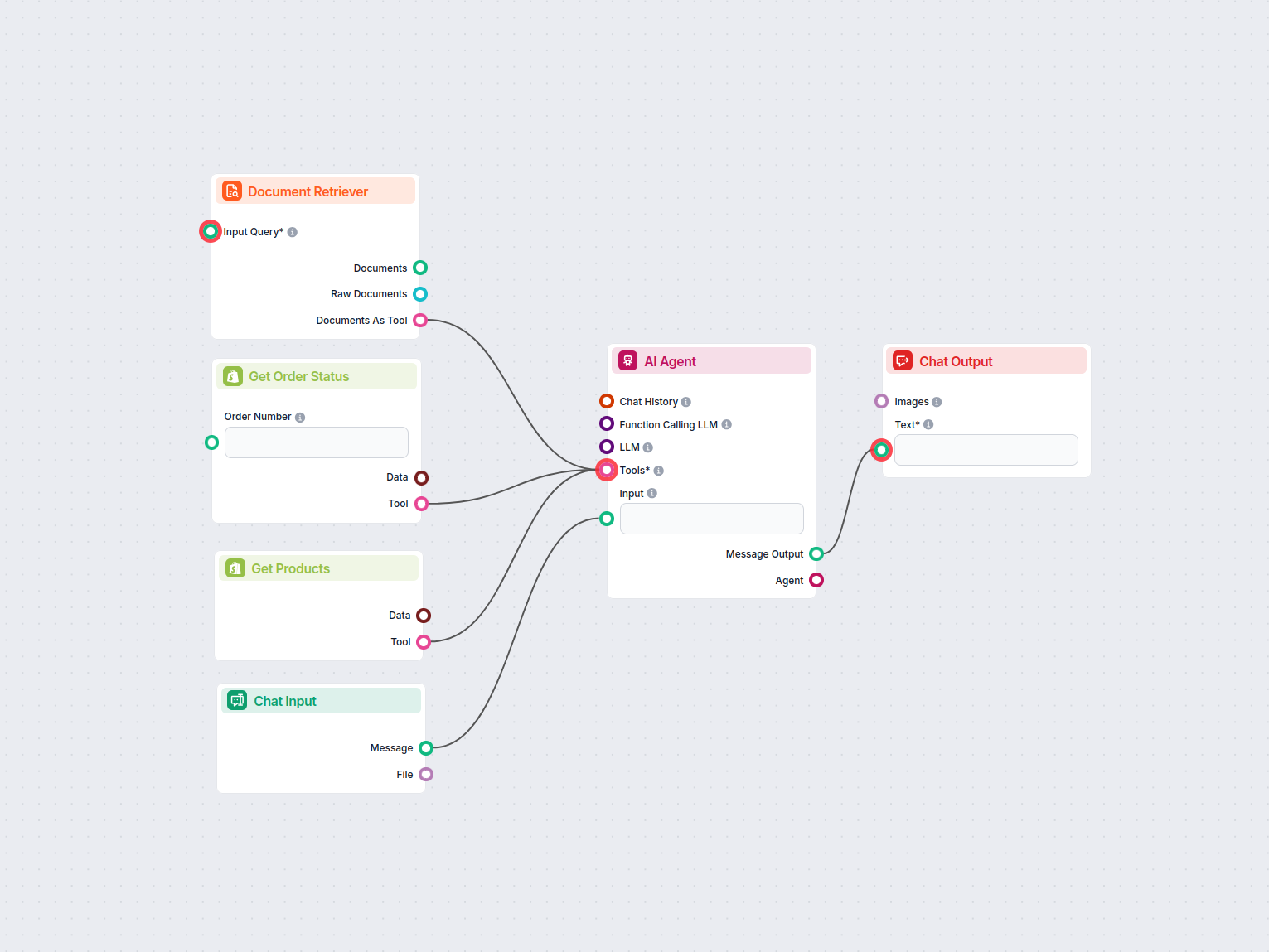
Przepływ pracy dla agenta obsługi klienta opartego na AI, który może odpowiadać na pytania dotyczące produktów Shopify, sprawdzać status zamówienia oraz uzyskiw...
Ten workflow tworzy chatbota wspieranego przez AI, zintegrowanego ze Smartsupp, wykorzystując wewnętrzną bazę wiedzy do odpowiadania na zapytania wsparcia klien...
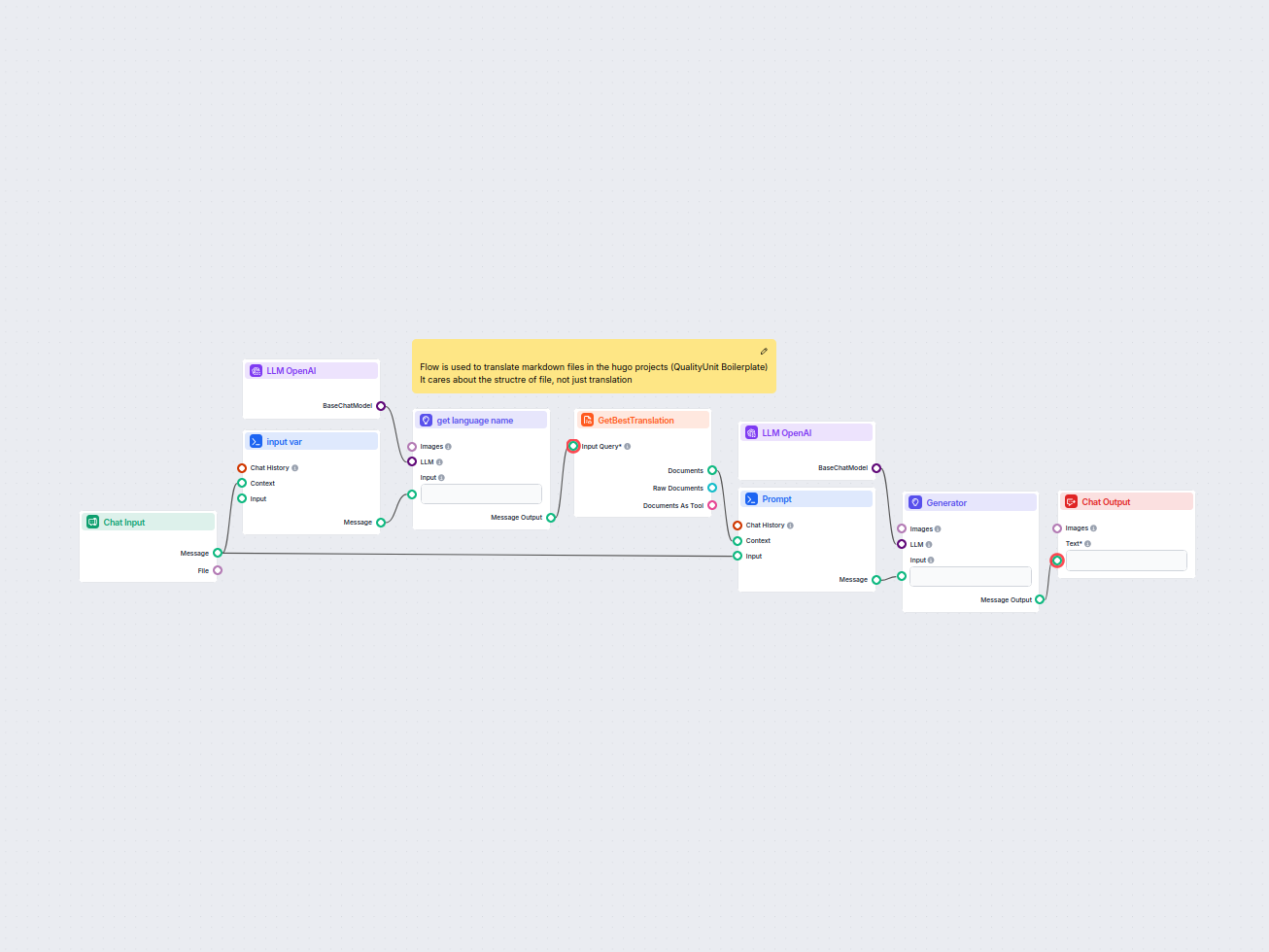
Ten przepływ pracy usprawnia tłumaczenie plików markdown HUGO na języki docelowe przy zachowaniu struktury pliku i formatowania. Wykorzystując modele językowe A...
Automatyzuj obsługę klienta w LiveAgent za pomocą czatbota AI, który odpowiada na pytania wykorzystując Twoją wewnętrzną bazę wiedzy, pobiera odpowiednie dokume...
Ten komponent pozwala Flow pobierać wiedzę z Twoich własnych źródeł, takich jak dokumenty i adresy URL, zapewniając, że zwracane informacje są trafne, wiarygodne i aktualne.
Komponenty wyszukiwarki tworzą ustrukturyzowane dane, które nie nadają się do wyjścia. Najpierw muszą zostać przekształcone na format tekstowy lub wizualny przed wysłaniem do komponentu Wyjście Czatowe.
Komponent wyszukuje najbliższe dopasowanie zapytania w informacjach pochodzących z podanych przez użytkownika adresów URL, dokumentów i harmonogramów.
Możesz ustawić limit liczby zwracanych wyników, dzięki czemu do Twojego flow trafia tylko najbardziej istotna treść.
Tak, możesz filtrować według kategorii dokumentów, harmonogramów lub adresów URL, koncentrując wyszukiwanie na określonych segmentach swojej bazy wiedzy.
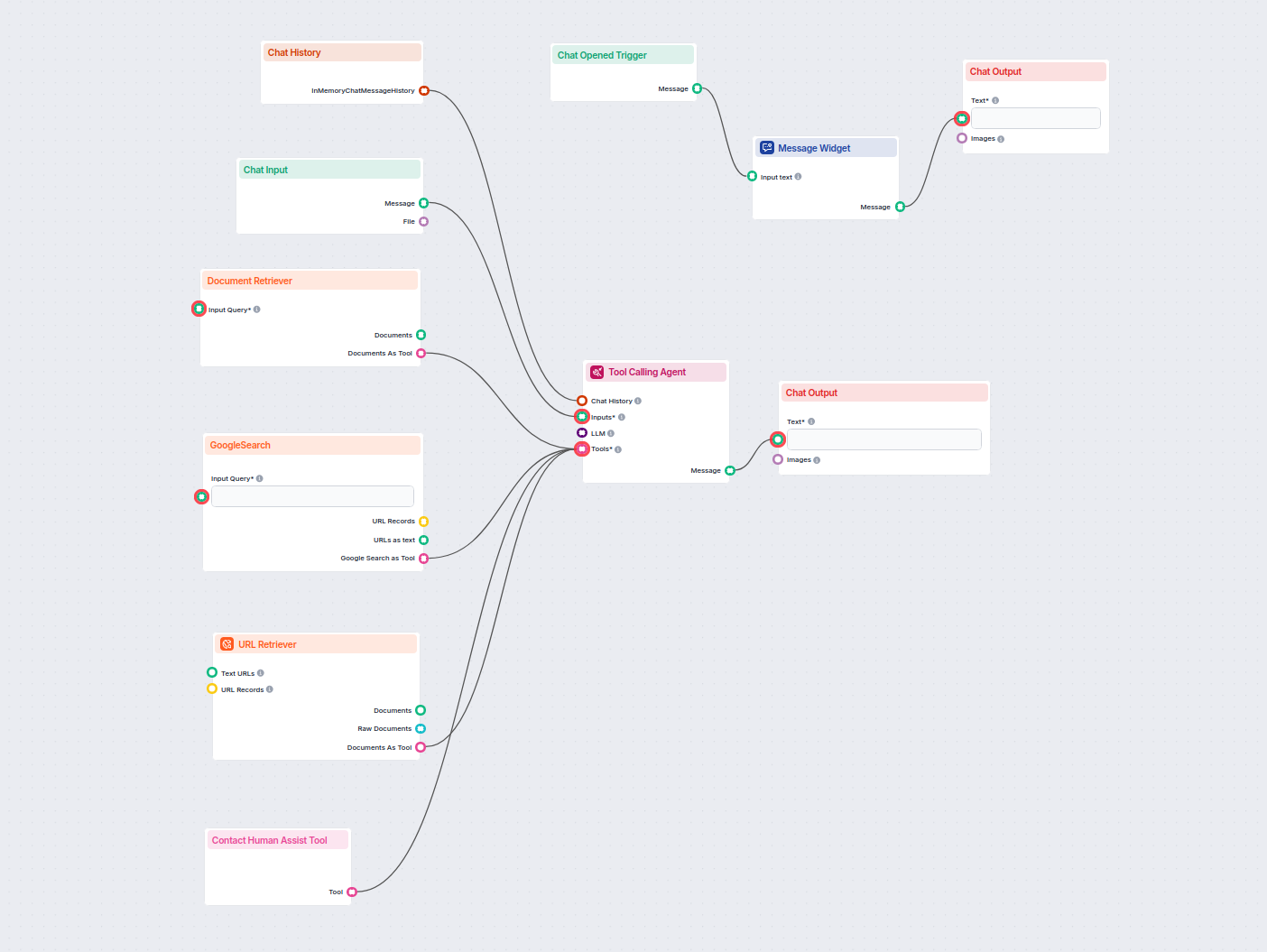
Możesz używać obu jednocześnie. Każda wyszukiwarka prowadzi do własnego wyjścia, a priorytet ustala się według kolejności wyjść na płótnie. Priorytet ma pierwsze wyjście od góry.
Buduj inteligentniejsze rozwiązania AI, łącząc własne źródła wiedzy i zapewniając, że Twój chatbot zawsze udziela trafnych, aktualnych odpowiedzi.
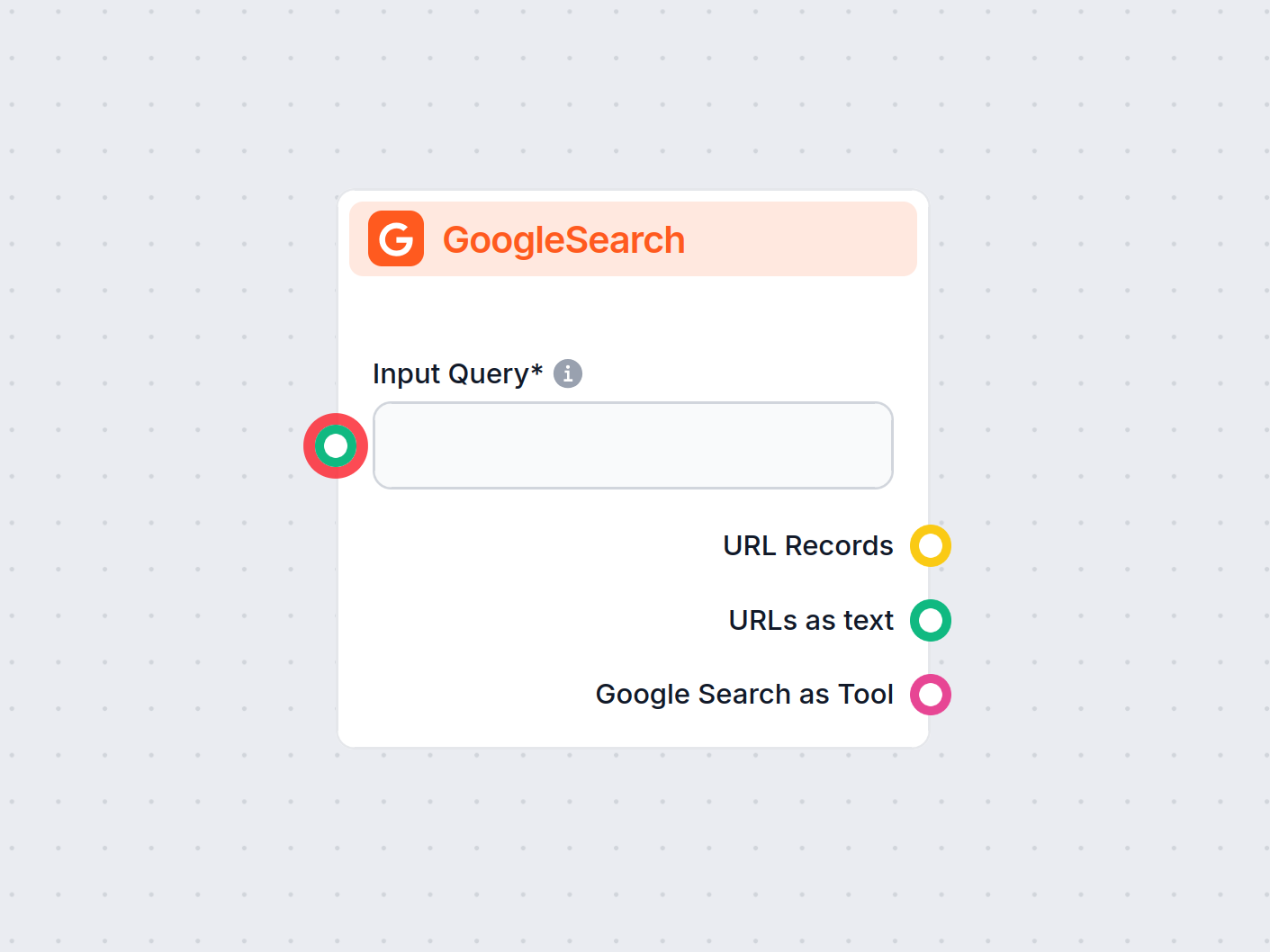
Komponent GoogleSearch platformy FlowHunt zwiększa dokładność chatbotów, wykorzystując Retrieval-Augmented Generation (RAG) do pozyskiwania najnowszej wiedzy z ...
Źródła wiedzy sprawiają, że nauczanie AI według Twoich potrzeb jest niezwykle proste. Odkryj wszystkie sposoby łączenia wiedzy z FlowHunt. Łatwo połącz strony i...
Odpowiadanie na pytania z wykorzystaniem Retrieval-Augmented Generation (RAG) łączy wyszukiwanie informacji oraz generowanie języka naturalnego, aby ulepszyć du...