Widżet Źródła Wiedzy
Prezentuj odpowiednie dokumenty bezpośrednio w odpowiedziach chatbota za pomocą Widżetu Źródła Wiedzy. Ten komponent wyświetla wybrane dokumenty wiedzy jako wiz...
2 min czytania
AI
Knowledge
+4
Przekształć ustrukturyzowane dane w czytelny tekst markdown dzięki komponentowi Dokument na tekst FlowHunt, oferującemu konfigurowalne opcje dla wydajnych i trafnych wyników zasilanych przez AI.
Opis komponentu
AI can analyze large quantities of data in seconds, but only some of the data will be relevant or suitable for output. The Document to Text component gives you control over how the data from retrievers is processed and transformed into text.
The Document to Text component is designed to transform input knowledge documents into plain text format. This is particularly useful in AI and data processing workflows where textual data is required for further processing, analysis, or as input to language models.
This component takes one or more structured documents (such as HTML, Markdown, PDFs, or other supported formats) and extracts the textual content. It allows you to specify precisely which parts of the documents to export, whether to include metadata, and how to handle document sections or headers. The output is a unified message object containing the extracted text, ready for downstream tasks like summarization, classification, or question answering.
The component accepts several configurable inputs:
| Input Name | Type | Required | Description | Default Value |
|---|---|---|---|---|
| Documents | List[Document] | Yes | The knowledge documents to transform into text. | N/A (user provided) |
| From H1 if exists | Boolean | Yes | Start extraction from the first H1 header if present. | true |
| Load from pointer | Boolean | Yes | Start extraction from the pointer best matching the input query, or load all if not matched. | true |
| Max Tokens | Integer | No | Maximum number of tokens in the output text. | 3000 |
| Skip Last Header | Boolean | Yes | Skip the last header (often a footer) to optimize output. | false |
| Strategy | String | Yes | Text extraction strategy: concatenate documents or include equal size from each. | “Include equal size from each documents” |
| Export Content | Multi-select | No | Which content types to include (e.g., H1, H2, Paragraph). | All types selected |
| Include Metadata | Multi-select | No | Metadata fields to include in the output if available. | Product |
Content Types available: H1, H2, H3, H4, H5, H6, Paragraph
Metadata options: Author, Product, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
The component produces the following output:
| Capability | Description |
|---|---|
| Input Types | List of Documents |
| Output Type | Message (Text + Metadata) |
| Content Granularity | Select headers/paragraphs to include |
| Metadata Options | Select multiple metadata fields to export |
| Output Size Control | Set max tokens |
| Extraction Strategies | Concatenate or balance across documents |
| Section Selection | Start from H1, from pointer, or skip last header |
The bot may crawl many documents to create the text output. The Strategy setting lets you control how it utilizes these documents smartly while staying within the token limit.
Currently, there are two possible strategies:
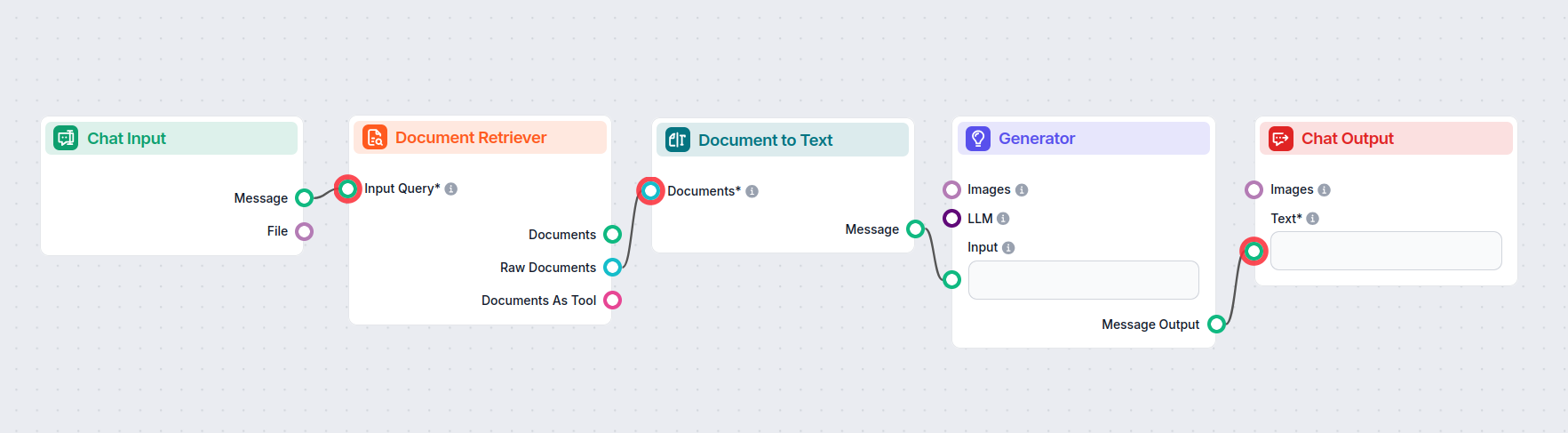
This is a transformer component, meaning it bridges the gap between two outputs. Document to Text takes Documents outputted by the Retriever components:
The knowledge is converted into readable Markdown text as it passes through the transformer. This text can then be connected to components requiring text input, such as splitters, widgets, or outputs.
Here is an example flow using the Document to Text component to bridge the gap between the Document Retrievers and the AI Generator:
Komponent pobiera wiedzę z komponentów typu retriever i przekształca ją w czytelny tekst markdown, który można następnie połączyć z dowolnym komponentem przyjmującym tekst jako wejście.
Zacznij budować inteligentniejsze rozwiązania AI z komponentem Dokument na tekst FlowHunt. Bezproblemowo przekształcaj dane w użyteczny tekst i usprawniaj swoje zautomatyzowane procesy.
Prezentuj odpowiednie dokumenty bezpośrednio w odpowiedziach chatbota za pomocą Widżetu Źródła Wiedzy. Ten komponent wyświetla wybrane dokumenty wiedzy jako wiz...
Komponent Eksport do pliku w FlowHunt umożliwia zapisywanie tekstu lub danych generowanych podczas Twojego workflow do pobieralnych plików w różnych formatach, ...
Przekształcaj tekst w gotowe do pobrania pliki PDF za pomocą komponentu Eksport do PDF w FlowHunt. Bezproblemowo konwertuj markdown lub zwykły tekst ze swojego ...