LLM Meta AI
FlowHunt obsługuje dziesiątki modeli generowania tekstu, w tym modele Llama firmy Meta. Dowiedz się, jak zintegrować Llama z własnymi narzędziami AI i chatbotam...
3 min czytania
LLM
Meta AI
+4
LLM Mistral na FlowHunt umożliwia elastyczną integrację zaawansowanych modeli Mistral AI do płynnego generowania tekstu w chatbotach i narzędziach AI.
Opis komponentu
The LLM Mistral component connects the Mistral models to your flow. While the Generators and Agents are where the actual magic happens, LLM components allow you to control the model used. All components come with ChatGPT-4 by default. You can connect this component if you wish to change the model or gain more control over it.
Remember that connecting an LLM Component is optional. All components that use an LLM come with ChatGPT-4o as the default. The LLM components allow you to change the model and control model settings.
Tokens represent the individual units of text the model processes and generates. Token usage varies with models, and a single token can be anything from words or subwords to a single character. Models are usually priced in millions of tokens.
The max tokens setting limits the total number of tokens that can be processed in a single interaction or request, ensuring the responses are generated within reasonable bounds. The default limit is 4,000 tokens, which is the optimal size for summarizing documents and several sources to generate an answer.
Temperature controls the variability of answers, ranging from 0 to 1.
A temperature of 0.1 will make the responses very to the point but potentially repetitive and deficient.
A high temperature of 1 allows for maximum creativity in answers but creates the risk of irrelevant or even hallucinatory responses.
For example, the recommended temperature for a customer service bot is between 0.2 and 0.5. This level should keep the answers relevant and to the script while allowing for a natural response variation.
This is the model picker. Here, you’ll find all the supported models from Mistral. We currently support the following models:
How To Add The LLM Mistral To Your Flow
You’ll notice that all LLM components only have an output handle. Input doesn’t pass through the component, as it only represents the model, while the actual generation happens in AI Agents and Generators.
The LLM handle is always purple. The LLM input handle is found on any component that uses AI to generate text or process data. You can see the options by clicking the handle:
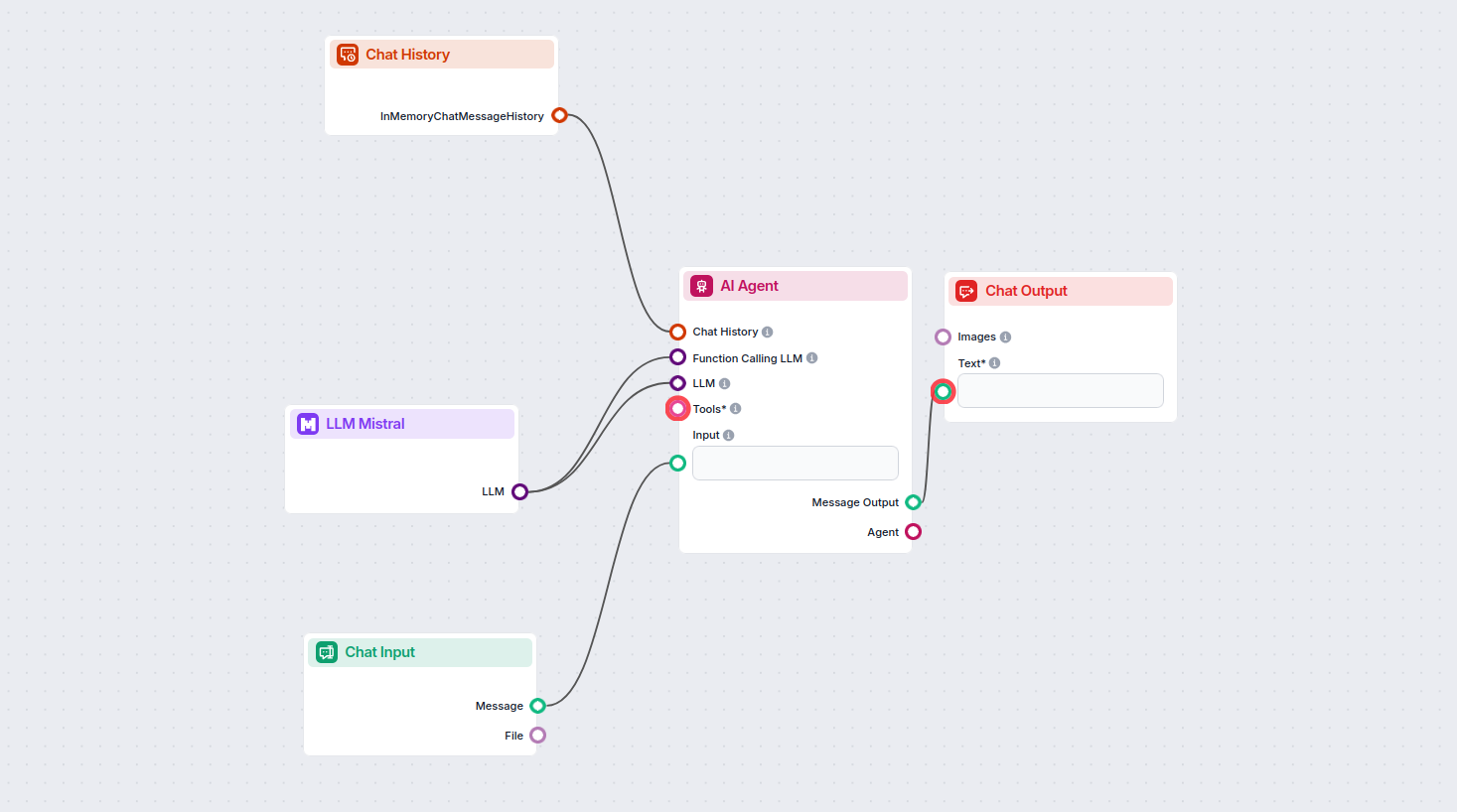
This allows you to create all sorts of tools. Let’s see the component in action. Here’s a simple AI Agent chatbot Flow that’s using the Mistral 7B model to generate responses. You can think of it as a basic Mistral chatbot.
This simple Chatbot Flow includes:
Komponent LLM Mistral pozwala połączyć modele Mistral AI z Twoimi projektami FlowHunt, umożliwiając zaawansowane generowanie tekstu dla Twoich chatbotów i agentów AI. Pozwala na zmianę modeli, kontrolę ustawień oraz integrację modeli takich jak Mistral 7B, Mixtral (8x7B) i Mistral Large.
FlowHunt obsługuje Mistral 7B, Mixtral (8x7B) oraz Mistral Large, z których każdy oferuje różne poziomy wydajności i parametryzacji do różnych potrzeb generowania tekstu.
Możesz dostosować ustawienia takie jak maksymalna liczba tokenów i temperatura oraz wybrać spośród obsługiwanych modeli Mistral, aby kontrolować długość odpowiedzi, kreatywność i zachowanie modelu w swoich przepływach.
Nie, podłączenie komponentu LLM jest opcjonalne. Domyślnie komponenty FlowHunt korzystają z ChatGPT-4o. Użyj komponentu LLM Mistral, jeśli chcesz mieć większą kontrolę lub użyć konkretnego modelu Mistral.
Zacznij budować inteligentniejsze chatboty i narzędzia AI, integrując potężne modele językowe Mistral z platformą FlowHunt bez kodowania.
FlowHunt obsługuje dziesiątki modeli generowania tekstu, w tym modele Llama firmy Meta. Dowiedz się, jak zintegrować Llama z własnymi narzędziami AI i chatbotam...
FlowHunt obsługuje dziesiątki modeli generowania tekstu, w tym modele xAI. Zobacz, jak korzystać z modeli xAI w swoich narzędziach AI i chatbotach.
FlowHunt obsługuje dziesiątki modeli AI, w tym rewolucyjne modele DeepSeek. Oto jak korzystać z DeepSeek w swoich narzędziach AI i chatbotach.

