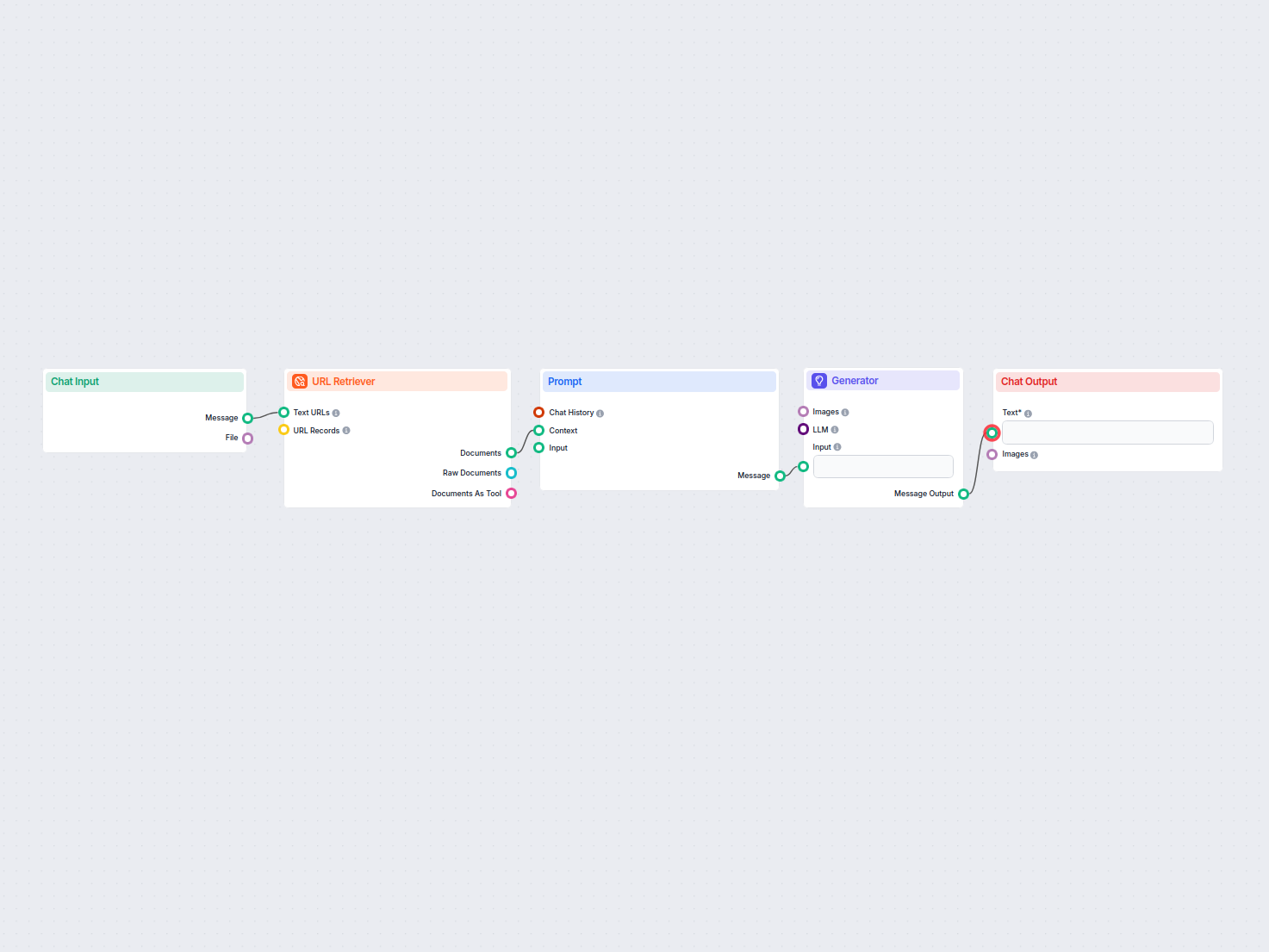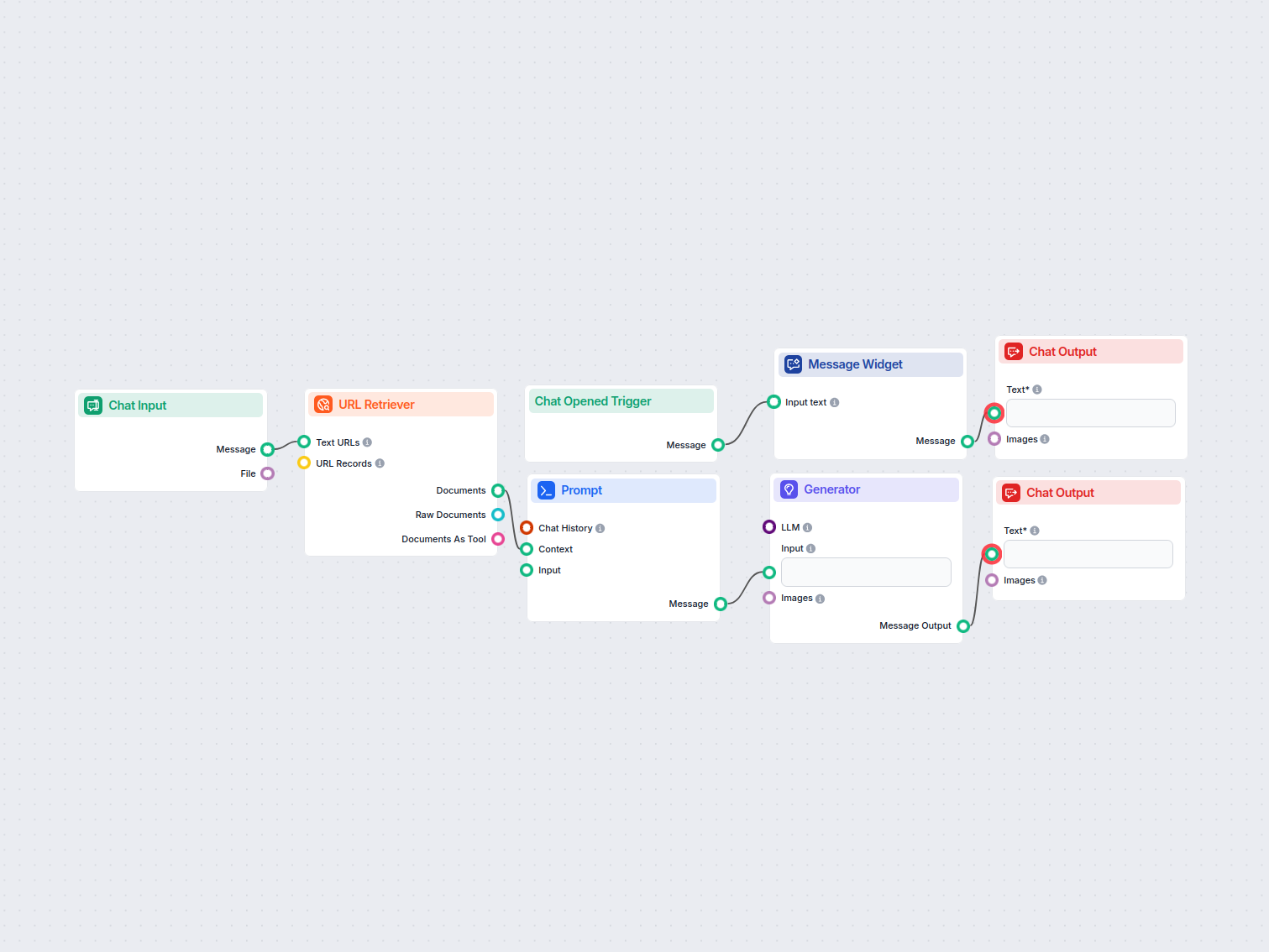
Klasyfikator Intencji Wyszukiwania i Generator Stron Docelowych
Ten przepływ pracy oparty na AI klasyfikuje zapytania wyszukiwania według intencji, bada najlepiej pozycjonowane adresy URL i generuje wysoko zoptymalizowaną st...
4 min czytania
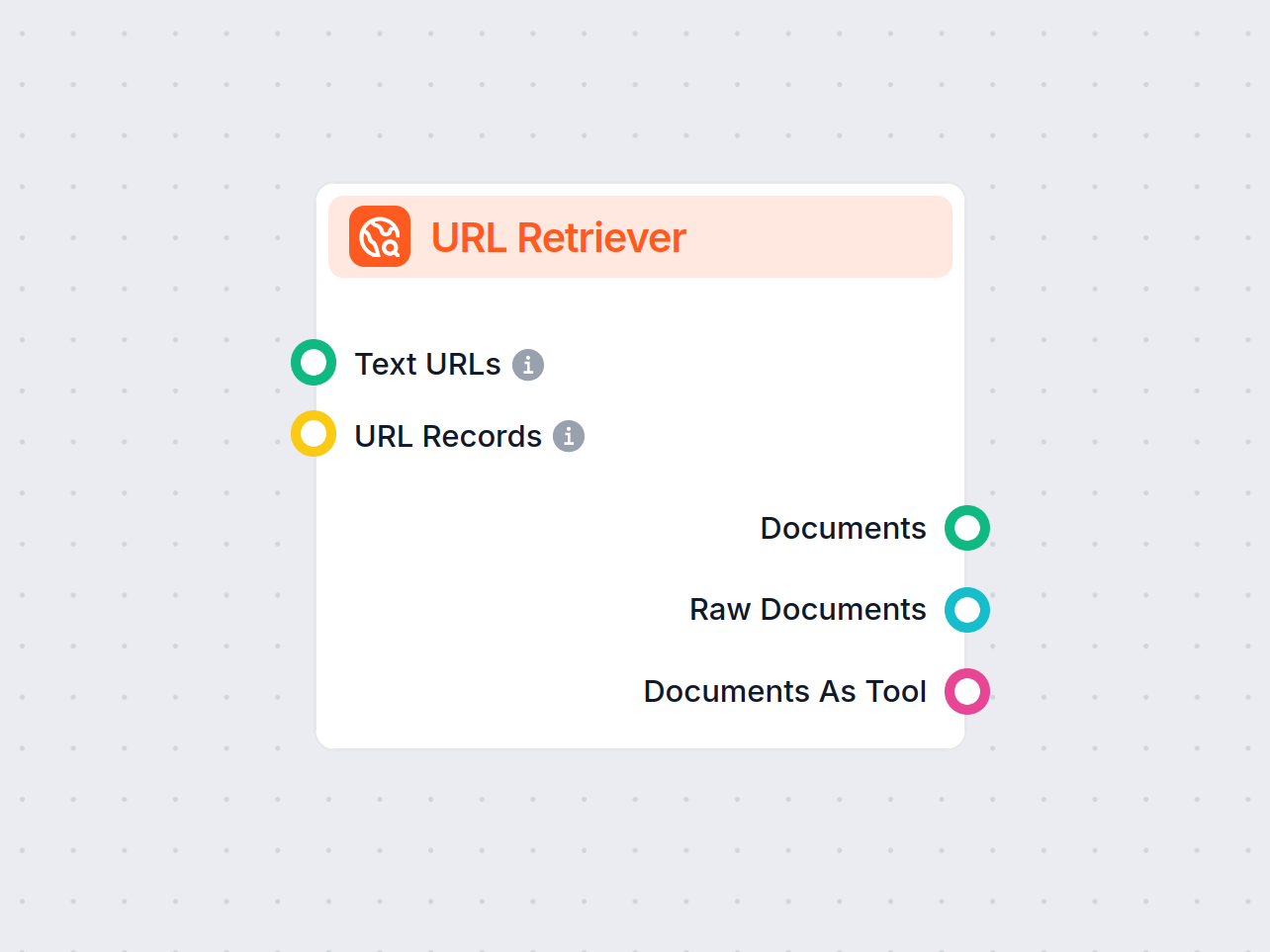
Pobieracz URL pozwala pobierać i przetwarzać treści z linków internetowych, obsługując OCR, wyodrębnianie metadanych oraz elastyczny format wyjściowy do zasilania przepływów AI.
Opis komponentu
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Aby pomóc Ci szybko zacząć, przygotowaliśmy kilka przykładowych szablonów przepływu, które pokazują, jak efektywnie używać komponentu Pobieracz URL. Te szablony prezentują różne przypadki użycia i najlepsze praktyki, ułatwiając zrozumienie i implementację komponentu w Twoich własnych projektach.
Ten przepływ pracy oparty na AI klasyfikuje zapytania wyszukiwania według intencji, bada najlepiej pozycjonowane adresy URL i generuje wysoko zoptymalizowaną st...
Przekształć dowolny plik sitemap.xml w dobrze ustrukturyzowany format llms.txt za pomocą AI. Ten workflow pobiera adresy URL z mapy strony, pobiera i przetwarza...
Przekształć dokumentację techniczną z podanego adresu URL w atrakcyjny, zoptymalizowany pod SEO artykuł na swoją stronę internetową. Ten przepływ analizuje najl...
Automatycznie generuje atrakcyjny obrazek wyróżniający do każdego wpisu na blogu poprzez analizę jego treści. Wystarczy podać adres URL bloga, a workflow wykorz...
Automatycznie optymalizuj nagłówki i tytuł artykułu pod wybrane słowo kluczowe lub klaster słów kluczowych, aby poprawić wyniki SEO. Ten workflow analizuje Twój...
Automatycznie tworzy angażujący, przyjazny SEO metaopis dla dowolnej strony internetowej, pliku PDF, filmu YouTube lub linku do dokumentu, analizując jego treść...
Szybko generuj zwięzłe podsumowania dowolnej strony internetowej, po prostu podając URL. Ten workflow oparty na AI pobiera treść z podanego linku i tworzy angaż...
Ten oparty na AI przepływ pracy ulepsza opisy produktów Shopify na podstawie nazwy produktu lub adresu URL podanego przez użytkownika. Wykorzystuje modele język...
Przekształć dowolny artykuł lub stronę internetową w szczegółowy, kreatywny prompt dla modeli tekst-na-obraz. Ten workflow pobiera treść z podanego adresu URL, ...
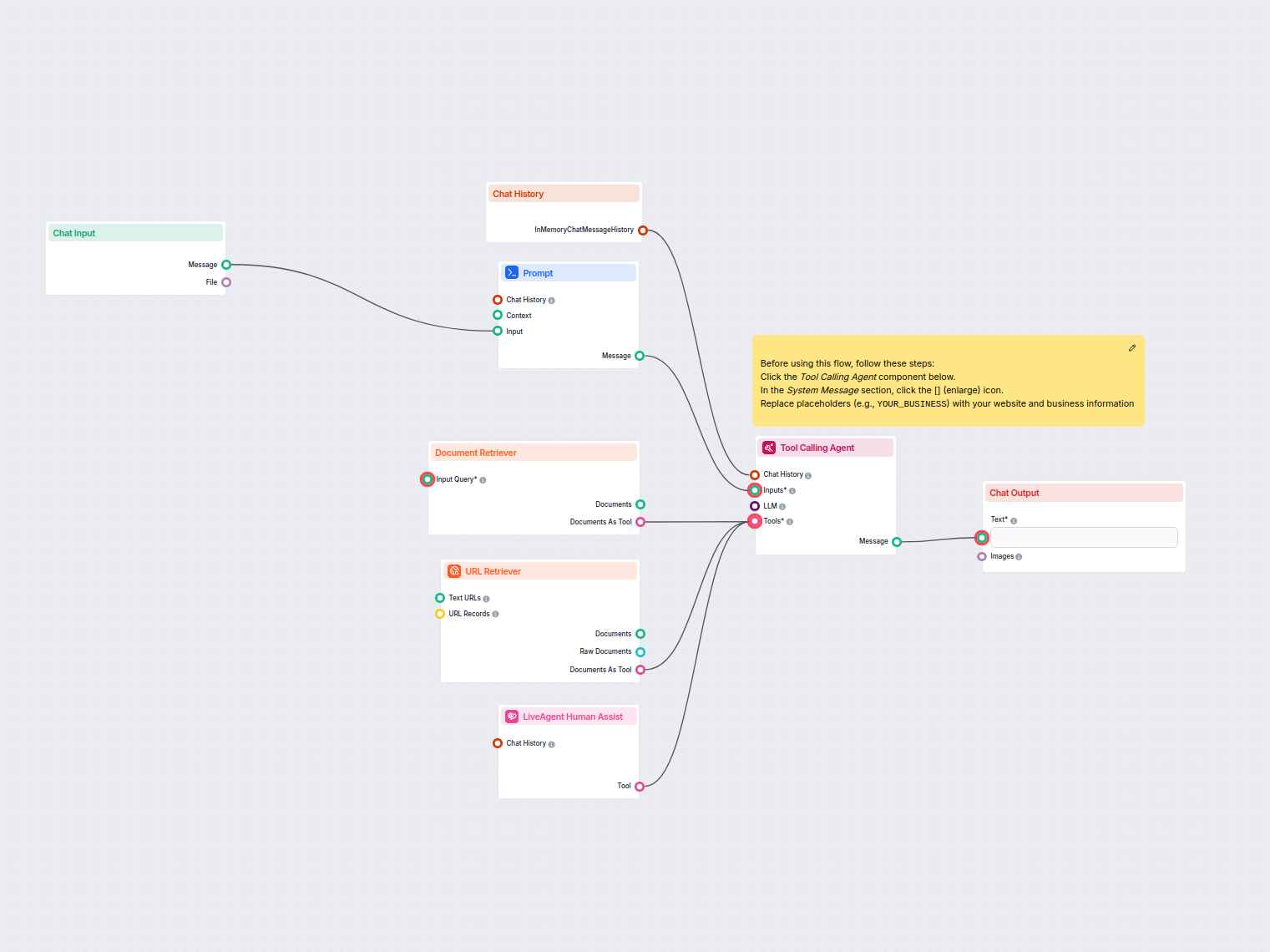
Automatyzuj obsługę klienta w LiveAgent za pomocą czatbota AI, który odpowiada na pytania wykorzystując Twoją wewnętrzną bazę wiedzy, pobiera odpowiednie dokume...
Generuj kompleksowe, zoptymalizowane pod SEO wpisy na bloga o zaawansowanej strukturze i wysokiej liczbie słów, korzystając z wielu agentów AI. Workflow obejmuj...
Automatycznie przekształca treść dowolnego podanego URL w zwięzły, angażujący post odpowiedni na X (Twitter), pomagając marketerom i twórcom szybko zwiększyć sw...
Ten oparty na AI przepływ pracy automatyzuje generowanie leadów wychodzących poprzez identyfikację czołowych firm w określonej niszy i lokalizacji, następnie do...
Pokazywanie 61 do 73 z 73 wyników
Pobieracz URL pobiera i przetwarza treści ze wskazanych linków internetowych, udostępniając tekst i metadane z dokumentów online w Twoim przepływie pracy lub agentowi AI.
Tak, po włączeniu opcji OCR komponent może wyodrębniać tekst z dokumentów obrazowych lub zeskanowanych plików PDF.
Zwraca przetworzone dokumenty jako wiadomości tekstowe, surowe obiekty dokumentów lub jako narzędzie do przepływów agentów — w zależności od konfiguracji.
Możesz ustawić, jak długo pobrane treści mają być buforowane, co ogranicza powtarzające się pobieranie i przyspiesza działanie przepływów pracy.
Tak, możesz określić, które nagłówki, akapity lub pola metadanych mają być zawarte w wyjściu, co pozwala na selektywne wydobywanie.
Zdecydowanie. Pobieracz URL jest niezbędny do każdej automatyzacji lub chatbota, który musi czytać, przetwarzać lub podsumowywać aktualne treści z internetu.
Zwiększ możliwości swoich przepływów pracy, integrując aktualne treści z internetu. Wyodrębniaj, przetwarzaj i wykorzystuj dane z adresów URL z łatwością.
Integruj swoje workflowy z Google Docs za pomocą komponentu Google Docs Retriever—pobieraj treść dokumentów bezpośrednio do automatyzacji, chatbotów lub przepły...
Komponent Pobieracz Plików w FlowHunt pozwala wprowadzać pliki do Twojego przepływu pracy i konwertować je na dokumenty do dalszego przetwarzania. Obsługuje str...
Rejestruj natychmiastowe zrzuty ekranu stron internetowych za pomocą komponentu Narzędzie do Zrzutów Ekranu. Łatwo automatyzuj wykonywanie zrzutów dowolnego adr...