Jak zweryfikować autentyczność chatbota AI
Poznaj sprawdzone metody weryfikacji autentyczności chatbotów AI w 2025 roku. Odkryj techniczne techniki weryfikacji, kontrole bezpieczeństwa i najlepsze prakty...
10 min czytania
Poznaj kompleksowe metody pomiaru dokładności chatbota AI w helpdesku w 2025 roku. Odkryj precyzję, recall, wskaźniki F1, metryki satysfakcji użytkownika i zaawansowane techniki oceny z FlowHunt.
Mierz dokładność chatbota AI w helpdesku za pomocą wielu metryk, w tym precyzji i recall, macierzy pomyłek, wskaźników satysfakcji użytkownika, wskaźników rozwiązań oraz zaawansowanych metod oceny opartych o LLM. FlowHunt oferuje kompleksowe narzędzia do automatycznego oceniania dokładności i monitorowania wydajności.
Pomiar dokładności chatbota AI w helpdesku jest kluczowy, aby zapewnić niezawodne i pomocne odpowiedzi na zapytania klientów. W przeciwieństwie do prostych zadań klasyfikacyjnych, dokładność chatbota obejmuje wiele wymiarów, które należy oceniać łącznie, by uzyskać pełny obraz jego wydajności. Proces ten polega na analizie, jak dobrze chatbot rozumie zapytania użytkowników, udziela poprawnych informacji, skutecznie rozwiązuje problemy i utrzymuje zadowolenie użytkownika przez cały czas interakcji. Kompleksowa strategia pomiaru dokładności łączy metryki ilościowe z opiniami jakościowymi, by wskazać mocne strony i obszary wymagające ulepszeń.
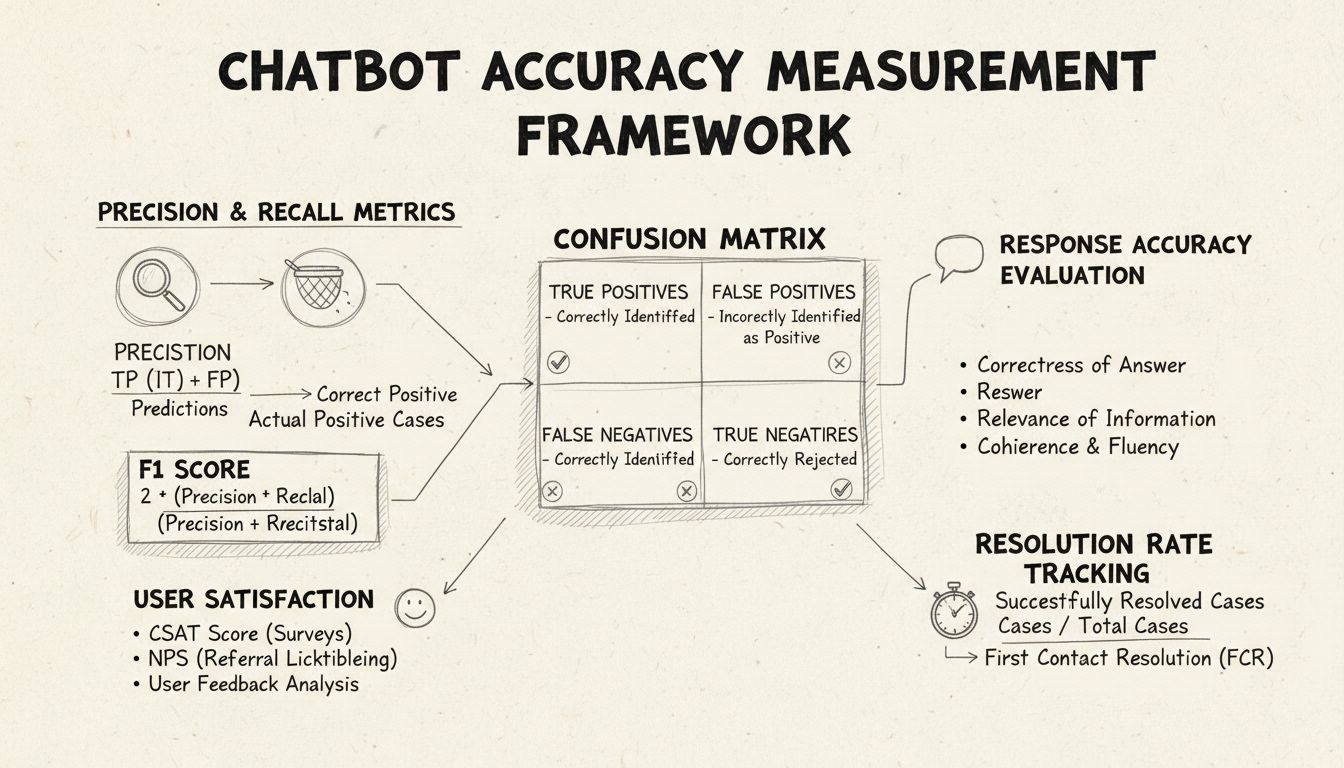
Precyzja i recall to podstawowe metryki wywodzące się z macierzy pomyłek, które mierzą różne aspekty działania chatbota. Precyzja oznacza odsetek poprawnych odpowiedzi spośród wszystkich odpowiedzi udzielonych przez chatbota, obliczany według wzoru: Precyzja = True Positives / (True Positives + False Positives). Ta metryka odpowiada na pytanie: „Jak często, gdy chatbot udziela odpowiedzi, jest ona poprawna?” Wysoki wynik precyzji oznacza, że chatbot rzadko udziela błędnych informacji, co jest kluczowe dla utrzymania zaufania użytkowników w scenariuszach helpdeskowych.
Recall, znany również jako czułość, mierzy odsetek poprawnych odpowiedzi spośród wszystkich, które chatbot powinien był udzielić, według wzoru: Recall = True Positives / (True Positives + False Negatives). Metryka ta pokazuje, czy chatbot skutecznie rozpoznaje i odpowiada na wszystkie uprawnione problemy klientów. W kontekście helpdesku wysoki recall gwarantuje, że klienci uzyskują pomoc, zamiast być informowanymi, że chatbot nie może pomóc, gdy w rzeczywistości powinien móc. Między precyzją a recall istnieje naturalny kompromis: optymalizacja jednej często zmniejsza drugą, dlatego wymaga to odpowiedniego zbalansowania zgodnie z priorytetami biznesowymi.
Wskaźnik F1 zapewnia pojedynczą metrykę, która równoważy precyzję i recall, obliczaną jako średnia harmoniczna: F1 = 2 × (Precyzja × Recall) / (Precyzja + Recall). Ta metryka jest szczególnie cenna, gdy potrzebujesz jednego wskaźnika wydajności lub masz do czynienia z niezrównoważonymi danymi, gdzie jedna klasa znacząco dominuje. Na przykład, jeśli Twój chatbot obsługuje 1000 rutynowych zapytań i tylko 50 skomplikowanych eskalacji, wskaźnik F1 zapobiega zafałszowaniu metryki przez dominującą klasę. Wskaźnik F1 przyjmuje wartości od 0 do 1, gdzie 1 oznacza idealną precyzję i recall, co czyni go intuicyjnym do szybkiego zrozumienia przez interesariuszy.
Macierz pomyłek to podstawowe narzędzie, które rozbija wydajność chatbota na cztery kategorie: True Positives (poprawne odpowiedzi na prawidłowe zapytania), True Negatives (poprawne odrzucenia pytań spoza zakresu), False Positives (błędne odpowiedzi) oraz False Negatives (nieudane próby pomocy). Macierz ta ujawnia konkretne wzorce niepowodzeń chatbota, umożliwiając ukierunkowane poprawki. Na przykład, jeśli macierz pokazuje dużo false negatives w zapytaniach o faktury, możesz zidentyfikować, że dane treningowe chatbota zawierają zbyt mało przykładów związanych z fakturowaniem i wymagają uzupełnienia w tym obszarze.
| Metryka | Definicja | Wzór obliczeniowy | Wpływ biznesowy |
|---|---|---|---|
| True Positives (TP) | Poprawne odpowiedzi na prawidłowe zapytania | Liczone bezpośrednio | Buduje zaufanie klienta |
| True Negatives (TN) | Poprawne odrzucenie pytań spoza zakresu | Liczone bezpośrednio | Zapobiega dezinformacji |
| False Positives (FP) | Udzielone błędne odpowiedzi | Liczone bezpośrednio | Szkodzi wiarygodności |
| False Negatives (FN) | Pominięte okazje do pomocy | Liczone bezpośrednio | Obniża satysfakcję |
| Precyzja | Jakość pozytywnych predykcji | TP / (TP + FP) | Wskaźnik niezawodności |
| Recall | Pokrycie rzeczywistych pozytywów | TP / (TP + FN) | Wskaźnik kompletności |
| Dokładność | Ogólna poprawność | (TP + TN) / Całość | Ogólna wydajność |
Dokładność odpowiedzi mierzy, jak często chatbot udziela faktycznie poprawnych informacji, które bezpośrednio odnoszą się do zapytania użytkownika. Obejmuje to nie tylko dopasowanie wzorców, ale także ocenę, czy treść jest prawdziwa, aktualna i odpowiednia do kontekstu. Procesy przeglądu manualnego polegają na tym, że oceniający ludzie analizują losową próbkę konwersacji, porównując odpowiedzi chatbota z predefiniowaną bazą wiedzy. Automatyczne metody porównawcze można wdrożyć za pomocą technik przetwarzania języka naturalnego, dopasowując odpowiedzi do oczekiwanych zapisów w systemie, choć wymagają one starannej kalibracji, by uniknąć fałszywych negatywów, gdy chatbot udziela poprawnej odpowiedzi innymi słowami niż wzorcowa.
Trafność odpowiedzi ocenia, czy odpowiedź chatbota rzeczywiście odnosi się do tego, o co pytał użytkownik, nawet jeśli nie jest idealnie poprawna. Ten wymiar obejmuje sytuacje, w których chatbot dostarcza pomocnych informacji, które, choć nie są dosłowną odpowiedzią, prowadzą rozmowę w kierunku rozwiązania problemu. Metody oparte na NLP, takie jak podobieństwo cosinusowe, mogą mierzyć semantyczne podobieństwo między pytaniem a odpowiedzią, dając automatyczny wynik trafności. Mechanizmy opinii użytkowników, takie jak oceny „kciuk w górę/w dół” po każdej interakcji, dostarczają bezpośredniej oceny trafności przez najważniejsze osoby — Twoich klientów. Te sygnały powinny być stale zbierane i analizowane, by identyfikować typy zapytań, z którymi chatbot radzi sobie dobrze lub słabo.
Wskaźnik satysfakcji klienta (CSAT) mierzy zadowolenie użytkowników z interakcji z chatbotem poprzez bezpośrednie ankiety, zwykle w skali 1-5 lub proste oceny satysfakcji. Po każdej interakcji użytkownicy proszeni są o ocenę, co daje natychmiastową informację zwrotną, czy chatbot spełnił ich oczekiwania. Wyniki CSAT powyżej 80% oznaczają zwykle wysoką wydajność, a poniżej 60% sygnalizują poważne problemy wymagające analizy. Zaletą CSAT jest prostota i bezpośredniość — użytkownicy wyraźnie określają swoje zadowolenie — ale wynik może być też zależny od innych czynników, jak złożoność problemu czy oczekiwania klienta.
Net Promoter Score mierzy prawdopodobieństwo polecenia chatbota innym, pytając: „Na ile prawdopodobne jest, że polecisz tego chatbota współpracownikowi?” w skali 0-10. Osoby oceniające 9-10 to promotorzy, 7-8 to neutralni, 0-6 to krytycy. NPS = (Promotorzy - Krytycy) / Liczba respondentów × 100. Metryka ta silnie koreluje z długoterminową lojalnością klientów i pokazuje, czy chatbot tworzy pozytywne doświadczenia, którymi użytkownicy chcą się dzielić. NPS powyżej 50 jest uznawany za doskonały, a wynik ujemny oznacza poważne problemy z wydajnością.
Analiza sentymentu bada emocjonalny ton wiadomości użytkownika przed i po interakcji z chatbotem, by ocenić zadowolenie. Zaawansowane techniki NLP klasyfikują wiadomości jako pozytywne, neutralne lub negatywne, ujawniając, czy użytkownicy są po rozmowie bardziej zadowoleni czy sfrustrowani. Pozytywna zmiana sentymentu oznacza, że chatbot skutecznie rozwiązał problem, zaś negatywna — że mógł zirytować lub nie sprostać oczekiwaniom użytkownika. Metryka ta uchwyca aspekty emocjonalne, które są pomijane przez tradycyjne wskaźniki dokładności, dając cenny kontekst do zrozumienia jakości doświadczenia użytkownika.
Wskaźnik rozwiązania przy pierwszym kontakcie mierzy procent spraw klientów rozwiązanych przez chatbota bez konieczności eskalacji do konsultanta. Metryka ta bezpośrednio wpływa na efektywność operacyjną i zadowolenie klientów, którzy wolą rozwiązywać sprawy natychmiast niż być przekierowywani do człowieka. Wskaźniki FCR powyżej 70% świadczą o wysokiej wydajności chatbota, a poniżej 50% sugerują brak wiedzy lub kompetencji do obsługi typowych zapytań. Monitorowanie FCR według kategorii problemu pokazuje, z czym chatbot radzi sobie dobrze, a co wymaga wsparcia człowieka, wskazując obszary do rozwoju bazy wiedzy i szkoleń.
Wskaźnik eskalacji mierzy, jak często chatbot przekazuje rozmowę do konsultanta, a częstotliwość fallback śledzi, jak często chatbot udziela ogólnych odpowiedzi typu „Nie rozumiem” lub „Proszę przeformułować pytanie”. Wysoki wskaźnik eskalacji (powyżej 30%) wskazuje na niedobór wiedzy lub pewności chatbota w wielu sytuacjach, a wysoka częstotliwość fallback sugeruje słabe rozpoznawanie intencji lub niewystarczające dane treningowe. Metryki te pozwalają zidentyfikować konkretne luki w możliwościach chatbota, które można uzupełnić przez rozbudowę bazy wiedzy, ponowne treningi modelu lub usprawnienie komponentów rozumienia języka naturalnego.
Czas odpowiedzi mierzy, jak szybko chatbot reaguje na wiadomości użytkownika, zwykle w milisekundach lub sekundach. Użytkownicy oczekują niemal natychmiastowych reakcji; opóźnienia powyżej 3-5 sekund znacząco obniżają satysfakcję. Czas obsługi mierzy cały okres od momentu kontaktu użytkownika do rozwiązania sprawy lub eskalacji, pokazując efektywność chatbota. Krótszy czas obsługi oznacza szybkie zrozumienie i rozwiązanie problemu, a dłuższy — konieczność wielokrotnych wyjaśnień lub trudności z obsługą złożonych spraw. Metryki te należy śledzić osobno dla różnych kategorii problemów, ponieważ skomplikowane kwestie techniczne wymagają naturalnie dłuższej obsługi niż proste pytania FAQ.
LLM As a Judge to zaawansowana metoda oceny, w której jeden duży model językowy ocenia jakość odpowiedzi innego systemu AI. Metodyka ta jest szczególnie skuteczna do oceny odpowiedzi chatbota jednocześnie pod wieloma względami: dokładności, trafności, spójności, płynności, bezpieczeństwa, kompletności i tonu. Badania pokazują, że sędziowie LLM mogą osiągnąć do 85% zgodności z ocenami ludzkimi, co czyni je skalowalną alternatywą dla manualnych przeglądów. Proces polega na zdefiniowaniu konkretnych kryteriów oceny, przygotowaniu szczegółowych promptów z przykładami, przekazaniu sędziemu zarówno oryginalnego zapytania użytkownika, jak i odpowiedzi chatbota oraz otrzymaniu uporządkowanych ocen lub szczegółowych opisów.
Proces LLM As a Judge zwykle wykorzystuje dwa podejścia: ocenę pojedynczych odpowiedzi (referenceless — bez wzorca lub referencyjną — w porównaniu do oczekiwanej odpowiedzi) oraz porównania parami, gdzie sędzia wskazuje lepszą z dwóch odpowiedzi. Elastyczność ta pozwala oceniać zarówno absolutną jakość, jak i porównywać różne wersje lub konfiguracje chatbota. Platforma FlowHunt obsługuje wdrożenia LLM As a Judge poprzez swój interfejs drag-and-drop, integracje z wiodącymi LLM jak ChatGPT i Claude oraz toolkit CLI do raportowania i automatycznych ocen.
Poza podstawowymi obliczeniami dokładności, szczegółowa analiza macierzy pomyłek ujawnia konkretne wzorce niepowodzeń chatbota. Analiza, które typy zapytań powodują false positives a które false negatives, pozwala wykryć systematyczne słabości. Na przykład, jeśli macierz pokazuje, że chatbot często myli pytania o faktury z problemami technicznymi, oznacza to brak równowagi danych treningowych lub problem z rozpoznawaniem intencji w domenie fakturowej. Tworzenie osobnych macierzy dla różnych kategorii problemów umożliwia precyzyjne ulepszenia zamiast ogólnego ponownego treningu modelu.
Testy A/B porównują różne wersje chatbota, aby określić, która z nich lepiej wypada pod kluczowymi względami. Może to obejmować testowanie różnych szablonów odpowiedzi, konfiguracji bazy wiedzy czy samych modeli językowych. Poprzez losowe kierowanie części ruchu do każdej wersji i porównywanie takich metryk jak FCR, CSAT czy dokładność odpowiedzi, możesz podejmować decyzje oparte na danych odnośnie wdrażania ulepszeń. Testy A/B powinny trwać wystarczająco długo, by objąć naturalną zmienność zapytań i zapewnić istotność statystyczną wyników.
FlowHunt oferuje zintegrowaną platformę do budowania, wdrażania i oceniania chatbotów AI w helpdesku z zaawansowanymi możliwościami pomiaru dokładności. Wizualny kreator platformy pozwala osobom nietechnicznym tworzyć rozbudowane przepływy chatbota, a komponenty AI integrują się z czołowymi modelami językowymi jak ChatGPT i Claude. Zestaw narzędzi FlowHunt wspiera wdrożenia metodyki LLM As a Judge, umożliwiając definiowanie własnych kryteriów oceny i automatyczną ocenę wydajności chatbota na podstawie całej bazy konwersacji.
Aby wdrożyć kompleksowy pomiar dokładności z FlowHunt, zacznij od określenia własnych kryteriów oceny zgodnych z celami biznesowymi — czy priorytetem jest dokładność, szybkość, satysfakcja użytkownika czy wskaźnik rozwiązań. Skonfiguruj oceniający LLM na platformie, przygotowując szczegółowe prompt-y z przykładami odpowiedzi wysokiej i niskiej jakości. Załaduj bazę konwersacji lub podłącz ruch na żywo, a następnie przeprowadź ocenę, by uzyskać szczegółowe raporty dla wszystkich metryk. Dashboard FlowHunt zapewnia bieżący wgląd w wydajność chatbota, umożliwiając szybkie wykrywanie problemów i weryfikację usprawnień.
Ustal punkt odniesienia przed wdrażaniem usprawnień, aby mieć bazę dla oceny ich skutków. Zbieraj metryki ciągle, a nie okresowo, by wcześnie wykrywać pogorszenie wydajności spowodowane dryfem danych lub spadkiem jakości modelu. Wdrażaj pętle zwrotne, w których oceny użytkowników i poprawki automatycznie zasilają proces treningowy, stale podnosząc dokładność chatbota. Segmentuj metryki według kategorii problemu, typu użytkownika i okresu, by wychwycić obszary wymagające uwagi, zamiast polegać wyłącznie na statystykach ogólnych.
Zadbaj, by zestaw danych oceny odzwierciedlał rzeczywiste zapytania użytkowników i oczekiwane odpowiedzi, unikając sztucznych przypadków testowych nieodzwierciedlających faktycznego użytkowania. Regularnie weryfikuj metryki automatyczne z oceną ludzką przez manualną ocenę próbek rozmów, by utrzymać kalibrację systemu pomiarowego. Dokumentuj dokładnie metodologię i definicje metryk, zapewniając spójność ocen w czasie i przejrzystość komunikacji wyników dla interesariuszy. Na koniec, ustal cele wydajnościowe dla każdej metryki zgodnie z celami biznesowymi, by stworzyć odpowiedzialność za stały rozwój i jasne cele do optymalizacji.
Zaawansowana platforma automatyzacji AI FlowHunt pomaga tworzyć, wdrażać i oceniać wysokowydajne chatboty helpdesku z wbudowanymi narzędziami do pomiaru dokładności oraz oceną opartą o LLM.
Poznaj sprawdzone metody weryfikacji autentyczności chatbotów AI w 2025 roku. Odkryj techniczne techniki weryfikacji, kontrole bezpieczeństwa i najlepsze prakty...
Poznaj znaczenie dokładności i stabilności modeli AI w uczeniu maszynowym. Dowiedz się, jak te metryki wpływają na zastosowania takie jak wykrywanie oszustw, di...
Poznaj kompleksowe strategie testowania chatbotów AI, obejmujące testy funkcjonalne, wydajnościowe, bezpieczeństwa i użyteczności. Odkryj najlepsze praktyki, na...