Insight Engine
Dowiedz się, czym jest Insight Engine — zaawansowana platforma oparta na AI, która usprawnia wyszukiwanie i analizę danych dzięki zrozumieniu kontekstu i intenc...
10 min czytania
AI
Insight Engine
+5

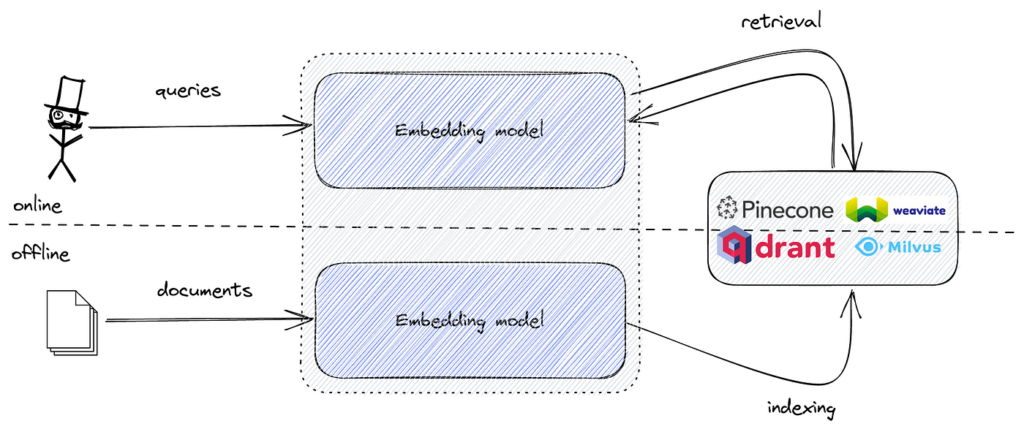
Wyszukiwanie AI wykorzystuje uczenie maszynowe i wektorowe embeddings do rozumienia intencji i kontekstu wyszukiwania, dostarczając bardzo trafne wyniki wykraczające poza dokładne dopasowania słów kluczowych.
Wyszukiwanie AI wykorzystuje uczenie maszynowe do zrozumienia kontekstu i intencji zapytań użytkownika, przekształcając je w numeryczne wektory dla uzyskania dokładniejszych wyników. W przeciwieństwie do tradycyjnego wyszukiwania po słowach kluczowych, Wyszukiwanie AI interpretuje relacje semantyczne, dzięki czemu jest skuteczne dla różnych typów danych i języków.
Wyszukiwanie AI, często nazywane semantycznym lub wektorowym, to metodologia wyszukiwania, która wykorzystuje modele uczenia maszynowego do rozumienia intencji i kontekstowego znaczenia zapytań. Zamiast tradycyjnego dopasowywania słów kluczowych, wyszukiwanie AI przekształca dane i zapytania w numeryczne reprezentacje, tzw. wektory lub embeddings. Pozwala to silnikowi wyszukiwania rozumieć relacje semantyczne pomiędzy różnymi fragmentami danych, dostarczając bardziej trafne i dokładne wyniki nawet wtedy, gdy nie występują dokładne słowa kluczowe.
Wyszukiwanie AI stanowi znaczący krok naprzód w technologiach wyszukiwania. Tradycyjne wyszukiwarki polegają głównie na dopasowywaniu słów kluczowych, gdzie obecność konkretnych terminów w zapytaniu i dokumentach decyduje o trafności. Jednak Wyszukiwanie AI wykorzystuje modele uczenia maszynowego do uchwycenia głębszego kontekstu i znaczenia zapytań oraz danych.
Poprzez konwersję tekstu, obrazów, dźwięku i innych nieustrukturyzowanych danych do wysokowymiarowych wektorów, Wyszukiwanie AI może mierzyć podobieństwo pomiędzy różnymi treściami. Takie podejście pozwala na dostarczanie wyników kontekstowo trafnych, nawet jeśli nie zawierają one dokładnych słów użytych w zapytaniu.
Kluczowe elementy:
Sednem Wyszukiwania AI jest koncepcja embeddings wektorowych. Są to numeryczne reprezentacje danych, które oddają semantyczne znaczenie tekstu, obrazów lub innych typów danych. Embeddings umieszczają podobne dane blisko siebie w wielowymiarowej przestrzeni wektorowej.
Jak to działa:
Przykład:
Tradycyjne wyszukiwarki oparte na słowach kluczowych działają poprzez dopasowanie terminów z zapytania do dokumentów zawierających te same słowa. Opierają się na indeksach odwróconych i częstotliwości występowania słów do ustalania trafności wyników.
Ograniczenia wyszukiwania po słowach kluczowych:
Zalety Wyszukiwania AI:
| Aspekt | Wyszukiwanie po słowach kluczowych | Wyszukiwanie AI (semantyczne/wektorowe) |
|---|---|---|
| Dopasowanie | Dokładne dopasowania słów kluczowych | Podobieństwo semantyczne |
| Świadomość kontekstu | Ograniczona | Wysoka |
| Obsługa synonimów | Wymaga ręcznych list synonimów | Automatyczna przez embeddings |
| Literówki | Może zawodzić bez „fuzzy search” | Bardziej tolerancyjne dzięki kontekstowi |
| Rozumienie intencji | Minimalne | Znaczące |
Wyszukiwanie semantyczne to kluczowa aplikacja Wyszukiwania AI, skupiająca się na rozumieniu intencji użytkownika i kontekstu zapytania.
Proces:
Kluczowe techniki:
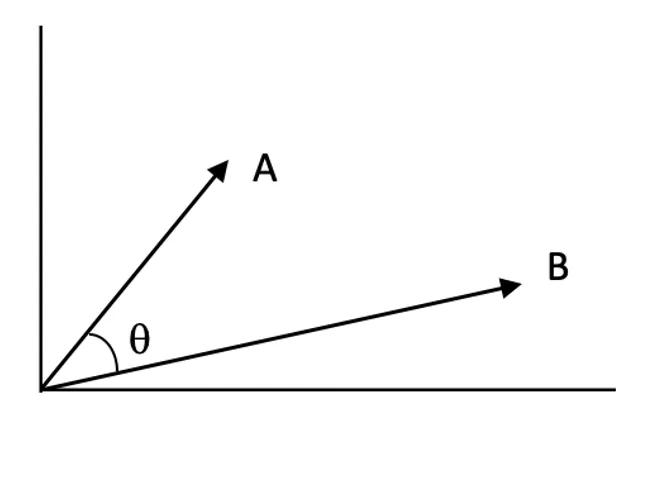
Wyniki podobieństwa:
Wyniki podobieństwa określają, jak bardzo dwa wektory są do siebie zbliżone w przestrzeni wektorowej. Wyższy wynik oznacza większą trafność pomiędzy zapytaniem a dokumentem.
Algorytmy Approximate Nearest Neighbor (ANN):
Znalezienie dokładnych najbliższych sąsiadów w wysokowymiarowych przestrzeniach jest bardzo kosztowne obliczeniowo. Algorytmy ANN umożliwiają szybkie przybliżone wyszukiwanie.
Wyszukiwanie AI otwiera szerokie spektrum zastosowań w różnych branżach dzięki zdolności rozumienia i interpretacji danych poza prostym dopasowaniem słów kluczowych.
Opis: Wyszukiwanie semantyczne poprawia doświadczenie użytkownika, interpretując intencję i dostarczając kontekstowo trafne wyniki.
Przykłady:
Opis: Dzięki rozumieniu preferencji i zachowań użytkownika, Wyszukiwanie AI może sugerować spersonalizowane treści lub produkty.
Przykłady:
Opis: Wyszukiwanie AI pozwala na precyzyjne odpowiadanie na zapytania użytkownika, wyciągając informacje z dokumentów.
Przykłady:
Opis: Wyszukiwanie AI indeksuje i przeszukuje nieustrukturyzowane dane, takie jak obrazy, dźwięki czy filmy poprzez zamianę ich na embeddings.
Przykłady:
Integracja Wyszukiwania AI z automatyzacją i chatbotami znacząco zwiększa ich możliwości.
Korzyści:
Kroki wdrożenia:
Przykład zastosowania:
Pomimo licznych zalet, Wyszukiwanie AI wiąże się z pewnymi wyzwaniami:
Strategie łagodzące:
Wyszukiwanie semantyczne i wektorowe w AI stało się silną alternatywą dla tradycyjnego wyszukiwania po słowach kluczowych i rozmytego, znacznie poprawiając trafność i dokładność wyników dzięki zrozumieniu kontekstu i znaczenia zapytań.
Podczas wdrażania wyszukiwania semantycznego, dane tekstowe są konwertowane na embeddings wektorowe oddające znaczenie tekstu. Te embeddings to wielowymiarowe reprezentacje numeryczne. Aby efektywnie przeszukiwać te embeddings i znaleźć najbardziej podobne do embeddingu zapytania, potrzebujemy narzędzia zoptymalizowanego pod kątem wyszukiwania podobieństwa w wysokich wymiarach.
FAISS dostarcza odpowiednich algorytmów i struktur danych do realizacji tego zadania. Łącząc embeddings semantyczne z FAISS, możemy zbudować wydajny silnik wyszukiwania semantycznego obsługujący duże zbiory danych z niskim opóźnieniem.
Wdrożenie wyszukiwania semantycznego z FAISS w Pythonie obejmuje kilka etapów:
Przejdźmy przez każdy etap szczegółowo.
Przygotuj swój zbiór danych (np. artykuły, zgłoszenia, opisy produktów).
Przykład:
documents = [
"Jak zresetować hasło na naszej platformie.",
"Rozwiązywanie problemów z łącznością sieciową.",
"Przewodnik po instalacji aktualizacji oprogramowania.",
"Najlepsze praktyki tworzenia kopii zapasowych i odzyskiwania danych.",
"Konfiguracja uwierzytelniania dwuskładnikowego dla większego bezpieczeństwa."
]
Wyczyść i sformatuj dane tekstowe w razie potrzeby.
Przekonwertuj dane tekstowe na embeddingi wektorowe z użyciem pretrenowanych modeli Transformer (np. z Hugging Face: transformers lub sentence-transformers).
Przykład:
from sentence_transformers import SentenceTransformer
import numpy as np
# Załaduj pretrenowany model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Wygeneruj embeddingi dla wszystkich dokumentów
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32, jak tego wymaga FAISS.Stwórz indeks FAISS do przechowywania embeddingów i efektywnego wyszukiwania podobieństwa.
Przykład:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 realizuje wyszukiwanie brute-force z użyciem odległości L2 (euklidesowej).Przekształć zapytanie użytkownika w embedding i znajdź najbliższych sąsiadów.
Przykład:
query = "Jak zmienić hasło do konta?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Użyj indeksów do wyświetlenia najbardziej trafnych dokumentów.
Przykład:
print("Najlepsze wyniki dla Twojego zapytania:")
for idx in indices[0]:
print(documents[idx])
Przewidywany wynik:
Najlepsze wyniki dla Twojego zapytania:
Jak zresetować hasło na naszej platformie.
Konfiguracja uwierzytelniania dwuskładnikowego dla większego bezpieczeństwa.
Najlepsze praktyki tworzenia kopii zapasowych i odzyskiwania danych.
FAISS udostępnia różne typy indeksów:
Użycie indeksu odwróconych plików (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalizacja i wyszukiwanie z użyciem iloczynu wewnętrznego:
Użycie cosinusa podobieństwa może być skuteczniejsze dla danych tekstowych
Wyszukiwanie AI to nowoczesna metodologia wyszukiwania, która wykorzystuje uczenie maszynowe i wektorowe embeddings do rozumienia intencji i kontekstu zapytań, dostarczając dokładniejsze i trafniejsze wyniki niż tradycyjne wyszukiwanie oparte na słowach kluczowych.
W przeciwieństwie do wyszukiwania opartego na słowach kluczowych, które polega na dokładnych dopasowaniach, Wyszukiwanie AI interpretuje semantyczne powiązania i intencję w zapytaniach, co czyni je skutecznym dla języka naturalnego i niejednoznacznych wejść.
Embeddings wektorowe to numeryczne reprezentacje tekstu, obrazów lub innych typów danych, które odzwierciedlają ich semantyczne znaczenie, umożliwiając silnikowi wyszukiwania mierzenie podobieństwa i kontekstu między różnymi danymi.
Wyszukiwanie AI napędza wyszukiwanie semantyczne w e-commerce, personalizowane rekomendacje w streamingach, systemy pytanie-odpowiedź w obsłudze klienta, przeglądanie danych nieustrukturyzowanych i wyszukiwanie dokumentów w badaniach oraz przedsiębiorstwach.
Popularne narzędzia to FAISS do efektywnego wyszukiwania podobieństwa wektorów oraz bazy danych wektorowych, takie jak Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch i Pgvector do skalowalnego przechowywania i pobierania embeddings.
Dzięki integracji Wyszukiwania AI chatboty i systemy automatyzacji mogą lepiej rozumieć zapytania użytkowników, pobierać kontekstowo trafne odpowiedzi i dostarczać dynamiczne, spersonalizowane reakcje.
Wyzwania to wysokie wymagania obliczeniowe, złożoność interpretacji modeli, potrzeba wysokiej jakości danych oraz zapewnienie prywatności i bezpieczeństwa informacji wrażliwych.
FAISS to otwartoźródłowa biblioteka do wydajnego wyszukiwania podobieństwa w embeddingach wektorowych o wysokiej liczbie wymiarów, szeroko stosowana do budowy semantycznych silników wyszukiwania obsługujących duże zbiory danych.
Odkryj, jak semantyczne wyszukiwanie oparte na AI może zmienić Twoje procesy wyszukiwania informacji, chatboty i workflow automatyzacji.
Dowiedz się, czym jest Insight Engine — zaawansowana platforma oparta na AI, która usprawnia wyszukiwanie i analizę danych dzięki zrozumieniu kontekstu i intenc...
Wyszukiwanie informacji wykorzystuje AI, NLP i uczenie maszynowe do efektywnego i dokładnego pozyskiwania danych spełniających wymagania użytkownika. Stanowiąc ...
Perplexity AI to zaawansowana wyszukiwarka oparta na sztucznej inteligencji oraz narzędzie konwersacyjne, które wykorzystuje NLP i uczenie maszynowe do dostarcz...