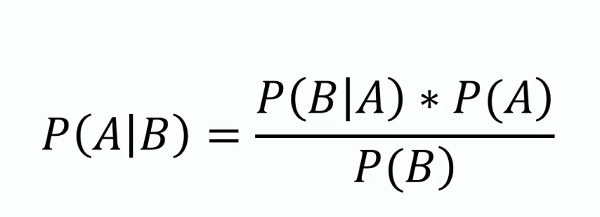
Sieci bayesowskie
Sieć bayesowska (BN) to probabilistyczny model grafowy, który reprezentuje zmienne i ich zależności warunkowe za pomocą skierowanego acyklicznego grafu (DAG). S...
3 min czytania
Bayesian Networks
AI
+3
Naive Bayes to prosta, lecz potężna rodzina algorytmów klasyfikacyjnych wykorzystujących twierdzenie Bayesa, powszechnie używana do skalowalnych zadań, takich jak wykrywanie spamu i klasyfikacja tekstu.
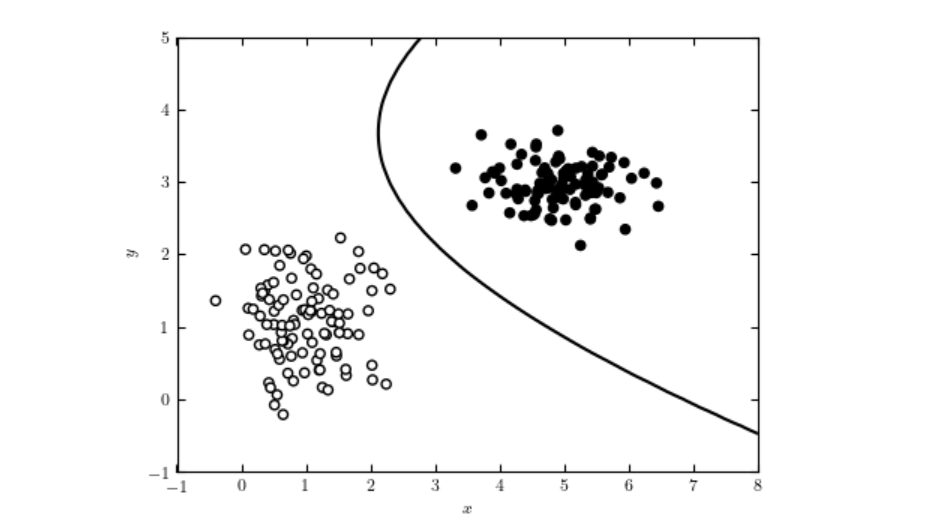
Naive Bayes to rodzina prostych, a zarazem skutecznych algorytmów klasyfikacyjnych opartych na twierdzeniu Bayesa, zakładających niezależność warunkową między cechami. Jest szeroko wykorzystywany do filtrowania spamu, klasyfikacji tekstu i wielu innych zastosowań ze względu na swoją prostotę i skalowalność.
Naive Bayes to rodzina algorytmów klasyfikacyjnych opartych na twierdzeniu Bayesa, wykorzystujących zasadę prawdopodobieństwa warunkowego. Określenie „naive” odnosi się do uproszczonego założenia, że wszystkie cechy w zbiorze danych są niezależne warunkowo względem siebie, przy zadanej etykiecie klasy. Pomimo że to założenie często jest naruszane w rzeczywistych danych, klasyfikatory Naive Bayes są cenione za prostotę i skuteczność w różnych zastosowaniach, takich jak klasyfikacja tekstu czy wykrywanie spamu.
Twierdzenie Bayesa
To twierdzenie stanowi podstawę Naive Bayes, umożliwiając aktualizację oszacowania prawdopodobieństwa hipotezy w miarę pojawiania się nowych dowodów lub informacji. Matematycznie wyraża się jako:
gdzie ( P(A|B) ) to prawdopodobieństwo a posteriori, ( P(B|A) ) to wiarygodność, ( P(A) ) to prawdopodobieństwo a priori, a ( P(B) ) to dowód.
Niezależność warunkowa
Naiwne założenie, że każda cecha jest niezależna od pozostałych cech przy zadanej etykiecie klasy. To uproszczenie znacząco ułatwia obliczenia i pozwala skalować algorytm do dużych zbiorów danych.
Prawdopodobieństwo a posteriori
Prawdopodobieństwo przydzielenia danej etykiety klasy na podstawie wartości cech, wyliczane przy użyciu twierdzenia Bayesa. Jest to kluczowy element procesu predykcji w Naive Bayes.
Rodzaje klasyfikatorów Naive Bayes
Klasyfikatory Naive Bayes działają poprzez wyznaczenie prawdopodobieństwa a posteriori dla każdej klasy na podstawie zestawu cech i wybór klasy o najwyższym prawdopodobieństwie. Proces obejmuje następujące kroki:
Klasyfikatory Naive Bayes są szczególnie skuteczne w następujących zastosowaniach:
Rozważmy zastosowanie Naive Bayes w filtrze spamu. Dane treningowe to e-maile oznaczone jako „spam” lub „nie-spam”. Każdy e-mail reprezentowany jest przez zestaw cech, takich jak obecność określonych słów. Podczas treningu algorytm wyznacza prawdopodobieństwo wystąpienia danego słowa w danej klasie. Dla nowej wiadomości algorytm oblicza prawdopodobieństwa a posteriori dla „spamu” i „nie-spamu” i przypisuje tę klasę, która ma wyższe prawdopodobieństwo.
Klasyfikatory Naive Bayes mogą być integrowane z systemami AI i chatbotami w celu ulepszenia przetwarzania języka naturalnego i interakcji człowiek-komputer. Na przykład mogą służyć do wykrywania intencji w zapytaniach użytkowników, klasyfikacji tekstu do określonych kategorii czy filtrowania nieodpowiednich treści. Taka funkcjonalność poprawia jakość oraz trafność rozwiązań opartych o AI. Dodatkowo, efektywność algorytmu sprawia, że nadaje się on do zastosowań w czasie rzeczywistym, co jest ważne w automatyzacji i systemach chatbotowych.
Naive Bayes to rodzina prostych, lecz potężnych algorytmów probabilistycznych opartych na twierdzeniu Bayesa z silnym założeniem niezależności cech. Jest szeroko stosowany w zadaniach klasyfikacyjnych ze względu na swoją prostotę i skuteczność. Oto kilka publikacji naukowych omawiających różne zastosowania i usprawnienia klasyfikatora Naive Bayes:
Improving spam filtering by combining Naive Bayes with simple k-nearest neighbor searches
Autor: Daniel Etzold
Opublikowano: 30 listopada 2003
W pracy tej badano wykorzystanie Naive Bayes do klasyfikacji e-maili, podkreślając łatwość implementacji i wydajność. Autor prezentuje wyniki pokazujące, że połączenie Naive Bayes z wyszukiwaniem k-najbliższych sąsiadów może poprawić skuteczność filtrów antyspamowych. Połączenie to zapewniało niewielką poprawę przy dużej liczbie cech i znaczną przy mniejszej liczbie cech. Przeczytaj publikację.
Locally Weighted Naive Bayes
Autorzy: Eibe Frank, Mark Hall, Bernhard Pfahringer
Opublikowano: 19 października 2012
Artykuł ten dotyczy głównej słabości Naive Bayes, czyli założenia o niezależności cech. Autorzy przedstawiają lokalnie ważoną wersję Naive Bayes, która uczy się modeli lokalnych w momencie predykcji, tym samym łagodząc założenie niezależności. Wyniki eksperymentów pokazują, że podejście to rzadko obniża skuteczność, a często znacznie ją poprawia. Metoda ta jest doceniana za prostotę koncepcyjną i obliczeniową w porównaniu do innych technik. Przeczytaj publikację.
Naive Bayes Entrapment Detection for Planetary Rovers
Autor: Dicong Qiu
Opublikowano: 31 stycznia 2018
W pracy omówiono zastosowanie klasyfikatorów Naive Bayes do wykrywania zakleszczenia łazików planetarnych. Zdefiniowano kryteria zakleszczenia i pokazano, jak Naive Bayes może służyć do wykrywania takich sytuacji. Przedstawiono eksperymenty z łazikami AutoKrawler, prezentując skuteczność Naive Bayes w autonomicznych procedurach ratunkowych. Przeczytaj publikację.
Naive Bayes to rodzina algorytmów klasyfikacyjnych opartych na twierdzeniu Bayesa, zakładających niezależność warunkową wszystkich cech względem etykiety klasy. Jest szeroko stosowany do klasyfikacji tekstu, filtrowania spamu i analizy sentymentu.
Główne typy to: Gaussian Naive Bayes (dla cech ciągłych), Multinomial Naive Bayes (dla cech dyskretnych, takich jak liczba słów) oraz Bernoulli Naive Bayes (dla cech binarnych/boolean).
Naive Bayes jest prosty w implementacji, wydajny obliczeniowo, skalowalny do dużych zbiorów danych i dobrze radzi sobie z danymi o wysokiej wymiarowości.
Głównym ograniczeniem jest założenie niezależności cech, co często nie zachodzi w rzeczywistych danych. Może także przypisywać zerowe prawdopodobieństwo niewidzianym cechom, czemu można przeciwdziałać technikami takimi jak wygładzanie Laplace’a.
Naive Bayes znajduje zastosowanie w systemach AI i chatbotach do wykrywania intencji, klasyfikacji tekstu, filtrowania spamu oraz analizy sentymentu, zwiększając możliwości przetwarzania języka naturalnego i umożliwiając podejmowanie decyzji w czasie rzeczywistym.
Inteligentne chatboty i narzędzia AI w jednym miejscu. Połącz intuicyjne bloki i zamień pomysły w zautomatyzowane Flowy.
Sieć bayesowska (BN) to probabilistyczny model grafowy, który reprezentuje zmienne i ich zależności warunkowe za pomocą skierowanego acyklicznego grafu (DAG). S...
Klasyfikator AI to algorytm uczenia maszynowego, który przypisuje etykiety klas do danych wejściowych, kategoryzując informacje do zdefiniowanych wcześniej klas...
Model bazowy AI to wielkoskalowy model uczenia maszynowego trenowany na ogromnych ilościach danych, który można dostosować do szerokiej gamy zadań. Modele bazow...