
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) to zaawansowane ramy AI, które łączą tradycyjne systemy wyszukiwania informacji z generatywnymi dużymi modelami językowymi ...
3 min czytania
RAG
AI
+4

Odpowiadanie na pytania z RAG ulepsza LLM, integrując wyszukiwanie danych w czasie rzeczywistym i generowanie języka naturalnego dla precyzyjnych, kontekstowo trafnych odpowiedzi.
Odpowiadanie na pytania z wykorzystaniem Retrieval-Augmented Generation (RAG) ulepsza modele językowe poprzez integrację zewnętrznych danych w czasie rzeczywistym, zapewniając precyzyjne i trafne odpowiedzi. Optymalizuje to wydajność w dynamicznych dziedzinach, oferując lepszą dokładność, dynamiczną treść oraz zwiększoną trafność.
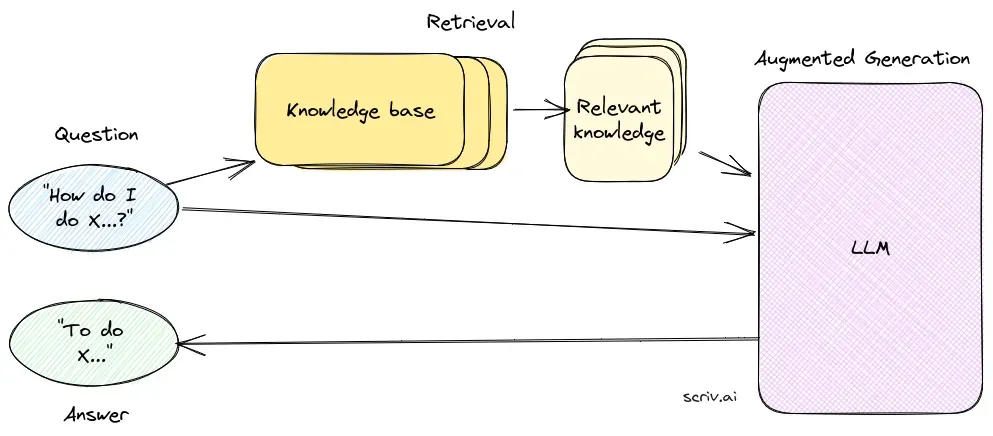
Odpowiadanie na pytania z Retrieval-Augmented Generation (RAG) to innowacyjna metoda, która łączy zalety wyszukiwania informacji i generowania języka naturalnego — tworzy tekst podobny do ludzkiego na podstawie danych, wzmacniając AI, chatboty, raporty oraz personalizując doświadczenia. To hybrydowe podejście zwiększa możliwości dużych modeli językowych (LLM) poprzez uzupełnianie ich odpowiedzi o odpowiednie, aktualne informacje pobrane z zewnętrznych źródeł danych. W przeciwieństwie do tradycyjnych metod opierających się wyłącznie na modelach wytrenowanych wcześniej, RAG dynamicznie integruje dane z zewnątrz, umożliwiając systemom udzielanie dokładniejszych i kontekstowo trafnych odpowiedzi, zwłaszcza w dziedzinach wymagających najnowszych informacji lub specjalistycznej wiedzy.
RAG optymalizuje wydajność LLM, zapewniając, że odpowiedzi są generowane nie tylko z wewnętrznego zbioru danych, ale także z wykorzystaniem autorytatywnych źródeł w czasie rzeczywistym. Takie podejście jest kluczowe w zadaniach odpowiadania na pytania w dynamicznych obszarach, gdzie informacje ciągle się zmieniają.
Komponent wyszukiwania odpowiada za pozyskiwanie odpowiednich informacji z rozległych zbiorów danych, zazwyczaj przechowywanych w bazie danych wektorowych. Wykorzystuje techniki wyszukiwania semantycznego do identyfikacji i ekstrakcji fragmentów tekstu lub dokumentów ściśle powiązanych z zapytaniem użytkownika.
Komponent generowania, zazwyczaj LLM taki jak GPT-3 lub BERT, syntetyzuje odpowiedź, łącząc oryginalne zapytanie użytkownika z pozyskanym kontekstem. Jest kluczowy do generowania spójnych i kontekstowo adekwatnych odpowiedzi.
Wdrożenie systemu RAG obejmuje kilka technicznych etapów:
Badania nad odpowiadaniem na pytania z Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) to metoda, która wzmacnia systemy odpowiadania na pytania przez połączenie mechanizmów wyszukiwania z modelami generatywnymi. Najnowsze badania obejmują skuteczność i optymalizację RAG w różnych kontekstach.
RAG to metoda łącząca wyszukiwanie informacji i generowanie języka naturalnego, aby dostarczać precyzyjne, aktualne odpowiedzi poprzez integrację zewnętrznych źródeł danych z dużymi modelami językowymi.
System RAG składa się z komponentu wyszukiwania, który pozyskuje odpowiednie informacje z baz danych wektorowych za pomocą wyszukiwania semantycznego, oraz komponentu generowania, zwykle LLM, który syntetyzuje odpowiedzi na podstawie zapytania użytkownika i znalezionego kontekstu.
RAG zwiększa dokładność dzięki pozyskiwaniu kontekstowo trafnych informacji, wspiera dynamiczną aktualizację treści z zewnętrznych baz wiedzy oraz poprawia trafność i jakość generowanych odpowiedzi.
Typowe zastosowania obejmują chatboty AI, wsparcie klienta, automatyczne tworzenie treści oraz narzędzia edukacyjne wymagające precyzyjnych, świadomych kontekstu i aktualnych odpowiedzi.
Systemy RAG mogą być zasobożerne, wymagają starannej integracji dla optymalnej wydajności i muszą zapewniać wiarygodność pozyskanych informacji, by uniknąć błędnych lub nieaktualnych odpowiedzi.
Dowiedz się, jak Retrieval-Augmented Generation może wzmocnić Twojego chatbota i rozwiązania wsparcia dzięki odpowiedziom w czasie rzeczywistym i wysokiej dokładności.
Retrieval Augmented Generation (RAG) to zaawansowane ramy AI, które łączą tradycyjne systemy wyszukiwania informacji z generatywnymi dużymi modelami językowymi ...
Poznaj kluczowe różnice między generowaniem wspomaganym wyszukiwaniem (RAG) a generowaniem wspomaganym pamięcią podręczną (CAG) w AI. Dowiedz się, jak RAG dynam...
Komponent GoogleSearch platformy FlowHunt zwiększa dokładność chatbotów, wykorzystując Retrieval-Augmented Generation (RAG) do pozyskiwania najnowszej wiedzy z ...