Czatbot RAG w czasie rzeczywistym dla konkretnej domeny
Czatbot w czasie rzeczywistym, który korzysta z wyszukiwarki Google ograniczonej do Twojej własnej domeny, pobiera odpowiednie treści z sieci i wykorzystuje Ope...
4 min czytania
Pipeline wyszukiwania informacji umożliwia chatbotom pobieranie i przetwarzanie odpowiedniej, zewnętrznej wiedzy, by dostarczać dokładne, aktualne i kontekstowe odpowiedzi z wykorzystaniem RAG, embeddingów i baz wektorowych.
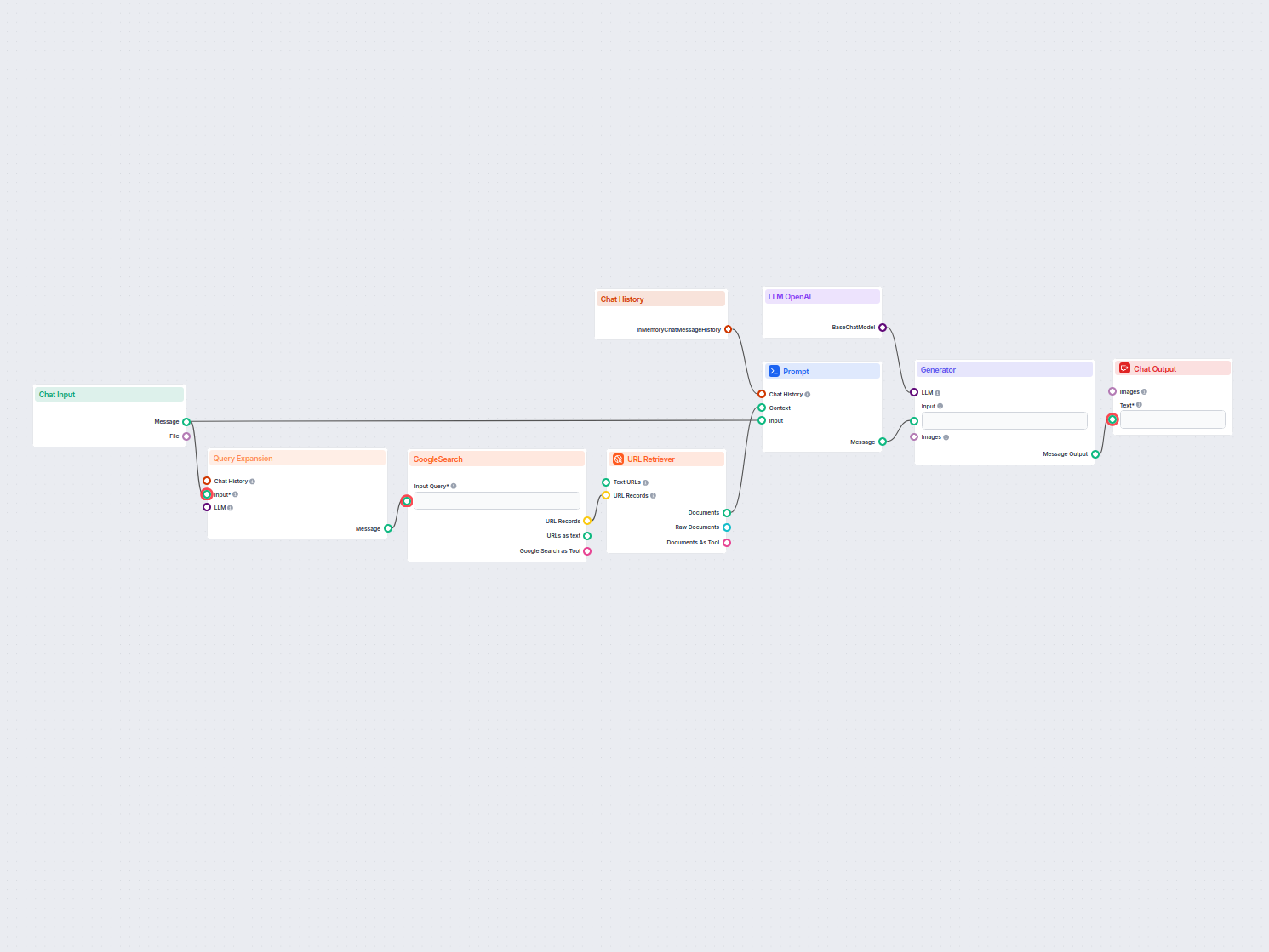
Pipeline wyszukiwania informacji dla chatbotów to techniczna architektura i proces, który umożliwia chatbotom pobieranie, przetwarzanie i wyszukiwanie odpowiednich informacji w odpowiedzi na zapytania użytkownika. W przeciwieństwie do prostych systemów pytanie-odpowiedź opartych wyłącznie na wytrenowanych wcześniej modelach językowych, pipeline’y wyszukiwania integrują zewnętrzne bazy wiedzy lub źródła danych. Dzięki temu chatbot może dostarczać dokładne, kontekstowo trafne i aktualne odpowiedzi również wtedy, gdy dane nie są wbudowane w sam model językowy.
Pipeline wyszukiwania zwykle składa się z wielu komponentów, m.in. pobierania danych, tworzenia embeddingów, przechowywania wektorowego, odnajdywania kontekstu oraz generowania odpowiedzi. W praktyce często wykorzystuje się Retrieval-Augmented Generation (RAG), które łączy zalety systemów wyszukiwania danych oraz dużych modeli językowych (LLM) przy generowaniu odpowiedzi.
Pipeline wyszukiwania zwiększa możliwości chatbota, umożliwiając mu:
Pobieranie dokumentów
Zbieranie i wstępne przetwarzanie surowych danych, takich jak PDF-y, pliki tekstowe, bazy danych czy API. Narzędzia takie jak LangChain lub LlamaIndex często ułatwiają bezproblemowe pobieranie danych.
Przykład: Załadowanie FAQ obsługi klienta lub specyfikacji produktów do systemu.
Wstępne przetwarzanie dokumentów
Długie dokumenty są dzielone na mniejsze, semantycznie spójne fragmenty. Jest to niezbędne do dopasowania tekstu do modeli embeddingów, które zwykle mają limity tokenów (np. 512 tokenów).
Przykładowy fragment kodu:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Generowanie embeddingów
Tekst zostaje przekształcony w wektorowe reprezentacje o wysokiej liczbie wymiarów przy użyciu modeli embeddingów. Embeddingi numerycznie kodują semantykę danych.
Przykład modelu embeddingu: OpenAI text-embedding-ada-002 lub Hugging Face e5-large-v2.
Przechowywanie wektorowe
Embeddingi są przechowywane w bazach wektorowych zoptymalizowanych pod kątem wyszukiwania podobieństwa. Popularne narzędzia to Milvus, Chroma lub PGVector.
Przykład: Przechowywanie opisów produktów i ich embeddingów w celu wydajnego wyszukiwania.
Przetwarzanie zapytań
Po otrzymaniu zapytania użytkownika jest ono przekształcane w wektor zapytania przy użyciu tego samego modelu embeddingu. Pozwala to na semantyczne dopasowanie z przechowywanymi embeddingami.
Przykładowy fragment kodu:
query_vector = embedding_model.encode("Jakie są specyfikacje Produktu X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Wyszukiwanie danych
System pobiera najbardziej trafne fragmenty danych na podstawie miar podobieństwa (np. cosinusowej). Wyspecjalizowane systemy mogą łączyć bazy SQL, grafy wiedzy i wyszukiwanie wektorowe dla pełniejszych rezultatów.
Generowanie odpowiedzi
Pobrane dane są łączone z zapytaniem użytkownika i przekazywane do dużego modelu językowego (LLM), który generuje ostateczną odpowiedź w języku naturalnym. Ten etap określa się często jako generowanie wspomagane (augmented generation).
Przykładowy szablon promptu:
prompt_template = """
Kontekst: {context}
Pytanie: {question}
Proszę udzielić szczegółowej odpowiedzi, korzystając z powyższego kontekstu.
"""
Walidacja i post-processing
Zaawansowane pipeline’y wyszukiwania obejmują wykrywanie halucynacji, ocenę trafności lub ocenianie odpowiedzi, by zapewnić faktograficzność i relewantność wyników.
Obsługa klienta
Chatboty mogą pobierać instrukcje obsługi, poradniki rozwiązywania problemów lub FAQ, by natychmiast odpowiadać na pytania klientów.
Przykład: Chatbot pomagający klientowi zresetować router na podstawie odpowiedniej sekcji instrukcji obsługi.
Zarządzanie wiedzą w firmie
Wewnętrzne chatboty mogą uzyskiwać dostęp do firmowych danych, takich jak polityki HR, dokumentacja IT czy wytyczne compliance.
Przykład: Pracownicy pytający chatbota o zasady zwolnień lekarskich.
E-commerce
Chatboty wspierają użytkowników, pobierając szczegóły produktów, recenzje czy informacje o dostępności.
Przykład: „Jakie są najważniejsze cechy Produktu Y?”
Opieka zdrowotna
Chatboty pobierają literaturę medyczną, wytyczne lub dane pacjenta, by wspierać profesjonalistów lub pacjentów.
Przykład: Chatbot pobierający ostrzeżenia o interakcjach leków z bazy farmaceutycznej.
Edukacja i badania
Akademickie chatboty wykorzystują pipeline’y RAG do wyszukiwania artykułów naukowych, odpowiadania na pytania lub podsumowywania wyników badań.
Przykład: „Czy możesz podsumować wyniki tego badania z 2023 roku na temat zmian klimatu?”
Prawo i compliance
Chatboty pobierają dokumenty prawne, orzecznictwo lub wymagania regulacyjne, by wspierać prawników.
Przykład: „Jakie są najnowsze zmiany w przepisach RODO?”
Chatbot zaprojektowany do odpowiadania na pytania na podstawie firmowego raportu finansowego w formacie PDF.
Chatbot łączący SQL, wyszukiwanie wektorowe i grafy wiedzy w celu odpowiedzi na pytanie pracownika.
Dzięki pipeline’om wyszukiwania chatboty nie są już ograniczone wyłącznie statycznymi danymi treningowymi, co pozwala im zapewniać dynamiczne, precyzyjne i bogate w kontekst interakcje.
Pipeline’y wyszukiwania odgrywają kluczową rolę we współczesnych systemach chatbotów, umożliwiając inteligentne i kontekstowe interakcje.
„Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” Pengfei Zhu i in. (2018)
Przedstawia Lingke, chatbota integrującego wyszukiwanie informacji do obsługi wieloetapowych konwersacji. Wykorzystuje precyzyjne przetwarzanie pipeline’owe do destylowania odpowiedzi z nieustrukturyzowanych dokumentów i stosuje uważne dopasowywanie kontekstu i odpowiedzi w interakcjach sekwencyjnych, znacząco poprawiając zdolność chatbota do rozwiązywania złożonych pytań użytkowników.
Przeczytaj publikację tutaj.
„FACTS About Building Retrieval Augmented Generation-based Chatbots” Rama Akkiraju i in. (2024)
Omawia wyzwania i metody budowy chatbotów klasy enterprise z użyciem pipeline’ów RAG i dużych modeli językowych (LLM). Autorzy proponują ramy FACTS, skupiając się na świeżości danych, architekturze, kosztach, testowaniu i bezpieczeństwie w inżynierii pipeline’ów RAG. Wyniki empiryczne pokazują kompromisy między dokładnością a opóźnieniem przy skalowaniu LLM-ów, dostarczając cennych wskazówek na temat budowy bezpiecznych i wydajnych chatbotów. Przeczytaj publikację tutaj.
„From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” Subash Neupane i in. (2024)
Przedstawia system BARKPLUG V.2 zaprojektowany dla środowisk uniwersyteckich. Wykorzystując pipeline’y RAG, system udziela dokładnych, dziedzinowych odpowiedzi na pytania dotyczące zasobów kampusu, poprawiając dostęp do informacji. Badanie ocenia skuteczność chatbota przy użyciu narzędzi takich jak RAG Assessment (RAGAS) i prezentuje jego użyteczność w środowisku akademickim. Przeczytaj publikację tutaj.
Pipeline wyszukiwania informacji to techniczna architektura, która pozwala chatbotom pobierać, przetwarzać i wyszukiwać istotne informacje z zewnętrznych źródeł w odpowiedzi na zapytania użytkowników. Łączy pobieranie danych, embeddingi, przechowywanie wektorowe i generowanie odpowiedzi przez LLM, umożliwiając dynamiczne, kontekstowe odpowiedzi.
RAG łączy zalety systemów wyszukiwania danych i dużych modeli językowych (LLM), pozwalając chatbotom opierać odpowiedzi na faktach i aktualnych zewnętrznych danych, co ogranicza halucynacje i zwiększa dokładność.
Kluczowe komponenty to pobieranie dokumentów, wstępne przetwarzanie, generowanie embeddingów, przechowywanie wektorowe, przetwarzanie zapytań, wyszukiwanie danych, generowanie odpowiedzi i walidacja końcowa.
Przykładami zastosowań są: obsługa klienta, zarządzanie wiedzą w firmie, informacje o produktach e-commerce, wsparcie medyczne, edukacja i badania naukowe oraz wsparcie w zakresie zgodności z przepisami.
Wyzwania obejmują opóźnienia związane z wyszukiwaniem w czasie rzeczywistym, koszty operacyjne, kwestie prywatności danych oraz wymagania skalowalności przy dużych wolumenach danych.
Odblokuj możliwości Retrieval-Augmented Generation (RAG) i integracji zewnętrznych danych, by dostarczać inteligentne i dokładne odpowiedzi chatbotów. Wypróbuj platformę FlowHunt bez kodowania już dziś.
Czatbot w czasie rzeczywistym, który korzysta z wyszukiwarki Google ograniczonej do Twojej własnej domeny, pobiera odpowiednie treści z sieci i wykorzystuje Ope...
Źródła wiedzy sprawiają, że nauczanie AI według Twoich potrzeb jest niezwykle proste. Odkryj wszystkie sposoby łączenia wiedzy z FlowHunt. Łatwo połącz strony i...
Odkryj szablon Prostego Chatbota z Google Search, zaprojektowany dla firm, aby efektywnie dostarczać informacje specyficzne dla danej domeny. Zwiększ satysfakcj...