Transformer
Model transformera to rodzaj sieci neuronowej zaprojektowanej specjalnie do obsługi danych sekwencyjnych, takich jak tekst, mowa czy dane szeregów czasowych. W ...
3 min czytania
Transformer
Neural Networks
+3
Transformatory to przełomowe sieci neuronowe wykorzystujące mechanizm samo-uwagi do równoległego przetwarzania danych, napędzające modele takie jak BERT i GPT w NLP, widzeniu komputerowym i nie tylko.
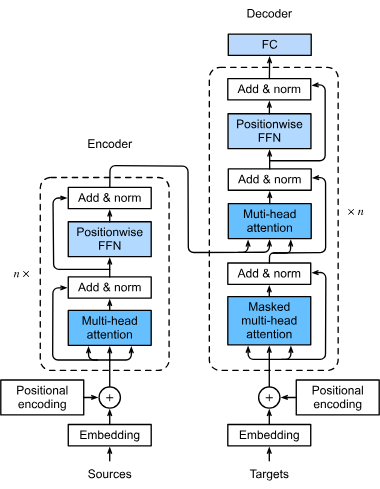
Pierwszym krokiem w przetwarzaniu przez model transformatorowy jest zamiana słów lub tokenów w sekwencji wejściowej na wektory liczbowe, zwane embeddingami. Embeddingi te oddają znaczenie semantyczne i są kluczowe dla zrozumienia relacji między tokenami przez model. Ta transformacja jest niezbędna, ponieważ pozwala modelowi przetwarzać dane tekstowe w formie matematycznej.
Transformatory nie przetwarzają danych w sposób sekwencyjny, dlatego do sekwencji wprowadza się kodowanie pozycyjne, aby przekazać informację o pozycji każdego tokena. To kluczowe dla zachowania kolejności, szczególnie w zadaniach takich jak tłumaczenie, gdzie kontekst zależy od kolejności słów.
Mechanizm wielogłowej uwagi to zaawansowany element transformatorów, pozwalający modelowi skupiać się na różnych częściach sekwencji wejściowej jednocześnie. Poprzez obliczanie wielu wag uwagi model wychwytuje różnorodne relacje i zależności w danych, przez co lepiej rozumie i generuje złożone wzorce.
Transformatory zazwyczaj przyjmują architekturę enkoder-dekoder:
Po mechanizmie uwagi dane przechodzą przez sieci neuronowe typu feedforward, które stosują nieliniowe transformacje, pomagając modelowi uczyć się złożonych wzorców. Tak przetworzone dane są dalej udoskonalane przez model, by uzyskać jak najlepszy wynik.
Techniki te są stosowane, by stabilizować i przyspieszać proces uczenia. Normalizacja warstw utrzymuje wyniki w odpowiednim zakresie, co ułatwia wydajny trening. Z kolei połączenia resztkowe (residual connections) pozwalają gradientom swobodnie przepływać przez sieć, co poprawia efektywność trenowania głębokich sieci neuronowych.
Transformatory operują na sekwencjach danych, którymi mogą być słowa w zdaniu lub inne informacje o charakterze sekwencyjnym. Stosują mechanizm samo-uwagi, aby określić istotność każdej części sekwencji względem innych, pozwalając modelowi skupić się na elementach kluczowych dla wyniku.
W samo-uwadze każdy token w sekwencji jest porównywany z każdym innym, by obliczyć wagi uwagi. Określają one znaczenie danego tokena w kontekście pozostałych, umożliwiając modelowi skupienie na najbardziej istotnych fragmentach. To kluczowe dla zrozumienia kontekstu i znaczenia w zadaniach językowych.
To podstawowe elementy modelu transformatorowego, składające się z warstw samo-uwagi i feedforward. Wiele takich bloków jest układanych jeden na drugim, tworząc głębokie modele zdolne do wychwytywania złożonych wzorców w danych. Ta modułowa konstrukcja pozwala efektywnie skalować transformatory wraz ze wzrostem złożoności zadania.
Transformatory są wydajniejsze od RNN i CNN, bo potrafią przetwarzać całe sekwencje jednocześnie. Ta efektywność umożliwia skalowanie do bardzo dużych modeli, takich jak GPT-3, mającego 175 miliardów parametrów. Skalowalność transformatorów pozwala im skutecznie obsługiwać ogromne ilości danych.
Tradycyjne modele mają trudności z zależnościami dalekosiężnymi z powodu sekwencyjności przetwarzania. Transformatory pokonują to ograniczenie dzięki samo-uwadze, która pozwala jednocześnie uwzględnić wszystkie części sekwencji. Dzięki temu są bardzo skuteczne w zadaniach wymagających rozumienia kontekstu w długich tekstach.
Choć początkowo zaprojektowane do NLP, transformatory zostały zaadaptowane do wielu innych zastosowań, w tym w widzeniu komputerowym, modelowaniu białek oraz prognozowaniu szeregów czasowych. Ta wszechstronność pokazuje szerokie możliwości wykorzystania transformatorów w różnych dziedzinach.
Transformatory znacząco poprawiły wyniki zadań NLP, takich jak tłumaczenie, podsumowywanie czy analiza sentymentu. Modele takie jak BERT i GPT wykorzystują architekturę transformatorową do rozumienia i generowania tekstu na poziomie zbliżonym do ludzkiego, ustanawiając nowe standardy w NLP.
W tłumaczeniach maszynowych transformatory sprawdzają się doskonale, rozumiejąc kontekst słów w zdaniu, co pozwala na dokładniejsze tłumaczenia niż wcześniejsze metody. Możliwość jednoczesnego przetwarzania całych zdań daje bardziej spójne i kontekstowo poprawne tłumaczenia.
Transformatory potrafią modelować sekwencje aminokwasów w białkach, pomagając w przewidywaniu ich struktur, co jest kluczowe dla odkrywania leków i zrozumienia procesów biologicznych. To zastosowanie podkreśla potencjał transformatorów w badaniach naukowych.
Adaptując architekturę transformatora, możliwe jest prognozowanie przyszłych wartości w szeregach czasowych, na przykład w prognozowaniu zapotrzebowania na energię elektryczną, na podstawie analiz wcześniejszych danych. Otwiera to nowe możliwości wykorzystania transformatorów w finansach czy zarządzaniu zasobami.
Modele BERT zostały zaprojektowane do rozumienia kontekstu słowa poprzez analizę otaczających go słów, dzięki czemu świetnie sprawdzają się w zadaniach wymagających rozpoznawania relacji w zdaniu. Podejście dwukierunkowe pozwala BERT-owi wychwytywać kontekst skuteczniej niż modele jednokierunkowe.
Modele GPT są autoregresyjne, generując tekst przez przewidywanie kolejnego słowa na podstawie poprzednich. Są szeroko stosowane w uzupełnianiu tekstu i generowaniu dialogów, pokazując zdolność do tworzenia wypowiedzi zbliżonych do ludzkich.
Początkowo rozwijane dla NLP, transformatory zostały zaadaptowane do zadań widzenia komputerowego. Vision Transformers przetwarzają dane obrazowe jako sekwencje, co pozwala stosować techniki transformatorowe do obrazów. To podejście przyczyniło się do postępu w rozpoznawaniu i przetwarzaniu obrazów.
Trenowanie dużych modeli transformatorowych wymaga ogromnych zasobów obliczeniowych, często obejmujących olbrzymie zbiory danych i wydajne układy GPU. Stanowi to wyzwanie pod względem kosztów i dostępności dla wielu organizacji.
Wraz z rosnącą popularnością transformatorów coraz większego znaczenia nabierają kwestie takie jak uprzedzenia w modelach AI czy etyczne wykorzystanie treści generowanej przez sztuczną inteligencję. Badacze opracowują metody minimalizowania tych problemów i zapewniania odpowiedzialnego rozwoju AI, podkreślając potrzebę ram etycznych w badaniach nad AI.
Wszechstronność transformatorów otwiera nowe możliwości badawcze i praktyczne, od usprawniania chatbotów AI po poprawę analizy danych w medycynie i finansach. Przyszłość transformatorów zapowiada ekscytujące innowacje w różnych branżach.
Podsumowując, transformatory stanowią znaczący przełom w technologii AI, oferując niezrównane możliwości przetwarzania danych sekwencyjnych. Ich innowacyjna architektura i wydajność ustanowiły nowy standard w branży, napędzając rozwój zastosowań AI na niespotykaną skalę. Niezależnie czy chodzi o zrozumienie języka, badania naukowe czy przetwarzanie obrazów, transformatory nieustannie redefiniują możliwości sztucznej inteligencji.
Transformatory zrewolucjonizowały dziedzinę sztucznej inteligencji, zwłaszcza w przetwarzaniu języka naturalnego i rozumieniu tekstu. Artykuł „AI Thinking: A framework for rethinking artificial intelligence in practice” autorstwa Denisa Newman-Griffis (opublikowany w 2024 roku) przedstawia nowatorskie ramy koncepcyjne zwane AI Thinking. Model ten opisuje kluczowe decyzje i aspekty stosowania AI z różnych perspektyw dyscyplinarnych, uwzględniając kompetencje motywowania użycia AI, formułowania metod sztucznej inteligencji oraz umieszczania AI w kontekście społeczno-technicznym. Celem jest przełamywanie barier między dyscyplinami akademickimi i kształtowanie przyszłości AI w praktyce. Czytaj więcej.
Kolejny istotny wkład stanowi praca „Artificial intelligence and the transformation of higher education institutions” autorstwa Evangelosa Katsamakasa i in. (opublikowana w 2024 roku), w której zastosowano podejście systemów złożonych do mapowania mechanizmów sprzężenia zwrotnego AI w szkolnictwie wyższym. Badanie omawia siły napędowe transformacji AI i jej wpływ na tworzenie wartości, podkreślając konieczność dostosowania się uczelni do postępu technologii AI przy jednoczesnym zachowaniu integralności akademickiej i zarządzaniu zmianami zatrudnienia. Czytaj więcej.
W obszarze rozwoju oprogramowania, artykuł „Can Artificial Intelligence Transform DevOps?” autorstwa Mamdouha Aleneziego i współautorów (opublikowany w 2022 roku) analizuje przecięcie AI i DevOps. Badanie pokazuje, jak AI może usprawnić procesy DevOps, ułatwiając efektywne dostarczanie oprogramowania. Podkreśla to praktyczne implikacje dla programistów i firm w zakresie wykorzystania AI do transformacji praktyk DevOps. Czytaj więcej
Transformatory to architektura sieci neuronowej wprowadzona w 2017 roku, która wykorzystuje mechanizmy samo-uwagi do równoległego przetwarzania sekwencyjnych danych. Zrewolucjonizowały one sztuczną inteligencję, szczególnie w przetwarzaniu języka naturalnego i widzeniu komputerowym.
W przeciwieństwie do RNN i CNN, transformatory przetwarzają wszystkie elementy sekwencji jednocześnie dzięki samo-uwadze, co zapewnia większą wydajność, skalowalność i możliwość uchwycenia dalekosiężnych zależności.
Transformatory są szeroko wykorzystywane w zadaniach NLP, takich jak tłumaczenie, podsumowywanie i analiza sentymentu, a także w widzeniu komputerowym, przewidywaniu struktury białek czy prognozowaniu szeregów czasowych.
Do najważniejszych modeli należą BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) oraz Vision Transformers do przetwarzania obrazów.
Transformatory wymagają znacznych zasobów obliczeniowych do trenowania i wdrażania. Pojawiają się także kwestie etyczne, takie jak potencjalne uprzedzenia w modelach AI i odpowiedzialne wykorzystanie generowanej treści.
Inteligentne chatboty i narzędzia AI w jednym miejscu. Połącz intuicyjne bloki i zamień swoje pomysły w zautomatyzowane Flow.
Model transformera to rodzaj sieci neuronowej zaprojektowanej specjalnie do obsługi danych sekwencyjnych, takich jak tekst, mowa czy dane szeregów czasowych. W ...
Generatywny wstępnie wytrenowany transformator (GPT) to model AI wykorzystujący techniki głębokiego uczenia do generowania tekstu, który blisko przypomina ludzk...
Dwukierunkowa długa pamięć krótkoterminowa (BiLSTM) to zaawansowany typ architektury rekurencyjnych sieci neuronowych (RNN), która przetwarza dane sekwencyjne z...