Visão Geral
O Assistente Wikipedia RIG (Retrieval Interleaved Generator) é um fluxo de trabalho automatizado projetado para responder perguntas de usuários gerando respostas iniciais, identificando dados factuais necessários, recuperando informações da Wikipedia e refinando suas respostas com citações precisas para cada seção. Seu principal objetivo é fornecer respostas fundamentadas em fontes verificáveis e especificar exatamente quais seções e fontes foram utilizadas, tornando-o especialmente útil para pesquisa, verificação de fatos e fins educacionais.
Como o Fluxo de Trabalho Opera
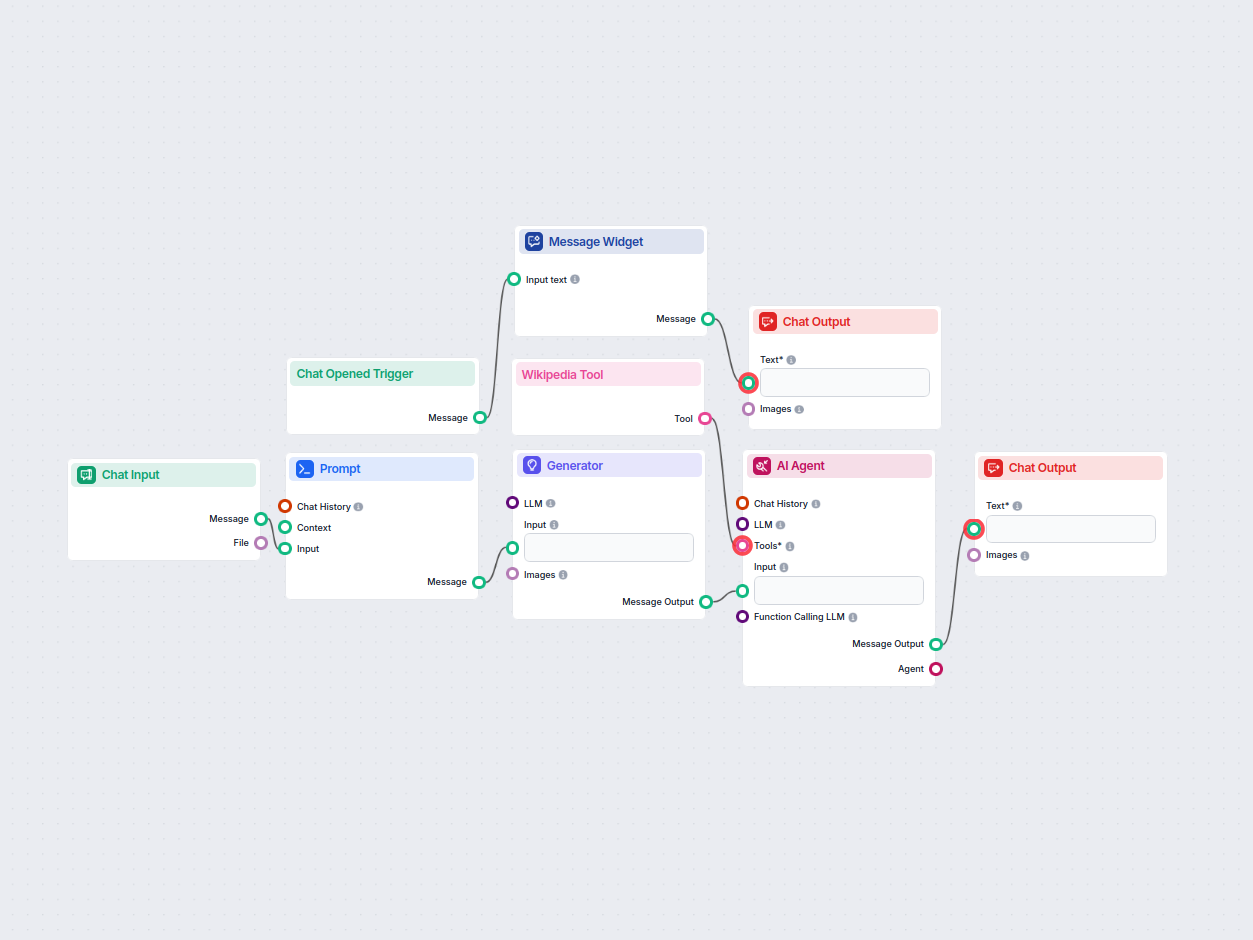
Início do Chat & Boas-Vindas
- Quando uma sessão de chat é aberta, o usuário recebe uma mensagem de boas-vindas explicando o propósito do fluxo: fornecer respostas confiáveis e fundamentadas em fontes. Isso ajuda a definir as expectativas quanto à qualidade e transparência das respostas.
Recebimento da Pergunta do Usuário
- O usuário envia uma pergunta através do chat. Essa entrada é capturada e encaminhada para processamento.
Geração do Prompt
- O fluxo inclui um Template de Prompt que recebe a pergunta do usuário e constrói um prompt detalhado. Esse prompt instrui o sistema a:
- Gerar uma resposta preliminar, mesmo que use dados fictícios.
- Para cada seção da resposta, especificar qual fonte externa (como a Wikipedia) ou base de conhecimento interna deve ser utilizada para verificar e refinar aquela seção.
- Incluir consultas de busca para a Wikipedia a fim de buscar as informações corretas para cada seção.
Exemplo:
Entrada do Usuário: Quais países lideram em energia renovável?
Saída de Rascunho: Os principais países são Noruega, Suécia, Portugal [Buscar na Wikipedia: "Top Countries in renewable Energy"]...
Geração da Resposta Inicial
- Utilizando um gerador de modelo de linguagem, o sistema cria um rascunho de resposta com base no prompt, destacando onde os dados factuais precisam ser inseridos e quais fontes devem ser usadas para verificação.
Recuperação de Dados & Refinamento da Resposta
- Um Agente de IA recebe o rascunho e utiliza a Ferramenta Wikipedia para buscar na Wikipedia as consultas especificadas.
- Para cada seção da resposta, o agente recupera os dados factuais relevantes da Wikipedia e substitui o conteúdo fictício ou de rascunho.
- Cada seção é refinada para incluir um link direto para o artigo ou seção exata da Wikipedia utilizada, garantindo transparência e fácil verificação.
O agente é instruído a evitar frases genéricas ou de preenchimento, focando apenas em conteúdo conciso e factual.
Saída Final
- A resposta totalmente refinada, com cada seção fundamentada em uma fonte específica da Wikipedia (e links fornecidos no texto), é exibida ao usuário na interface de chat.
Estrutura do Fluxo de Trabalho
| Etapa | Componente | Finalidade |
|---|
| 1 | Disparador de Chat Aberto | Detecta nova sessão de chat e dispara mensagem de boas-vindas |
| 2 | Widget de Mensagem | Exibe saudação inicial e instruções |
| 3 | Entrada do Chat | Aceita a pergunta do usuário |
| 4 | Template de Prompt | Formata o prompt com instruções para resposta + indicação de fontes |
| 5 | Gerador | Produz o rascunho inicial da resposta (com espaços reservados) |
| 6 | Ferramenta Wikipedia | Permite a recuperação de dados da Wikipedia |
| 7 | Agente de IA | Refina o rascunho, busca fatos, insere citações/links |
| 8 | Saída do Chat | Apresenta a resposta final e fundamentada ao usuário |
Principais Recursos e Benefícios
- Transparência de Fontes: Cada seção da resposta especifica claramente qual página ou seção da Wikipedia foi utilizada, incluindo links diretos para verificação do usuário.
- Automação e Escalabilidade: O fluxo automatiza o processo de rascunho, verificação de fatos e refinamento das respostas, tornando-o adequado para lidar com muitas consultas de forma eficiente.
- Saída de Nível de Pesquisa: Ao fundamentar cada afirmação em uma fonte externa verificável, o sistema produz respostas adequadas para contextos acadêmicos, empresariais e profissionais.
- Personalização: Se necessário, fontes de conhecimento internas podem ser integradas junto à Wikipedia, tornando o sistema adaptável para a recuperação de dados específicos de cada empresa.
Casos de Uso
- Assistentes Educacionais: Fornecem respostas a estudantes sempre com citação das fontes.
- Bots de Verificação de Fatos: Verificam informações instantaneamente e apresentam as fontes sem necessidade de pesquisa manual.
- Suporte ao Cliente: Entregam informações sobre empresa ou produtos com clara procedência dos dados.
- Criação de Conteúdo: Redatores e jornalistas podem obter rascunhos com referências incorporadas para posterior desenvolvimento.
Resumo
Este fluxo de trabalho capacita usuários com respostas confiáveis e bem referenciadas, intercalando etapas de geração e recuperação de informações. É especialmente útil onde precisão factual, transparência e atribuição de fontes são cruciais. Seu design modular e automatizado o torna altamente escalável para organizações que buscam automatizar tarefas de pesquisa e perguntas e respostas em larga escala.