Análise de Empresas com IA & Exportação para Google Sheets
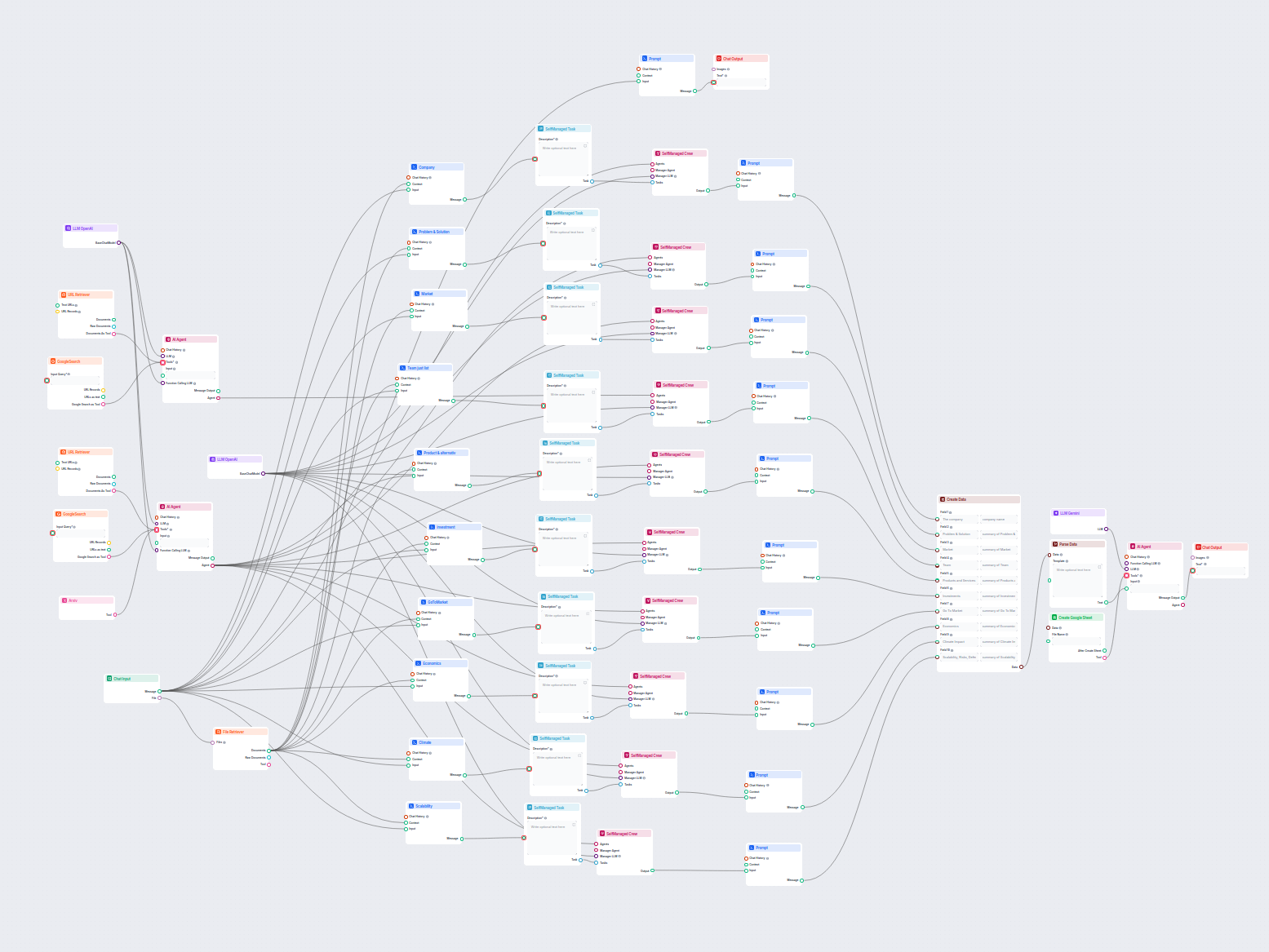
Este fluxo de trabalho com IA analisa qualquer empresa em profundidade pesquisando dados públicos e documentos, abrangendo mercado, equipe, produtos, investimen...
5 min de leitura
Desbloqueie o poder dos modelos Gemini do Google no FlowHunt—troque modelos de IA, controle configurações e crie chatbots de IA mais inteligentes com facilidade.
Descrição do componente
The LLM Gemini component connects the Gemini models from Google to your flow. While the Generators and Agents are where the actual magic happens, LLM components allow you to control the model used. All components come with ChatGPT-4 by default. You can connect this component if you wish to change the model or gain more control over it.
Remember that connecting an LLM Component is optional. All components that use an LLM come with ChatGPT-4o as the default. The LLM components allow you to change the model and control model settings.
Tokens represent the individual units of text the model processes and generates. Token usage varies with models, and a single token can be anything from words or subwords to a single character. Models are usually priced in millions of tokens.
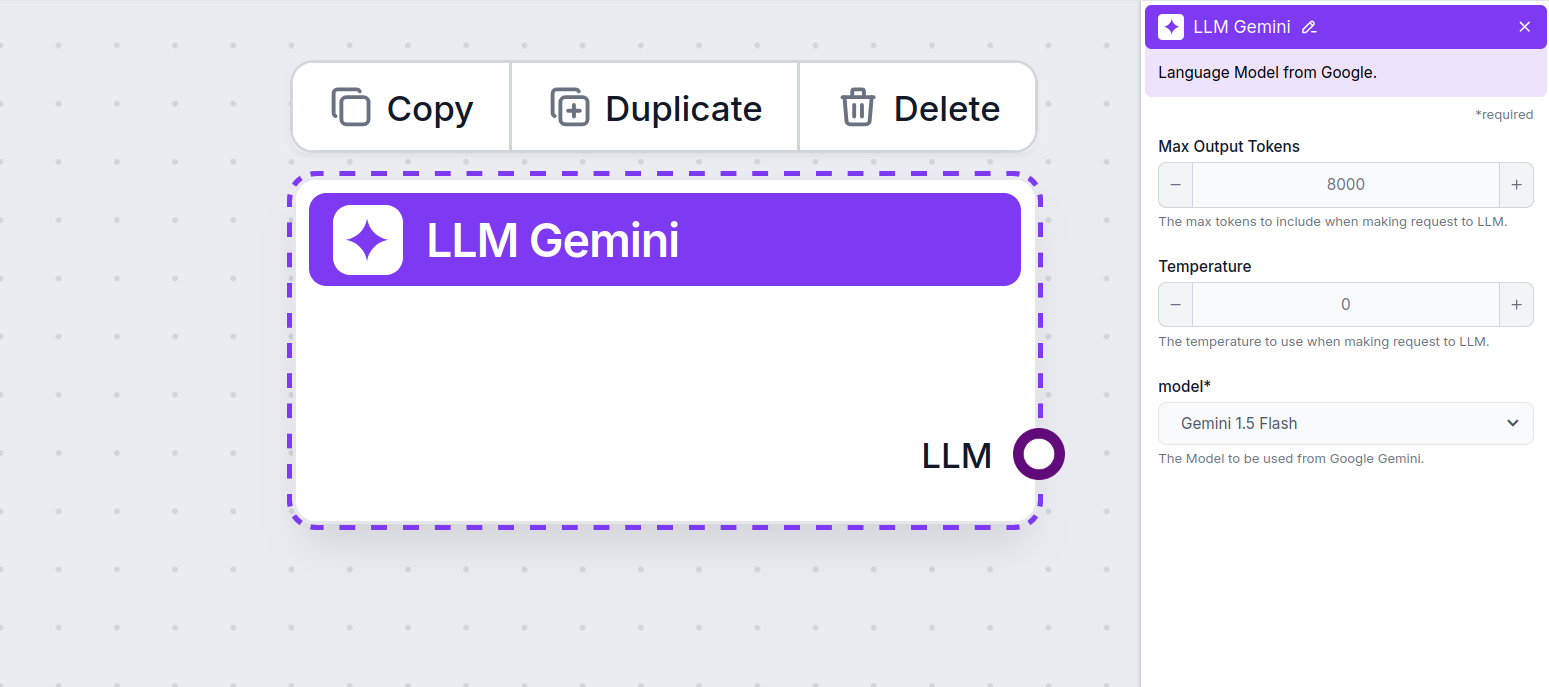
The max tokens setting limits the total number of tokens that can be processed in a single interaction or request, ensuring the responses are generated within reasonable bounds. The default limit is 4,000 tokens, the optimal size for summarizing documents and several sources to generate an answer.
Temperature controls the variability of answers, ranging from 0 to 1.
A temperature of 0.1 will make the responses very to the point but potentially repetitive and deficient.
A high temperature of 1 allows for maximum creativity in answers but creates the risk of irrelevant or even hallucinatory responses.
For example, the recommended temperature for a customer service bot is between 0.2 and 0.5. This level should keep the answers relevant and to the script while allowing for a natural response variation.
This is the model picker. Here, you’ll find all the supported Gemini models from Google. We support all the latest Gemini models:
You’ll notice that all LLM components only have an output handle. Input doesn’t pass through the component, as it only represents the model, while the actual generation happens in AI Agents and Generators.
The LLM handle is always purple. The LLM input handle is found on any component that uses AI to generate text or process data. You can see the options by clicking the handle:
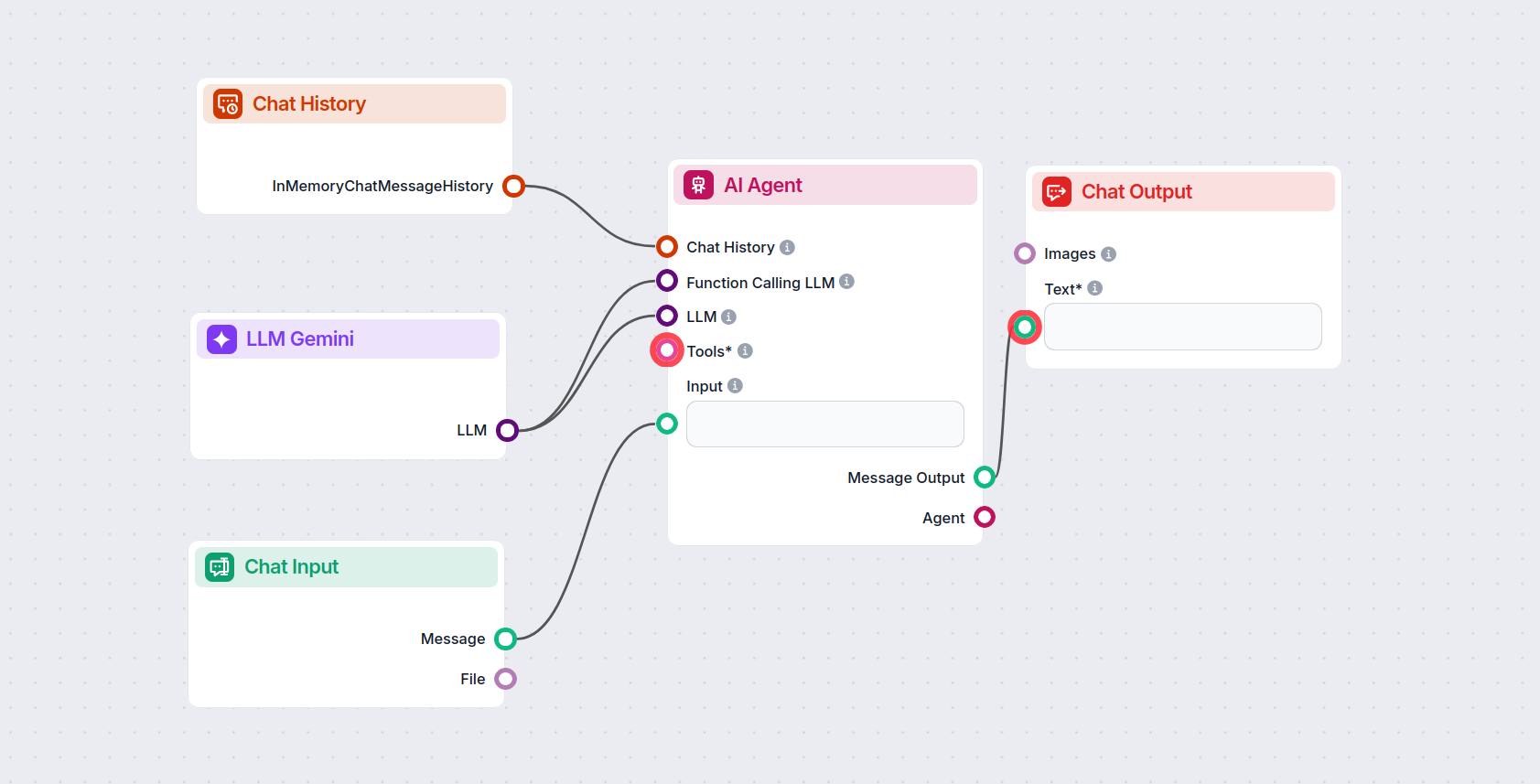
This allows you to create all sorts of tools. Let’s see the component in action. Here’s a simple AI Agent chatbot Flow that’s using Gemini 2.0 Flash Experimental to generate responses. You can think of it as a basic Gemini chatbot.
This simple Chatbot Flow includes:
Para ajudá-lo a começar rapidamente, preparamos vários modelos de fluxo de exemplo que demonstram como usar o componente LLM Gemini de forma eficaz. Esses modelos apresentam diferentes casos de uso e melhores práticas, tornando mais fácil para você entender e implementar o componente em seus próprios projetos.
Este fluxo de trabalho com IA analisa qualquer empresa em profundidade pesquisando dados públicos e documentos, abrangendo mercado, equipe, produtos, investimen...
Este fluxo de trabalho com IA fornece uma análise abrangente e orientada por dados sobre empresas. Ele reúne informações sobre o histórico, mercado, equipe, pro...
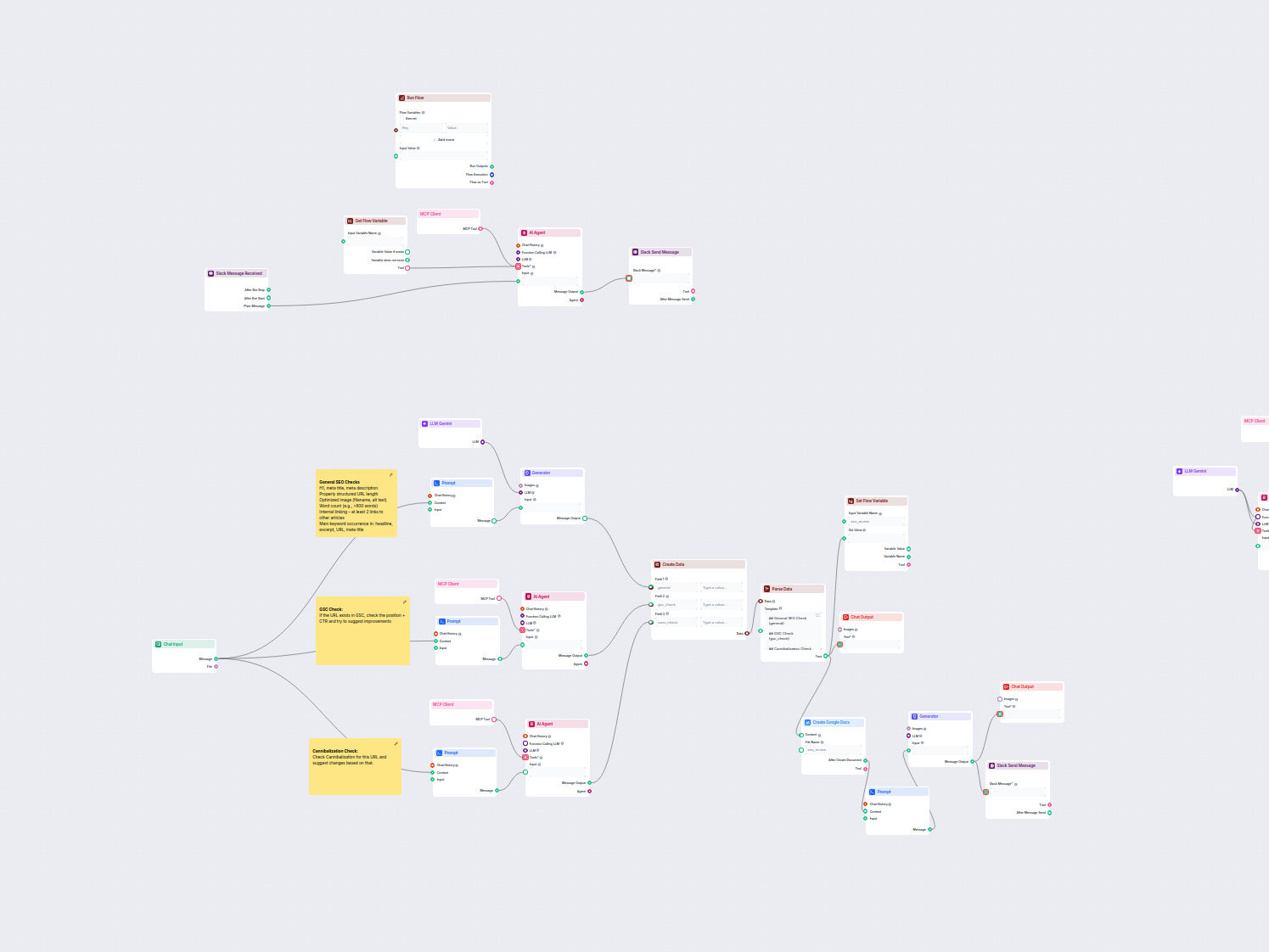
Este fluxo de trabalho automatiza o processo de revisão e auditoria SEO para páginas de sites. Ele analisa o conteúdo da página de acordo com as melhores prátic...
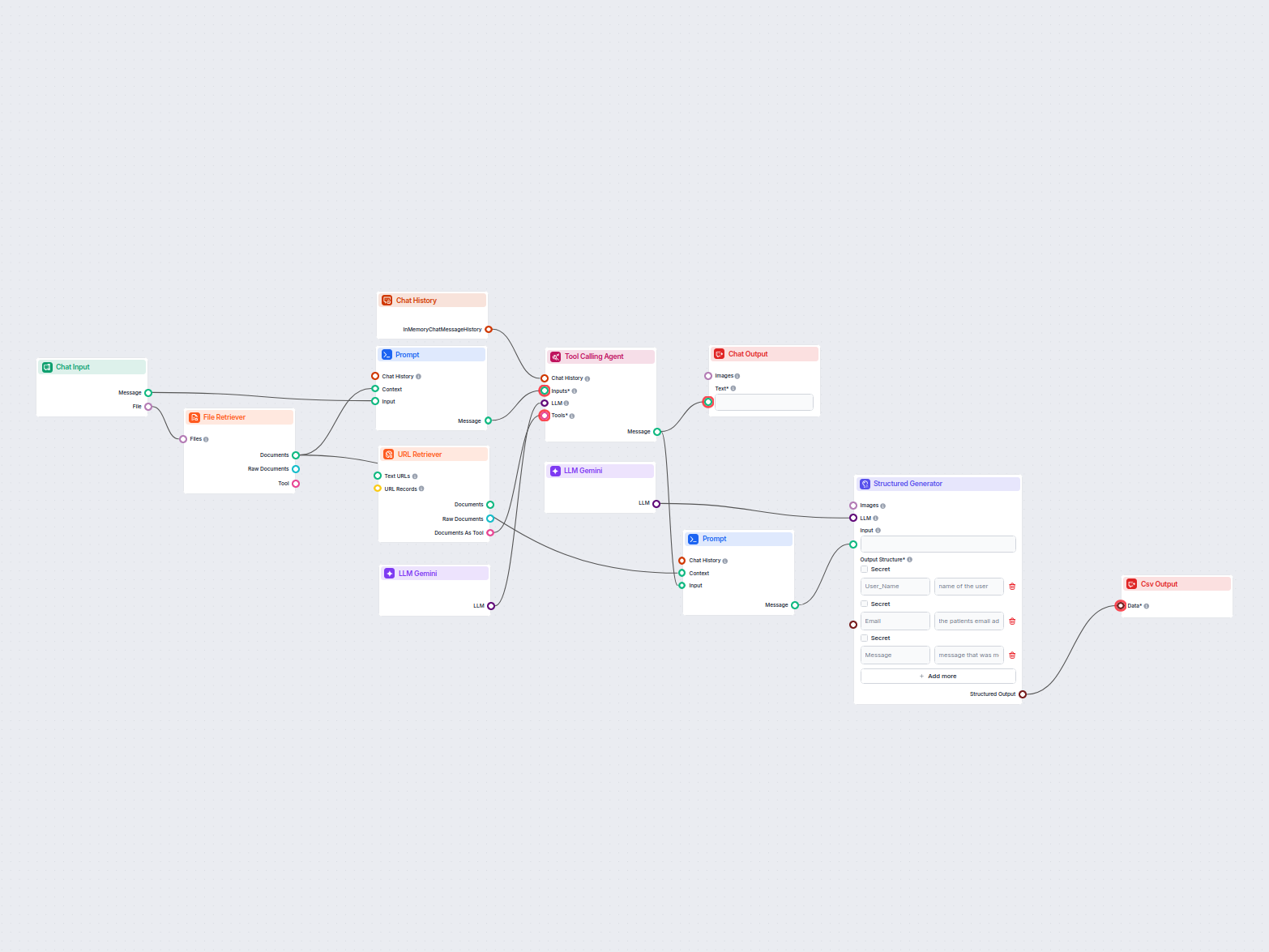
Este fluxo de trabalho extrai e organiza informações-chave de e-mails e arquivos anexados, utiliza IA para processar e estruturar os dados, e gera os resultados...
O LLM Gemini conecta os modelos Gemini do Google aos seus fluxos de IA no FlowHunt, permitindo que você escolha entre as variantes mais recentes do Gemini para geração de texto e personalize seu comportamento.
O FlowHunt suporta Gemini 2.0 Flash Experimental, Gemini 1.5 Flash, Gemini 1.5 Flash-8B e Gemini 1.5 Pro—cada um oferecendo capacidades únicas para entradas de texto, imagem, áudio e vídeo.
Max Tokens limita o tamanho da resposta, enquanto Temperature controla a criatividade—valores mais baixos fornecem respostas mais objetivas, valores mais altos permitem mais variedade. Ambos podem ser definidos por modelo no FlowHunt.
Não, o uso dos componentes LLM é opcional. Todos os fluxos de IA vêm com o ChatGPT-4o por padrão, mas adicionar o LLM Gemini permite que você mude para modelos do Google e ajuste suas configurações.
Comece a criar chatbots e ferramentas de IA avançadas com Gemini e outros modelos de ponta—tudo em um só painel. Troque modelos, personalize configurações e otimize seus fluxos de trabalho.
O FlowHunt suporta dezenas de modelos de IA, incluindo os revolucionários modelos DeepSeek. Veja como usar o DeepSeek em suas ferramentas de IA e chatbots.
O FlowHunt suporta dezenas de modelos de texto de IA, incluindo modelos da Mistral. Veja como usar a Mistral em suas ferramentas e chatbots de IA.
O FlowHunt suporta dezenas de modelos de geração de texto, incluindo os modelos Llama da Meta. Saiba como integrar o Llama às suas ferramentas e chatbots de IA,...