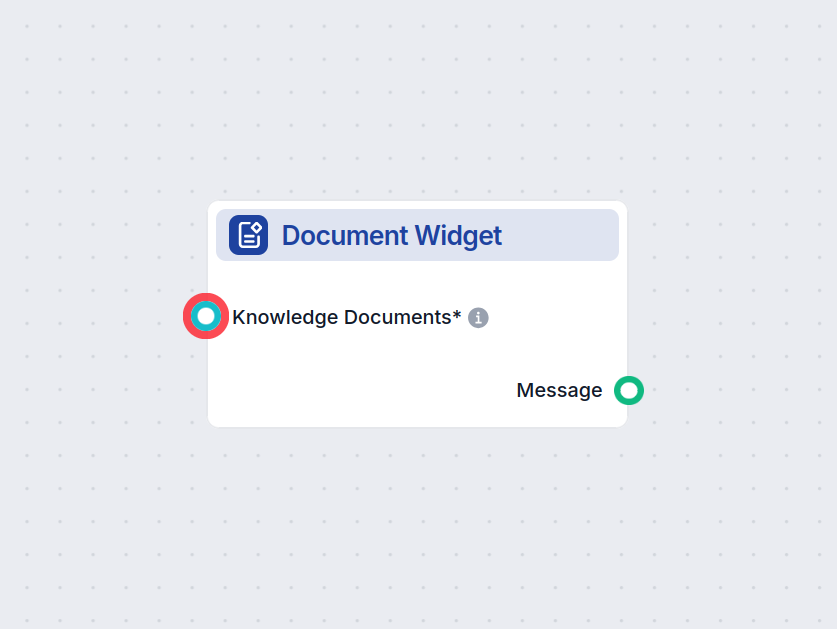
Widget de Fonte de Conhecimento
Exiba documentos relevantes diretamente nas respostas do seu chatbot usando o Widget de Fonte de Conhecimento. Este componente apresenta documentos de conhecime...
2 min de leitura
AI
Knowledge
+4
Transforme dados estruturados em texto markdown legível com o componente Documento para Texto do FlowHunt, oferecendo controles personalizáveis para uma saída eficiente e relevante gerada por IA.
Descrição do componente
AI can analyze large quantities of data in seconds, but only some of the data will be relevant or suitable for output. The Document to Text component gives you control over how the data from retrievers is processed and transformed into text.
The Document to Text component is designed to transform input knowledge documents into plain text format. This is particularly useful in AI and data processing workflows where textual data is required for further processing, analysis, or as input to language models.
This component takes one or more structured documents (such as HTML, Markdown, PDFs, or other supported formats) and extracts the textual content. It allows you to specify precisely which parts of the documents to export, whether to include metadata, and how to handle document sections or headers. The output is a unified message object containing the extracted text, ready for downstream tasks like summarization, classification, or question answering.
The component accepts several configurable inputs:
| Input Name | Type | Required | Description | Default Value |
|---|---|---|---|---|
| Documents | List[Document] | Yes | The knowledge documents to transform into text. | N/A (user provided) |
| From H1 if exists | Boolean | Yes | Start extraction from the first H1 header if present. | true |
| Load from pointer | Boolean | Yes | Start extraction from the pointer best matching the input query, or load all if not matched. | true |
| Max Tokens | Integer | No | Maximum number of tokens in the output text. | 3000 |
| Skip Last Header | Boolean | Yes | Skip the last header (often a footer) to optimize output. | false |
| Strategy | String | Yes | Text extraction strategy: concatenate documents or include equal size from each. | “Include equal size from each documents” |
| Export Content | Multi-select | No | Which content types to include (e.g., H1, H2, Paragraph). | All types selected |
| Include Metadata | Multi-select | No | Metadata fields to include in the output if available. | Product |
Content Types available: H1, H2, H3, H4, H5, H6, Paragraph
Metadata options: Author, Product, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
The component produces the following output:
| Capability | Description |
|---|---|
| Input Types | List of Documents |
| Output Type | Message (Text + Metadata) |
| Content Granularity | Select headers/paragraphs to include |
| Metadata Options | Select multiple metadata fields to export |
| Output Size Control | Set max tokens |
| Extraction Strategies | Concatenate or balance across documents |
| Section Selection | Start from H1, from pointer, or skip last header |
The bot may crawl many documents to create the text output. The Strategy setting lets you control how it utilizes these documents smartly while staying within the token limit.
Currently, there are two possible strategies:
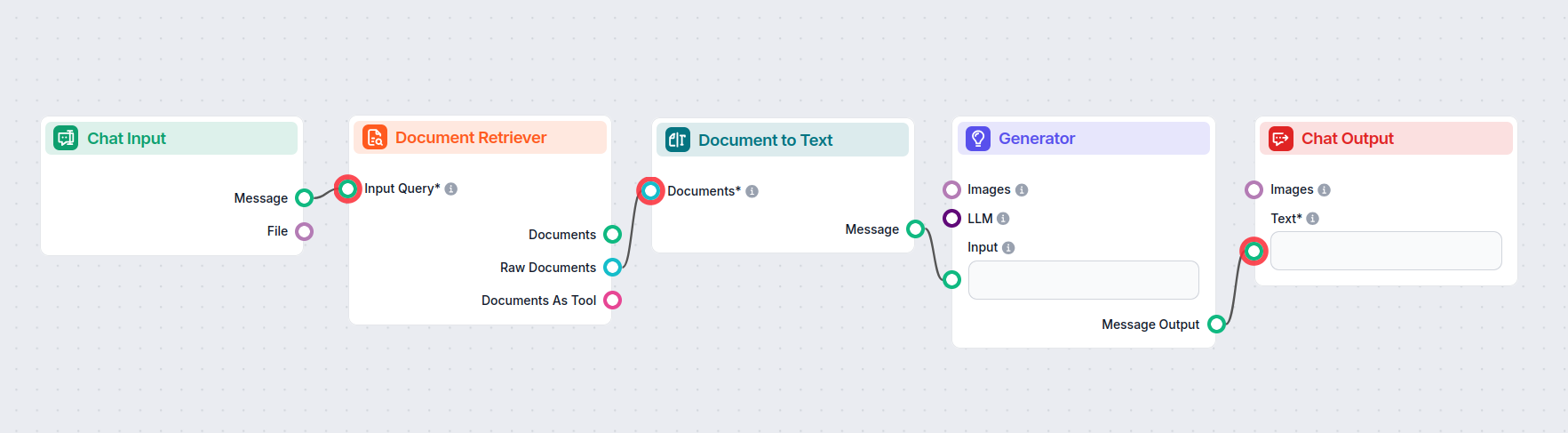
This is a transformer component, meaning it bridges the gap between two outputs. Document to Text takes Documents outputted by the Retriever components:
The knowledge is converted into readable Markdown text as it passes through the transformer. This text can then be connected to components requiring text input, such as splitters, widgets, or outputs.
Here is an example flow using the Document to Text component to bridge the gap between the Document Retrievers and the AI Generator:
O componente obtém conhecimento de componentes do tipo recuperador e o transforma em texto markdown legível, que pode ser conectado a qualquer componente que aceite texto como entrada.
Comece a criar soluções de IA mais inteligentes com o componente Documento para Texto do FlowHunt. Converta dados em texto acionável de forma integrada e potencialize seus fluxos de trabalho automatizados.
Exiba documentos relevantes diretamente nas respostas do seu chatbot usando o Widget de Fonte de Conhecimento. Este componente apresenta documentos de conhecime...
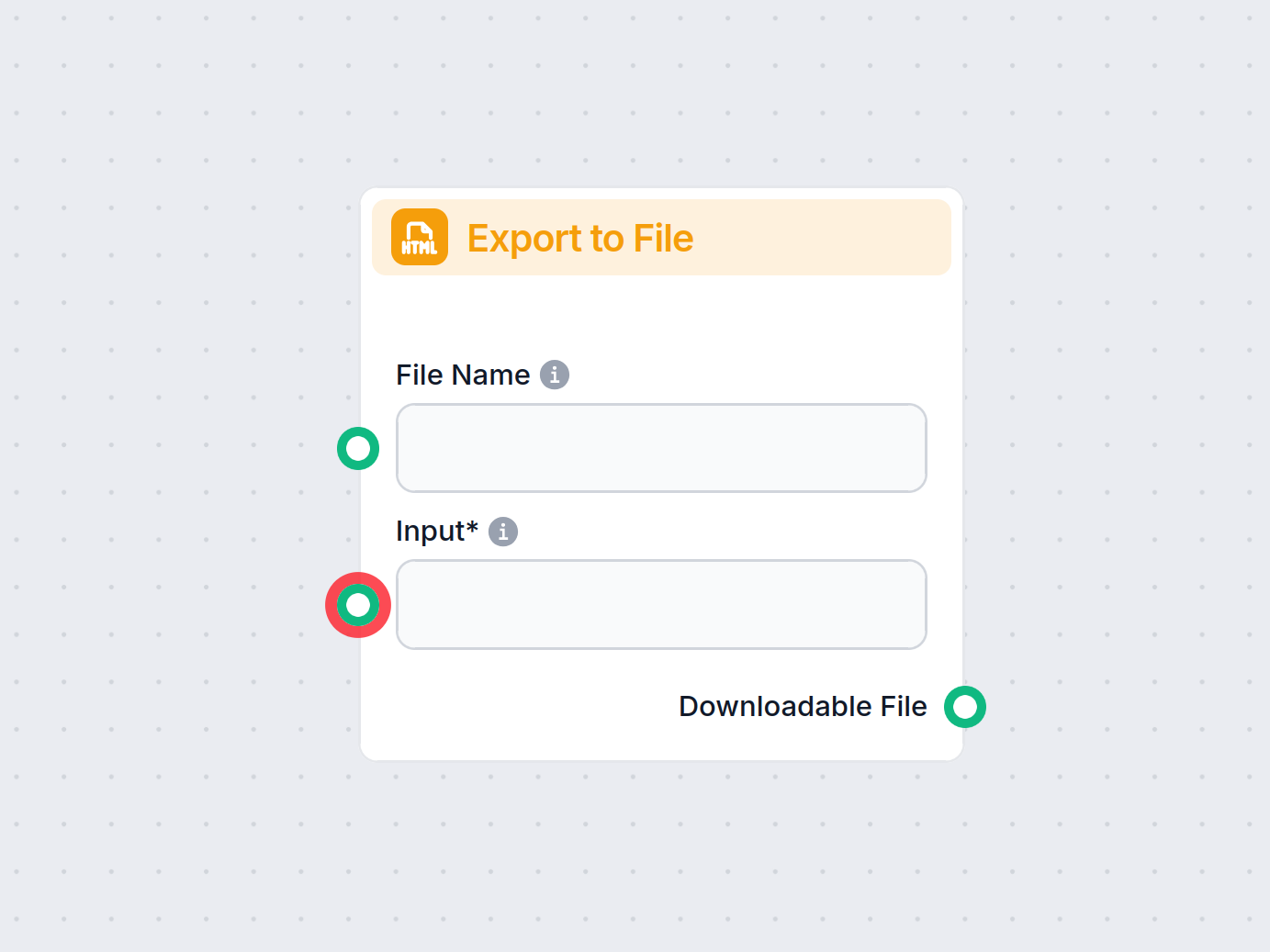
O componente Exportar para Arquivo no FlowHunt permite que você salve textos ou dados gerados durante seu fluxo de trabalho em arquivos para download em vários ...
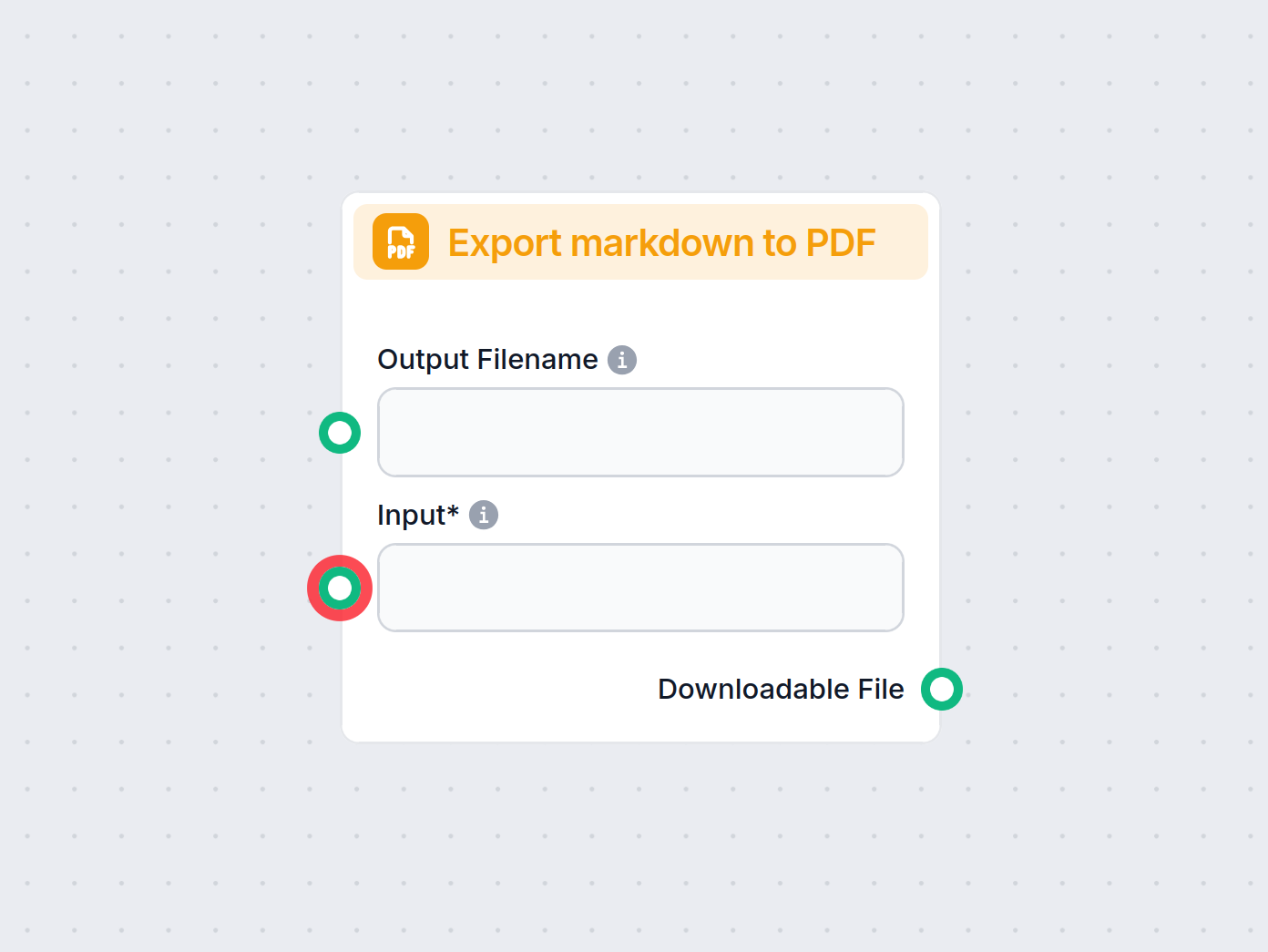
Transforme texto em arquivos PDF prontos para download com o componente Exportar para PDF no FlowHunt. Converta de forma simples markdown ou texto puro do seu f...