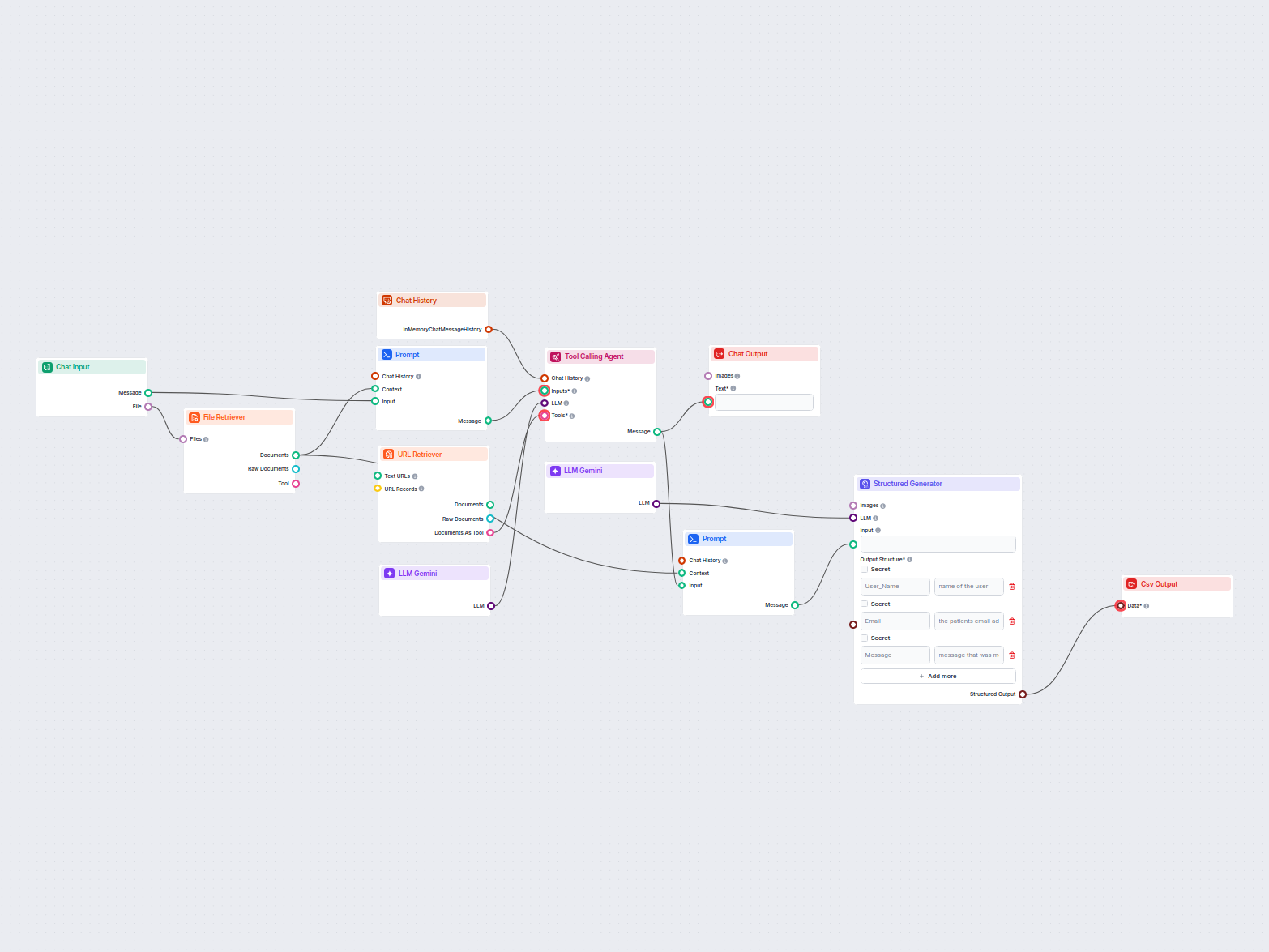
Extração de Dados de E-mails e Arquivos para CSV
Este fluxo de trabalho extrai e organiza informações-chave de e-mails e arquivos anexados, utiliza IA para processar e estruturar os dados, e gera os resultados...
4 min de leitura
Para ajudá-lo a começar rapidamente, preparamos vários modelos de fluxo de exemplo que demonstram como usar o componente Urlcontent de forma eficaz. Esses modelos apresentam diferentes casos de uso e melhores práticas, tornando mais fácil para você entender e implementar o componente em seus próprios projetos.
Este fluxo de trabalho extrai e organiza informações-chave de e-mails e arquivos anexados, utiliza IA para processar e estruturar os dados, e gera os resultados...
Ajudamos empresas como a sua a desenvolver chatbots inteligentes, servidores MCP, ferramentas de IA ou outros tipos de automação de IA para substituir humanos em tarefas repetitivas em sua organização.