Gerador de Postagens para Instagram com IA
Gere postagens envolventes para o Instagram automaticamente, incluindo títulos chamativos, legendas criativas e imagens visualmente atraentes usando pesquisa e ...
4 min de leitura
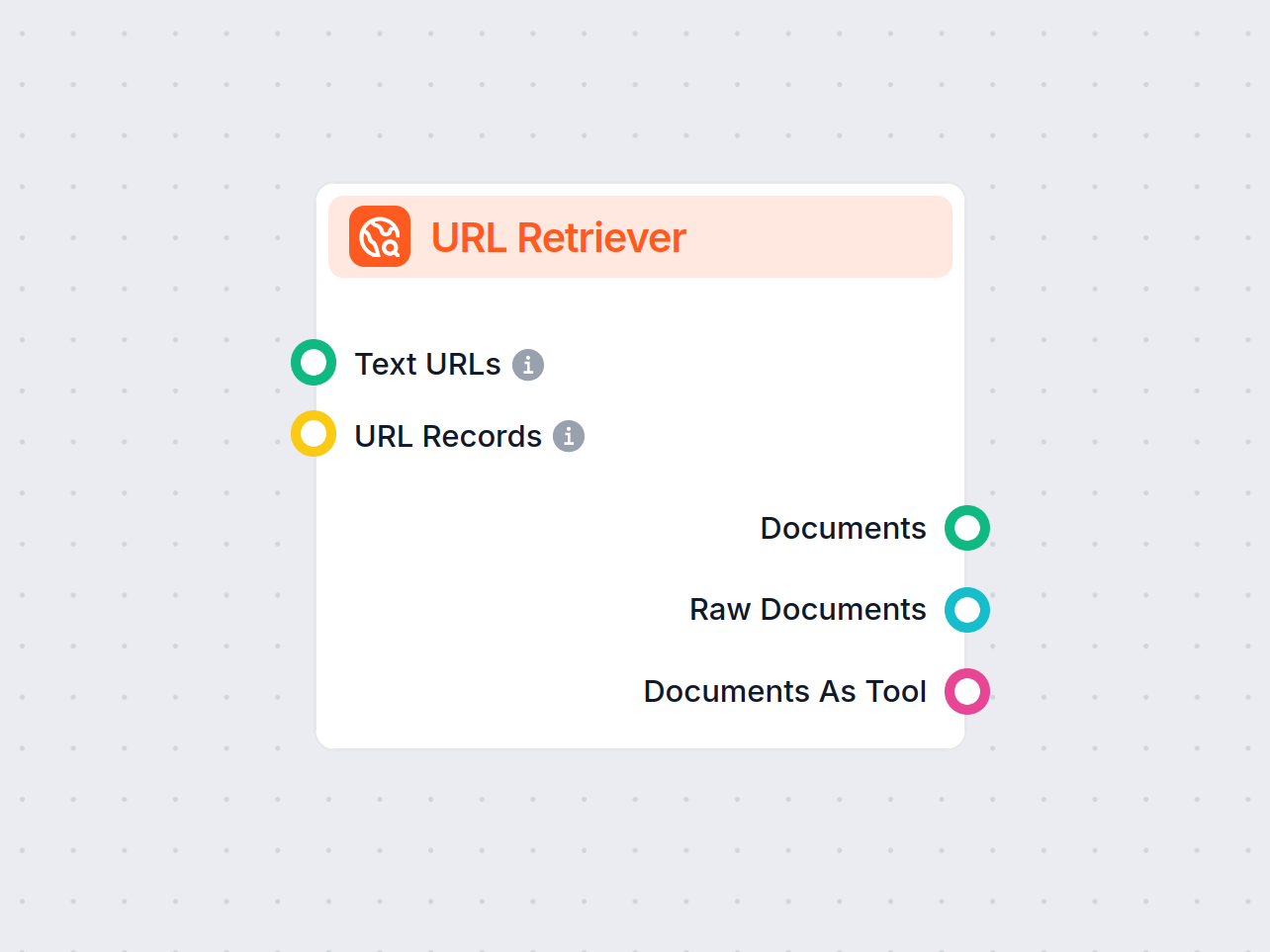
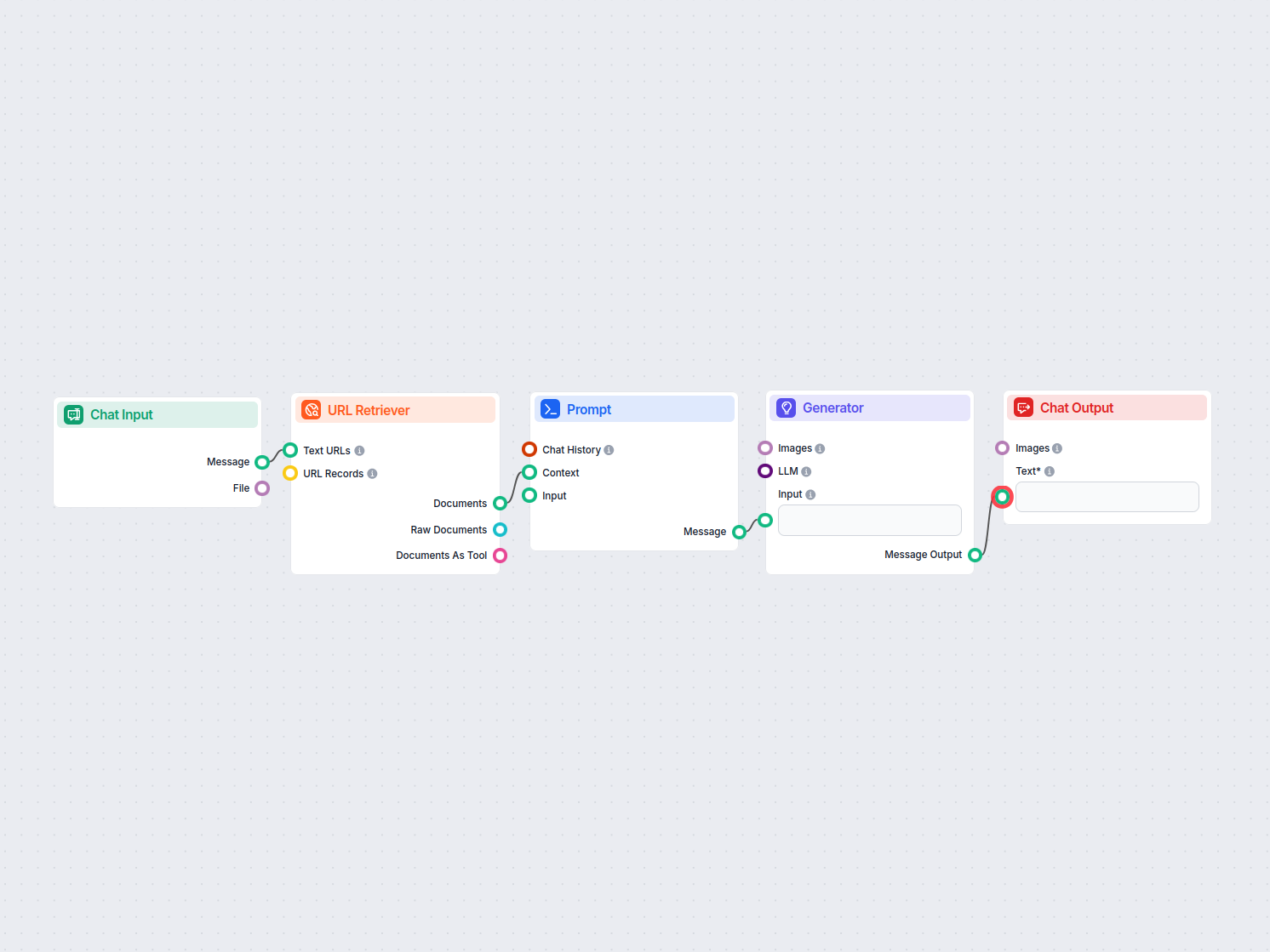
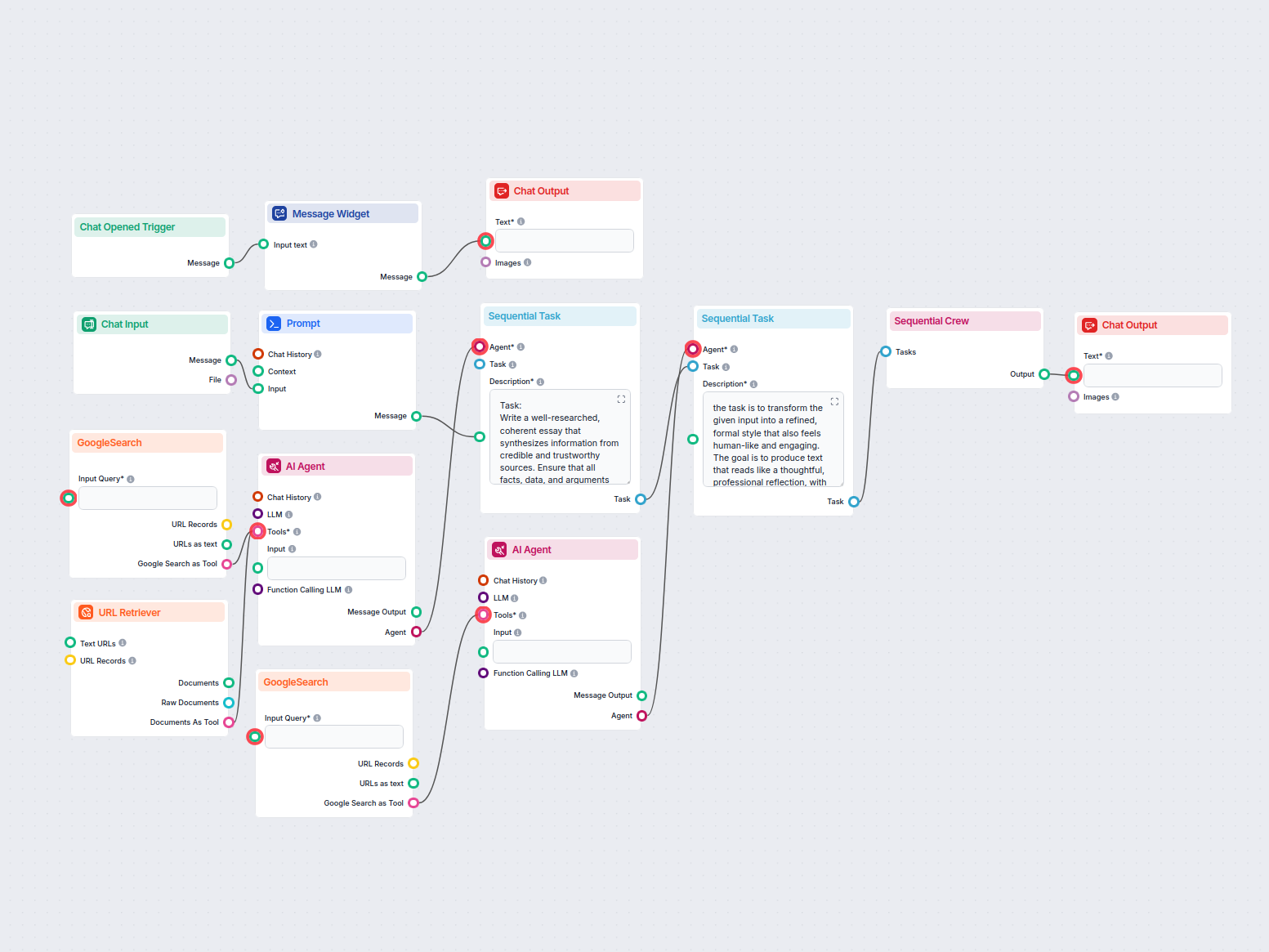
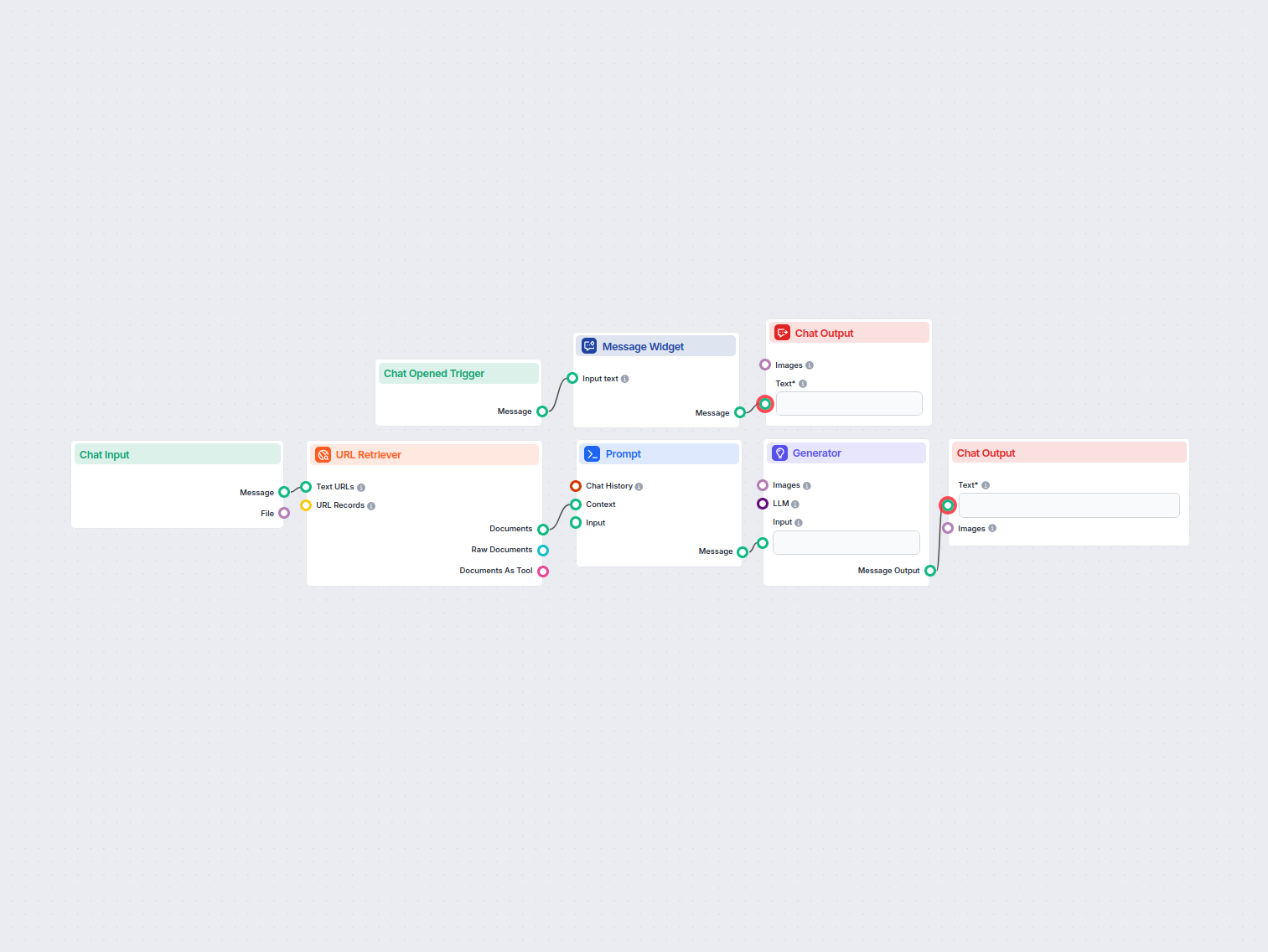
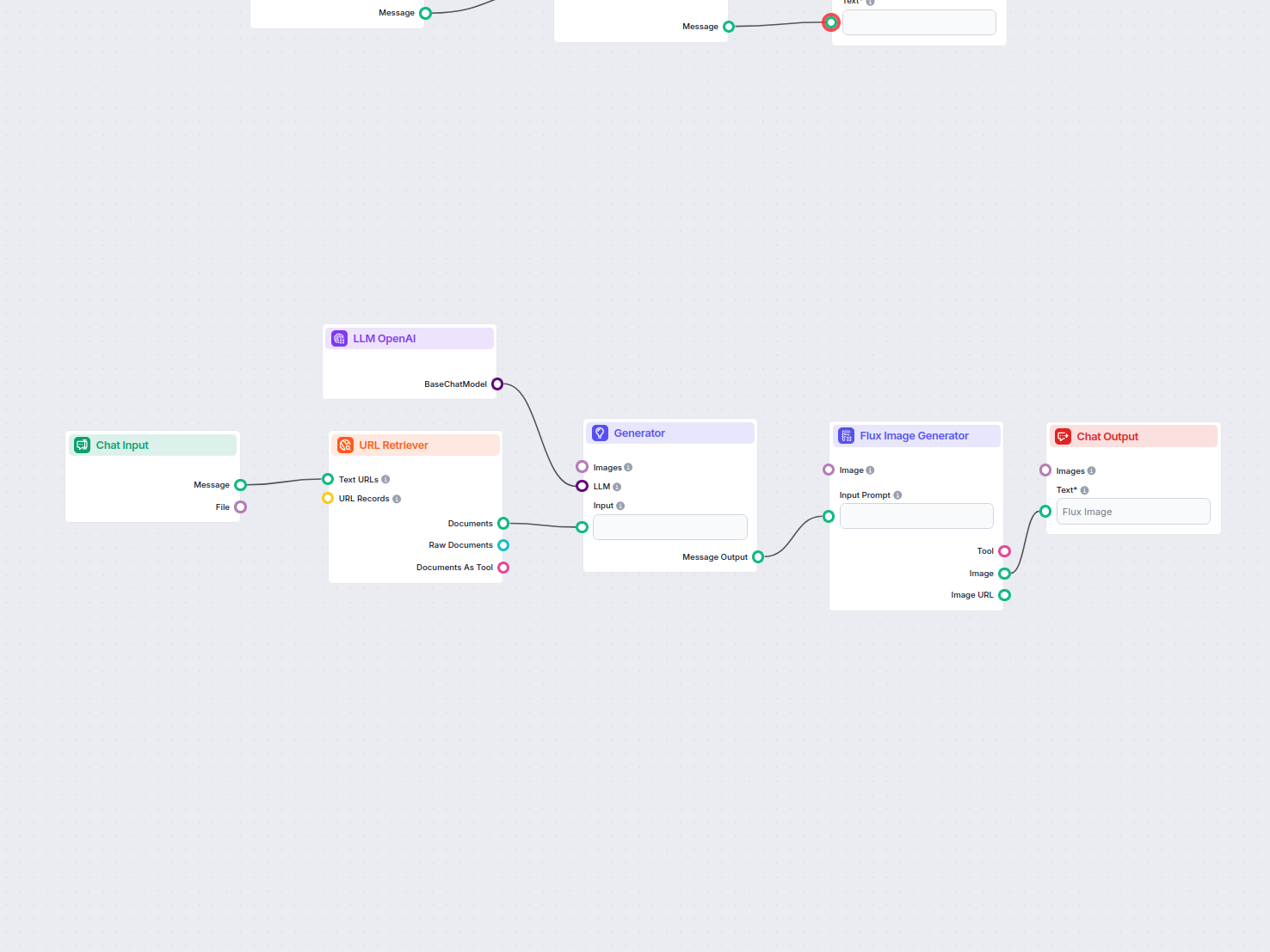
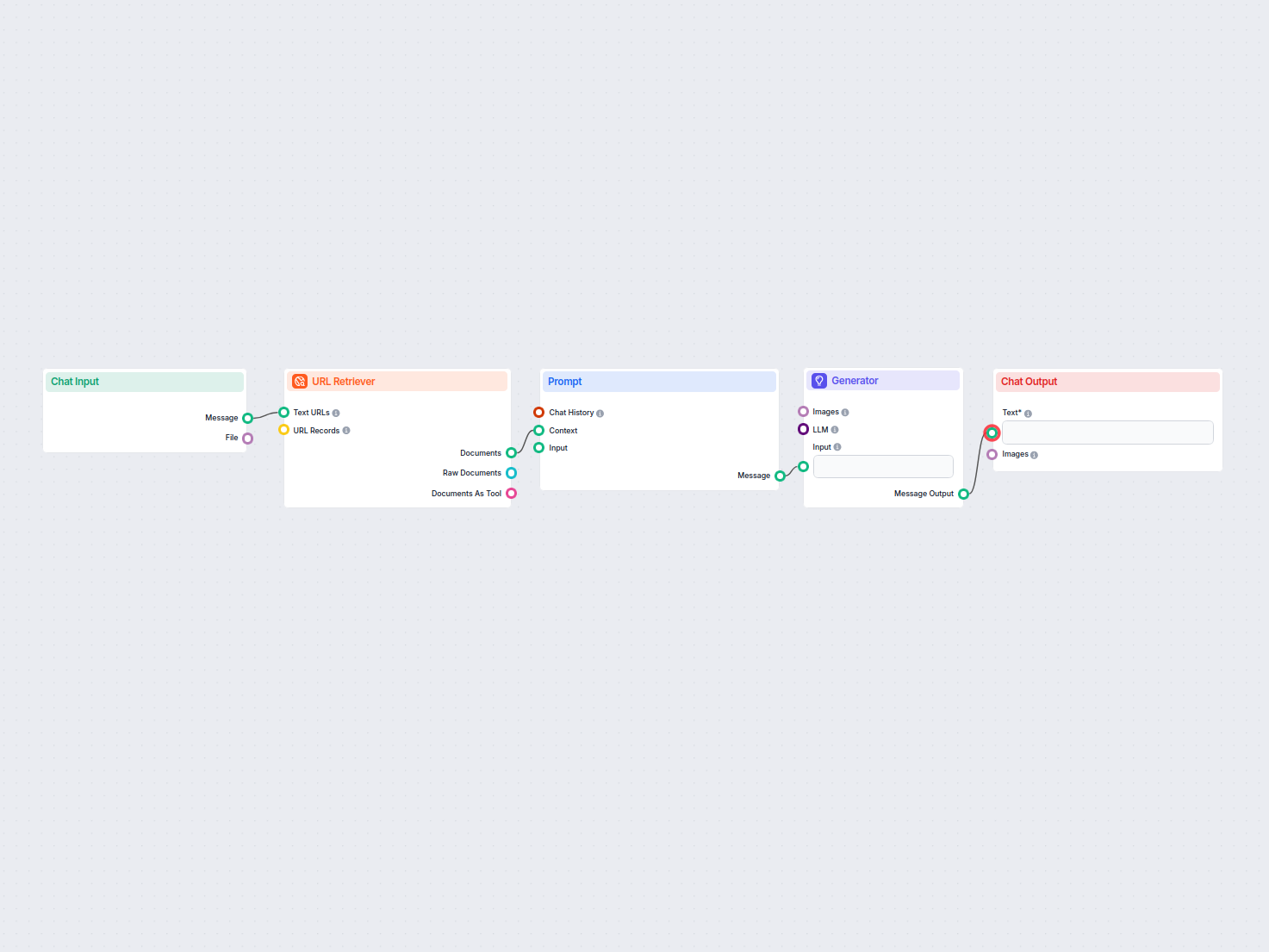
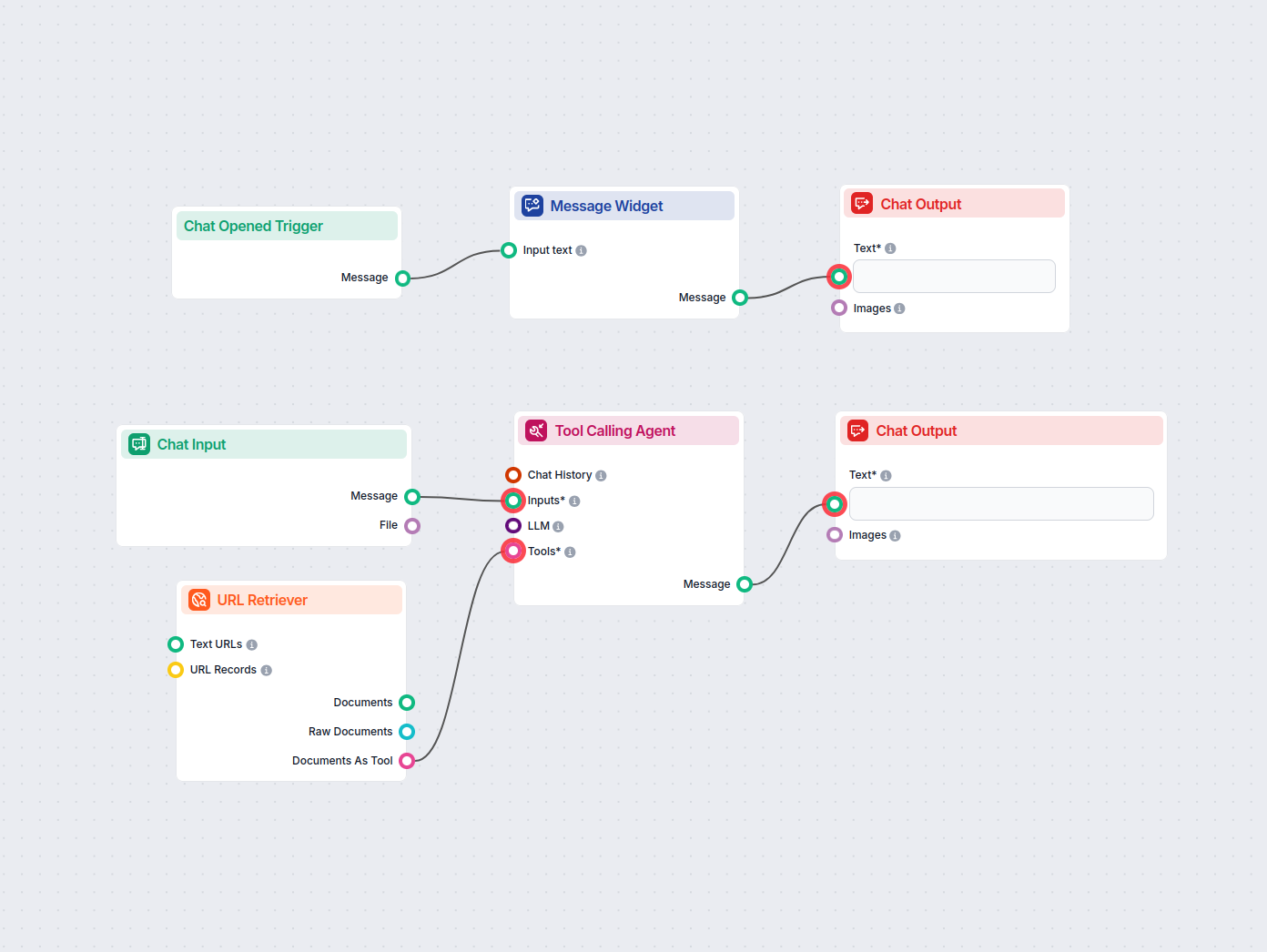
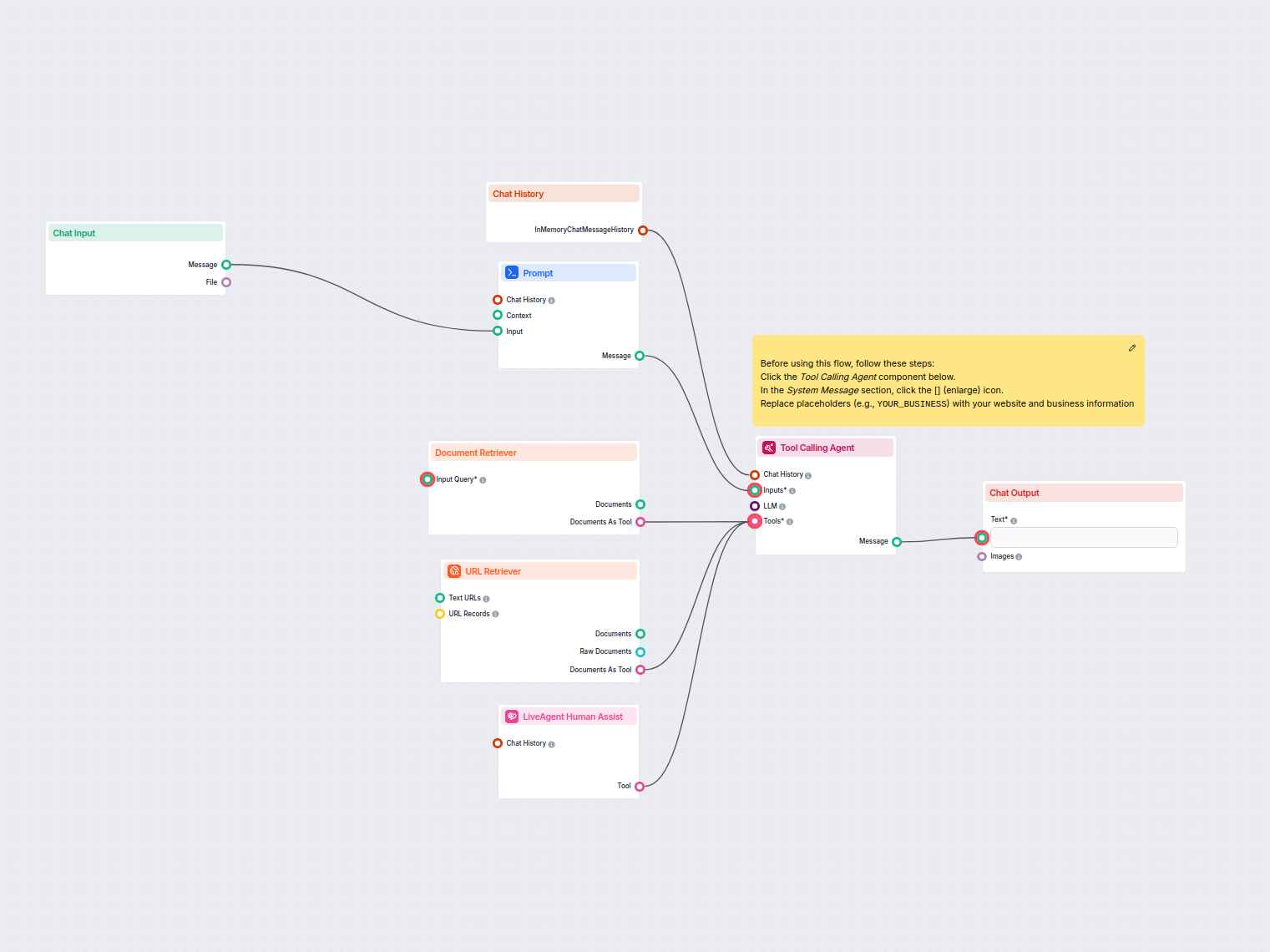
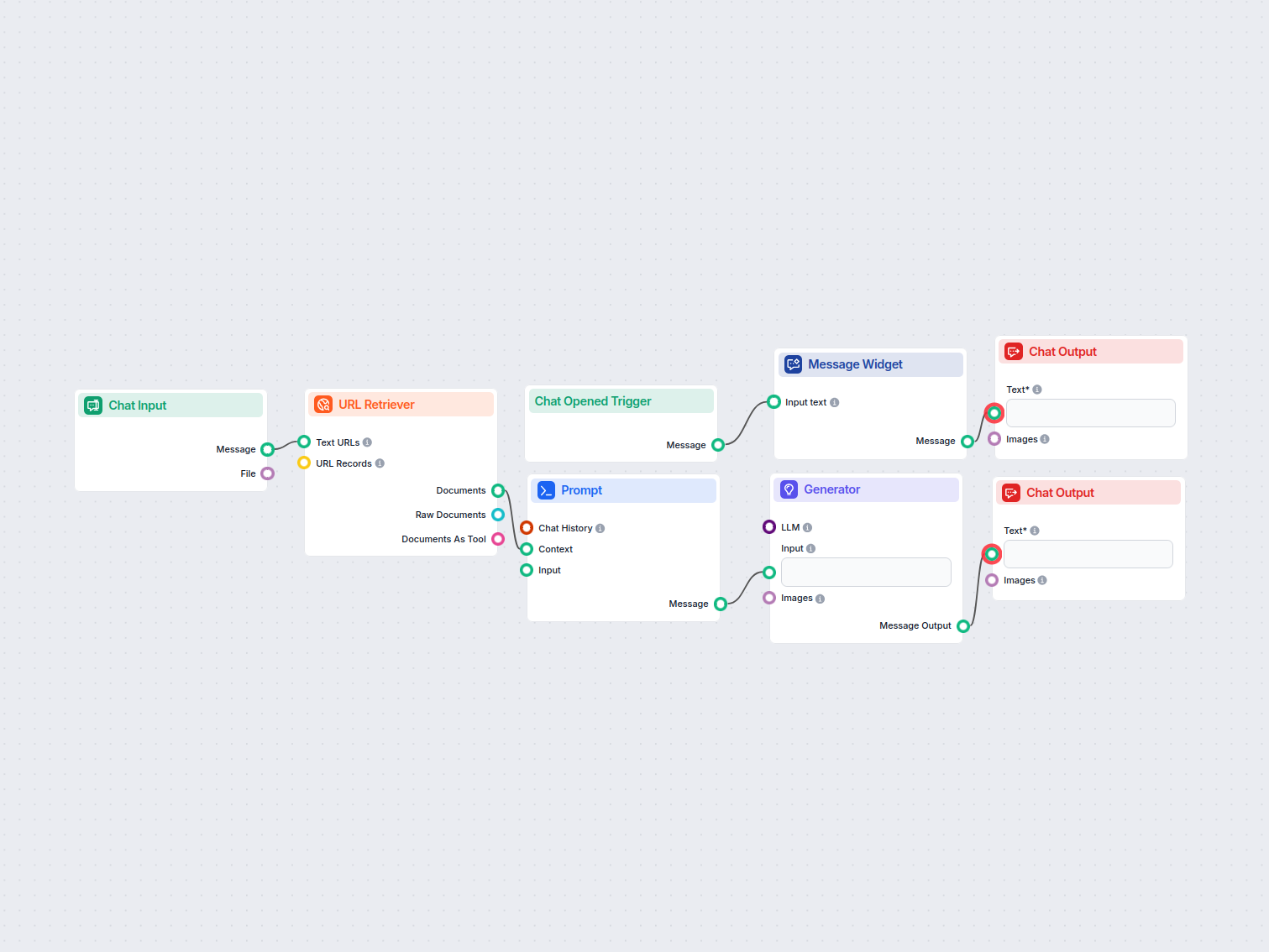
O Recuperador de URL permite buscar e processar conteúdo de links da web, com suporte a OCR, extração de metadados e saída flexível para potencializar fluxos de trabalho de IA.
Descrição do componente
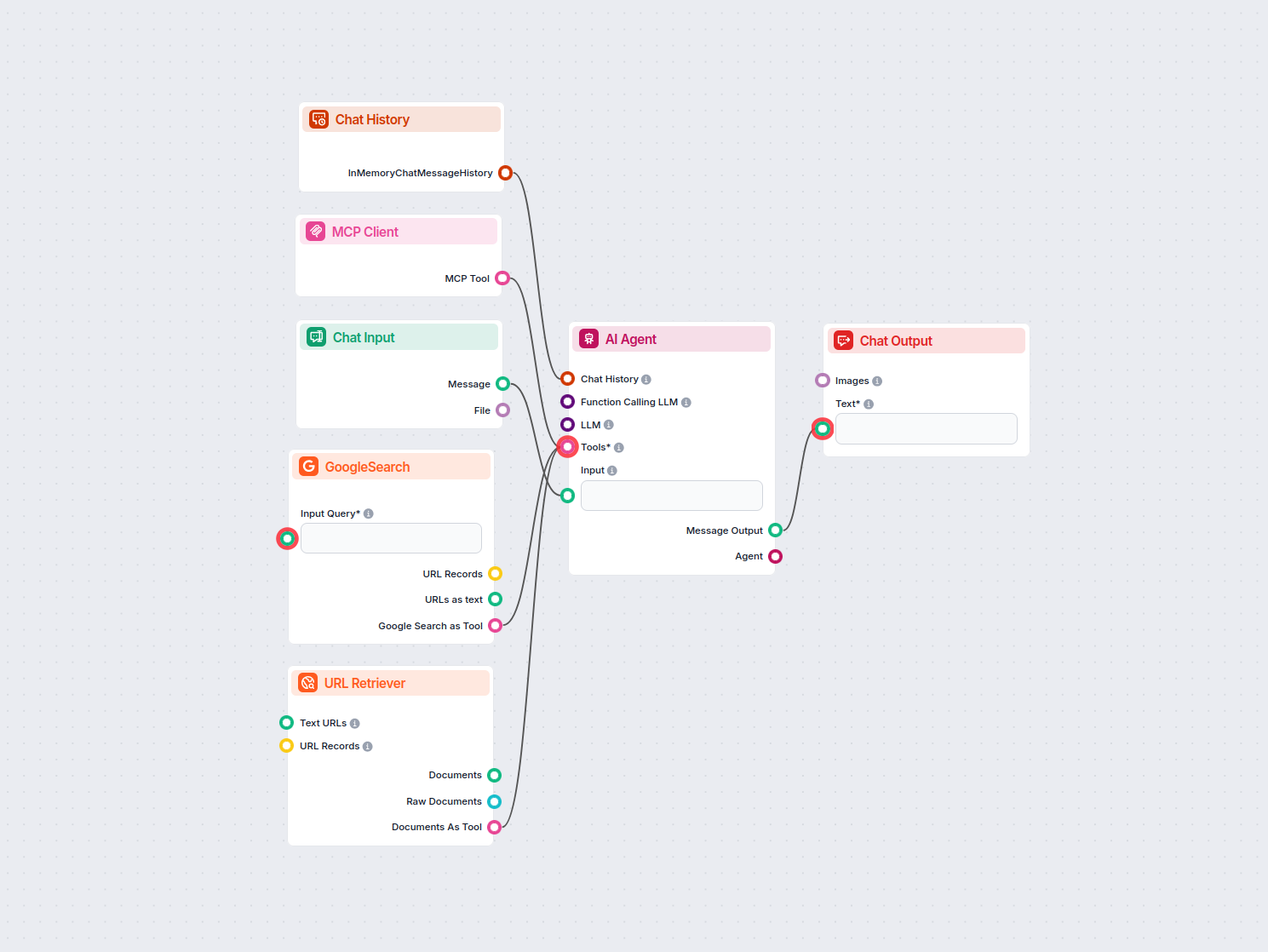
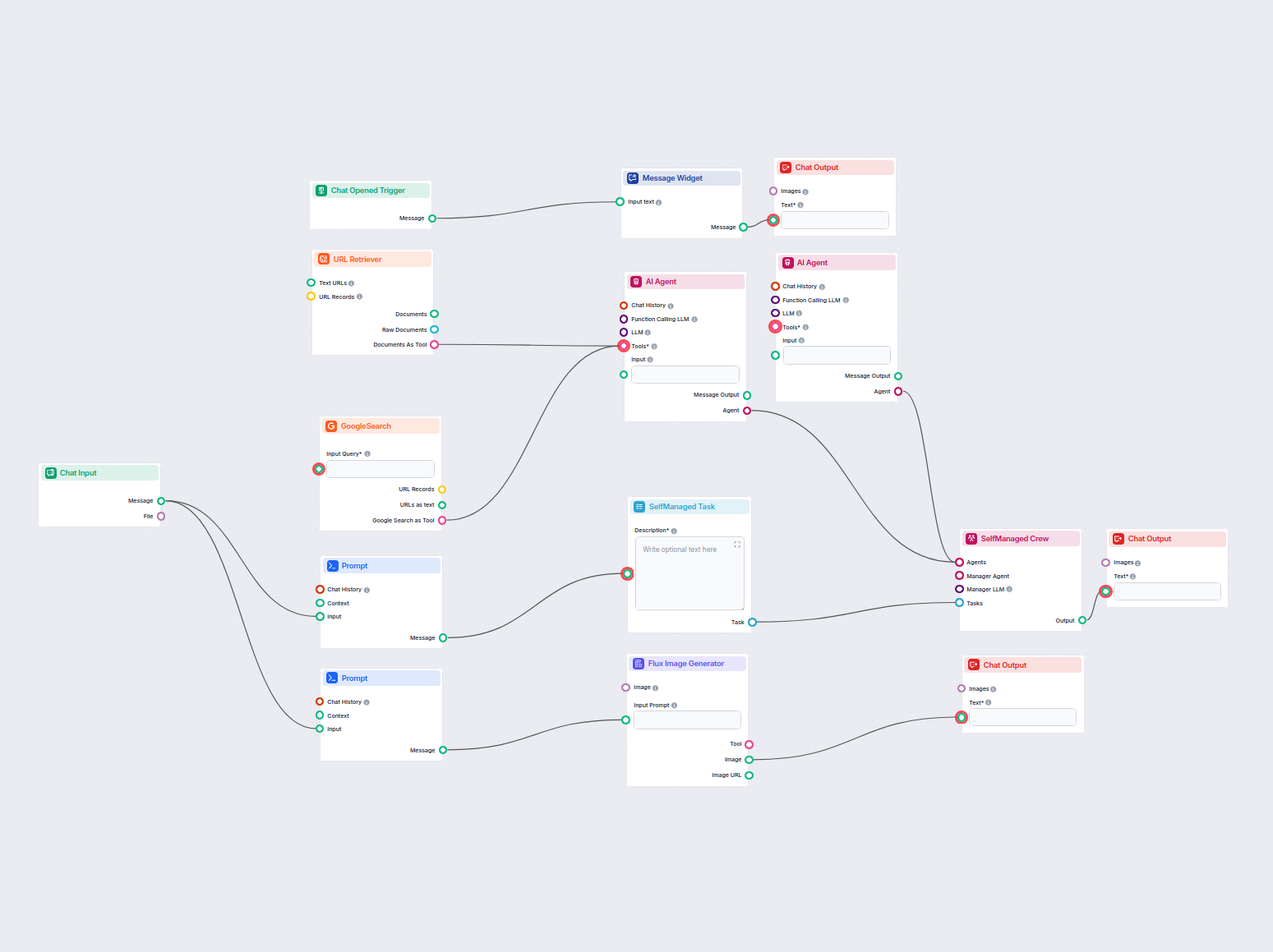
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
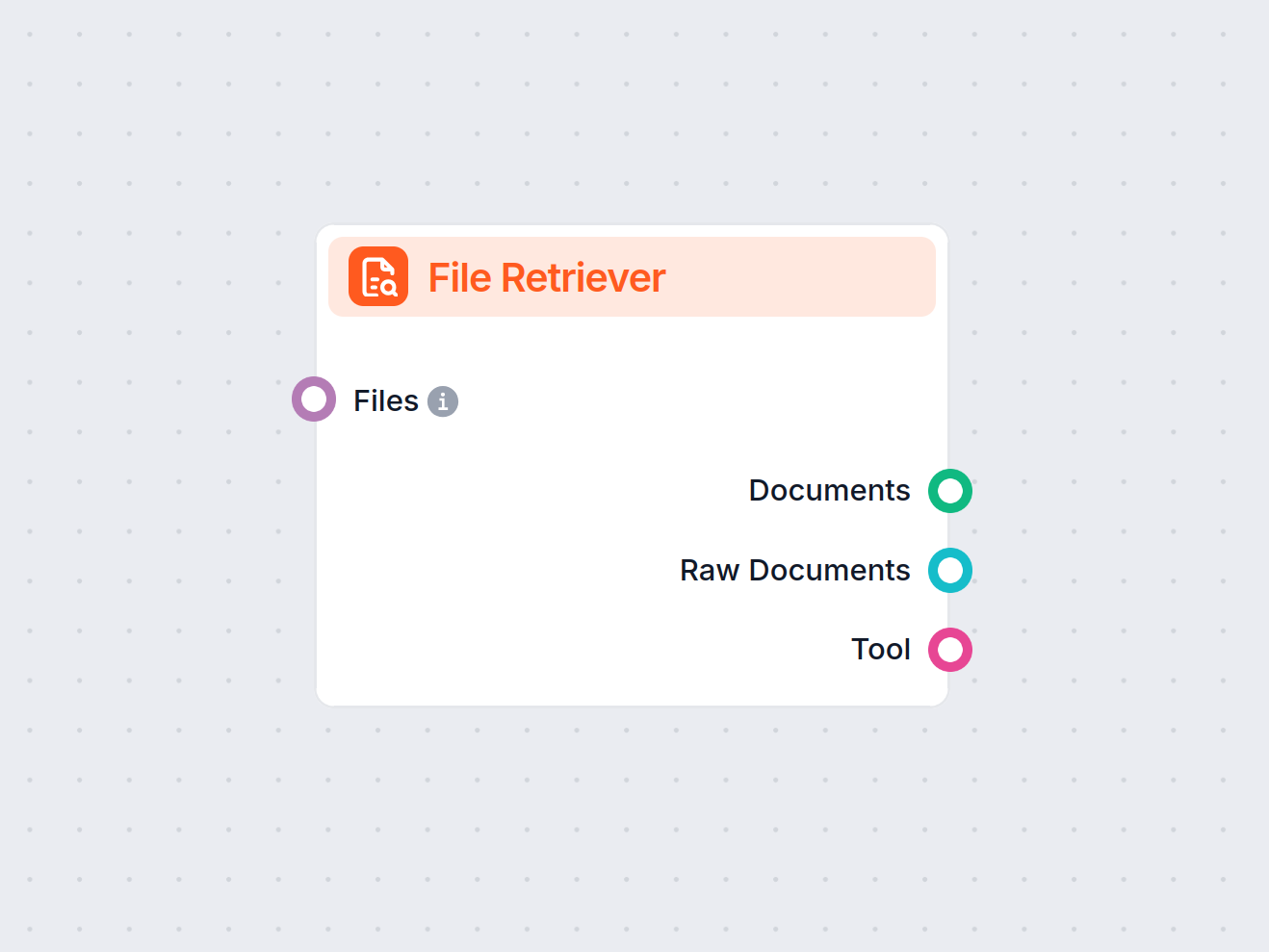
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Para ajudá-lo a começar rapidamente, preparamos vários modelos de fluxo de exemplo que demonstram como usar o componente Recuperador de URL de forma eficaz. Esses modelos apresentam diferentes casos de uso e melhores práticas, tornando mais fácil para você entender e implementar o componente em seus próprios projetos.
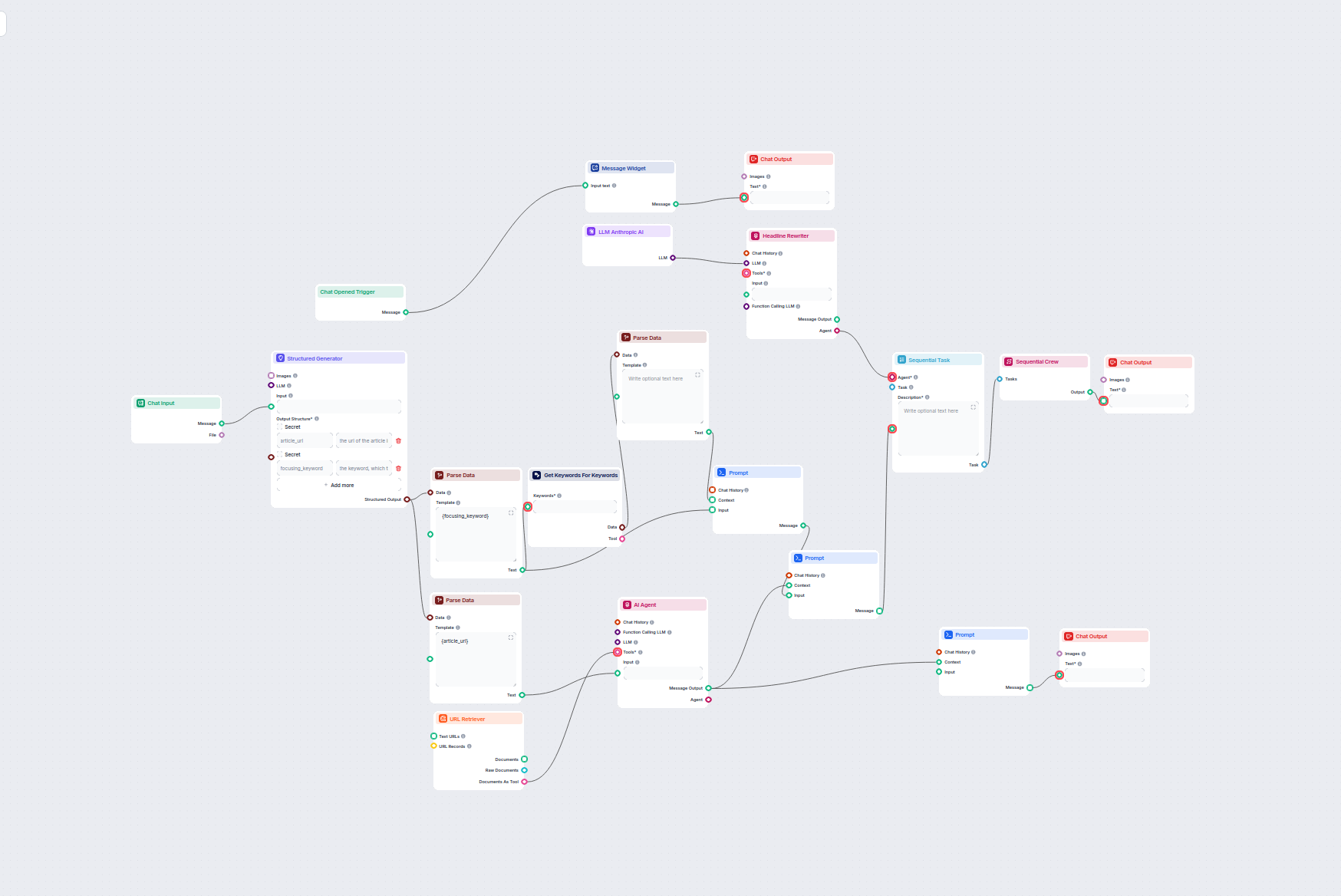
Gere postagens envolventes para o Instagram automaticamente, incluindo títulos chamativos, legendas criativas e imagens visualmente atraentes usando pesquisa e ...
Transforme qualquer URL de artigo ou página da web em um prompt detalhado e criativo para modelos de texto para imagem. Este fluxo busca o conteúdo da URL forne...
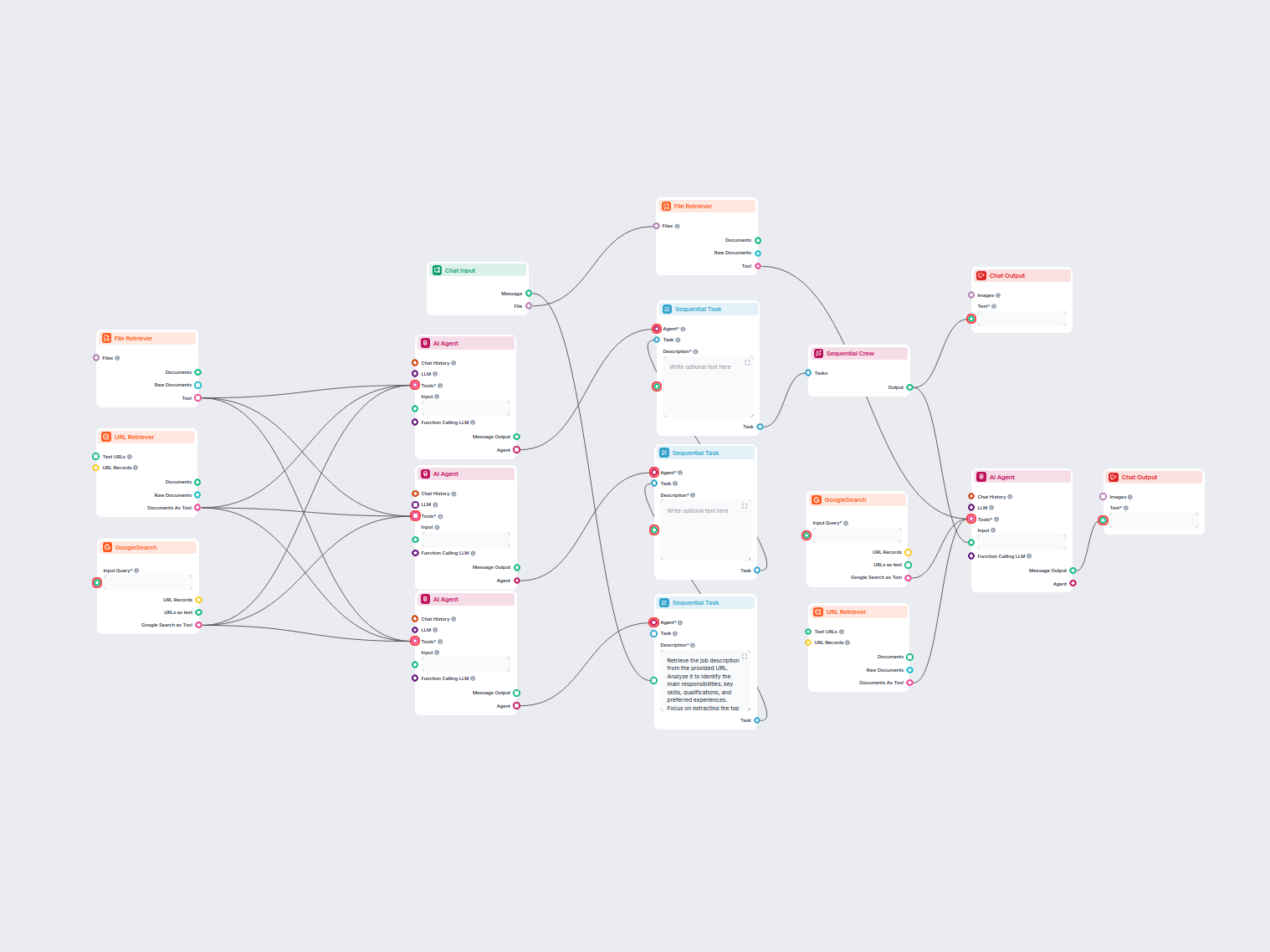
Gera automaticamente redações factuais e bem estruturadas no formato MLA, utilizando fontes confiáveis encontradas via pesquisa no Google. Ideal para estudantes...
Transforme automaticamente qualquer transcrição de vídeo do YouTube em conteúdo para página web otimizada para SEO. Insira uma URL do YouTube e receba um rascun...
Gera automaticamente uma imagem de destaque envolvente para qualquer postagem de blog ao analisar seu conteúdo. Basta fornecer a URL do blog e o fluxo usa IA pa...
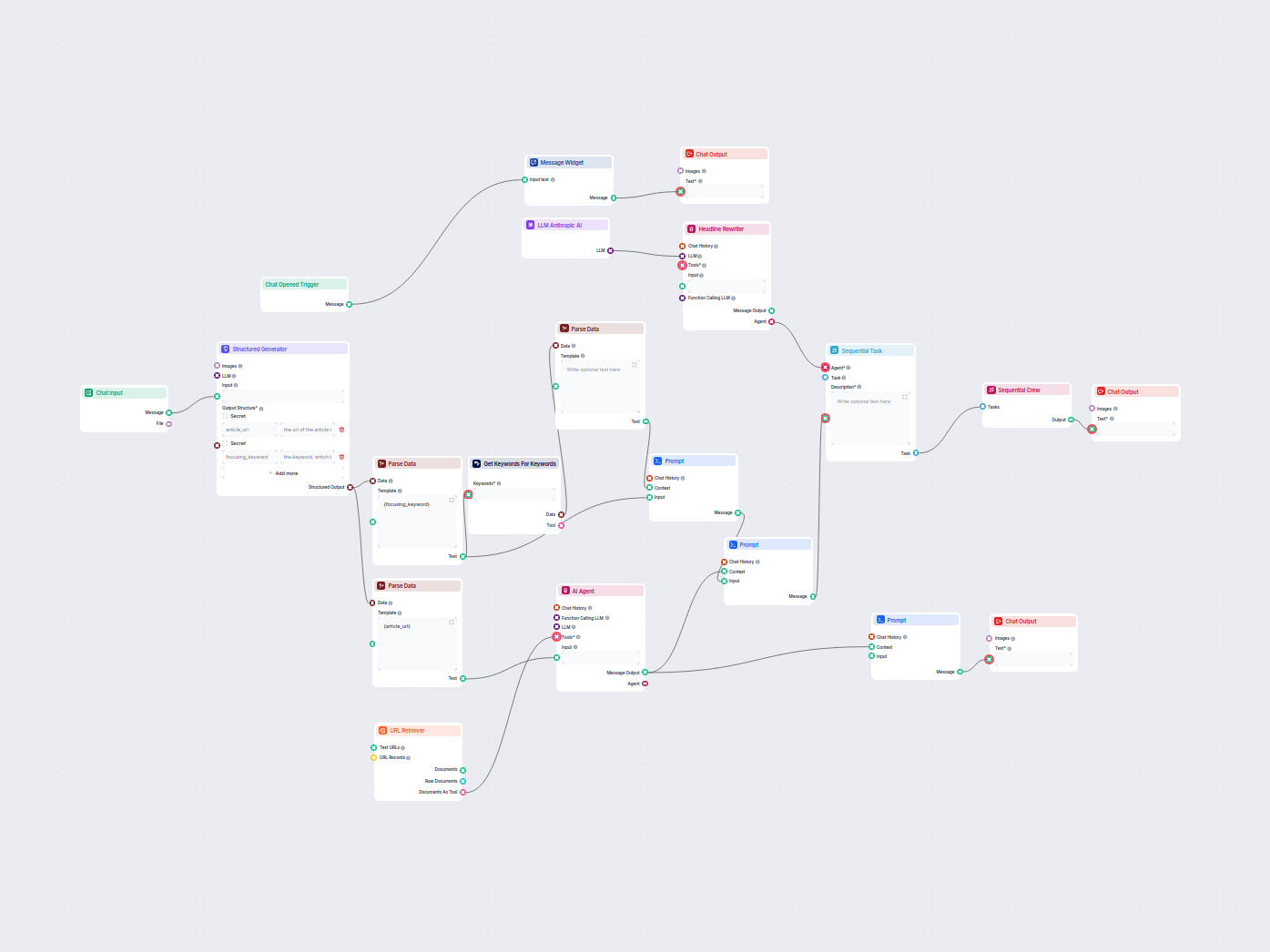
Otimize automaticamente os títulos e manchetes do seu artigo para uma palavra-chave ou cluster de palavras-chave específico, melhorando o desempenho em SEO. Est...
Esse fluxo de trabalho movido por IA encontra as melhores palavras-chave de SEO para seu artigo de blog e reescreve automaticamente os títulos para direcionar e...
Este fluxo de trabalho com IA agiliza o processo de personalização do CV do usuário para corresponder a uma vaga de emprego específica. Ao analisar tanto o CV o...
Este fluxo de trabalho com IA pesquisa o conteúdo já existente no blog de um site Wordpress, gera um novo post de blog otimizado para SEO sobre um tema único e ...
Cria automaticamente uma meta descrição envolvente e amigável para SEO para qualquer página da web, PDF, vídeo do YouTube ou link de documento, analisando seu c...
Gere rapidamente resumos concisos de qualquer página da web apenas fornecendo uma URL. Este fluxo de trabalho com IA recupera o conteúdo do link informado e pro...
Automatize o suporte ao cliente no LiveAgent com um chatbot de IA que responde perguntas usando sua base de conhecimento interna, recupera documentos relevantes...
Transforma automaticamente o conteúdo de qualquer URL fornecida em um post conciso e envolvente, adequado para o X (Twitter), ajudando profissionais de marketin...
Mostrando 61 a 73 de 73 resultados
O Recuperador de URL busca e processa conteúdo de links da web especificados, tornando texto e metadados de documentos online disponíveis para seu fluxo de trabalho ou agente de IA.
Sim, ao habilitar a opção OCR, o componente pode extrair texto de documentos baseados em imagem ou PDFs digitalizados.
Ele disponibiliza documentos processados como mensagens de texto, objetos de documento brutos ou como uma ferramenta para fluxos de trabalho de agentes, dependendo da sua configuração.
Você pode definir por quanto tempo o conteúdo recuperado será armazenado em cache, reduzindo downloads repetidos e acelerando seus fluxos.
Sim, você pode especificar quais títulos, parágrafos ou campos de metadados incluir na saída, permitindo uma extração direcionada.
Com certeza. O Recuperador de URL é essencial para qualquer automação ou chatbot que precise ler, processar ou resumir conteúdo da web em tempo real.
Impulsione seus fluxos de trabalho integrando conteúdo da web em tempo real. Extraia, processe e utilize dados de URLs com facilidade.
Integre seus fluxos de trabalho com o Google Docs usando o componente Google Docs Retriever—busque o conteúdo de documentos de forma transparente para usar em a...
O componente Recuperador de Arquivos no FlowHunt permite que você traga arquivos para seu fluxo de trabalho e os converta em documentos para processamento poste...
Pesquise e estude melhor resumindo o conteúdo de URLs com IA. Basta inserir a URL e obter insights essenciais imediatamente.