Perplexity AI
Perplexity AI é um avançado mecanismo de busca alimentado por IA e uma ferramenta conversacional que utiliza PLN e aprendizado de máquina para fornecer resposta...
6 min de leitura
AI
Search Engine
+5

A Busca por IA utiliza aprendizado de máquina e embeddings vetoriais para compreender a intenção e o contexto da busca, entregando resultados altamente relevantes além das correspondências exatas de palavras-chave.
A Busca por IA utiliza aprendizado de máquina para entender o contexto e a intenção das consultas de busca, transformando-as em vetores numéricos para resultados mais precisos. Diferente das buscas tradicionais por palavras-chave, a Busca por IA interpreta relações semânticas, tornando-se eficaz para diversos tipos de dados e idiomas.
A Busca por IA, frequentemente chamada de busca semântica ou vetorial, é uma metodologia de busca que aproveita modelos de aprendizado de máquina para entender a intenção e o significado contextual por trás das consultas de busca. Diferente da busca tradicional baseada em palavras-chave, a busca por IA transforma dados e consultas em representações numéricas conhecidas como vetores ou embeddings. Isso permite que o mecanismo de busca compreenda as relações semânticas entre diferentes pedaços de dados, fornecendo resultados mais relevantes e precisos mesmo quando as palavras-chave exatas não estão presentes.
A Busca por IA representa uma evolução significativa nas tecnologias de busca. Os mecanismos de busca tradicionais dependem fortemente da correspondência de palavras-chave, onde a presença de termos específicos tanto na consulta quanto nos documentos determina a relevância. A Busca por IA, no entanto, utiliza modelos de aprendizado de máquina para captar o contexto subjacente e o significado das consultas e dos dados.
Ao converter textos, imagens, áudios e outros dados não estruturados em vetores de alta dimensão, a Busca por IA pode medir a similaridade entre diferentes conteúdos. Essa abordagem permite que o mecanismo de busca entregue resultados contextualmente relevantes, mesmo que não contenham as palavras-chave exatas usadas na consulta.
Componentes Principais:
No núcleo da Busca por IA está o conceito de embeddings vetoriais. Embeddings vetoriais são representações numéricas dos dados que capturam o significado semântico de textos, imagens ou outros tipos de dados. Esses embeddings posicionam dados semelhantes próximos uns dos outros em um espaço vetorial multidimensional.
Como Funciona:
Exemplo:
Os mecanismos de busca tradicionais operam combinando termos na consulta de busca com documentos que contêm esses termos. Eles dependem de técnicas como índices invertidos e frequência de termos para ranquear resultados.
Limitações da Busca Baseada em Palavras-Chave:
Vantagens da Busca por IA:
| Aspecto | Busca por Palavras-chave | Busca por IA (Semântica/Vetorial) |
|---|---|---|
| Correspondência | Correspondência exata de palavras | Similaridade semântica |
| Consciência de Contexto | Limitada | Alta |
| Reconhecimento de Sinônimos | Requer listas manuais de sinônimos | Automático via embeddings |
| Erros de Digitação | Pode falhar sem busca difusa | Mais tolerante devido ao contexto semântico |
| Compreensão de Intenção | Mínima | Significativa |
A Busca Semântica é uma aplicação central da Busca por IA que foca em compreender a intenção do usuário e o significado contextual das consultas.
Processo:
Técnicas Principais:
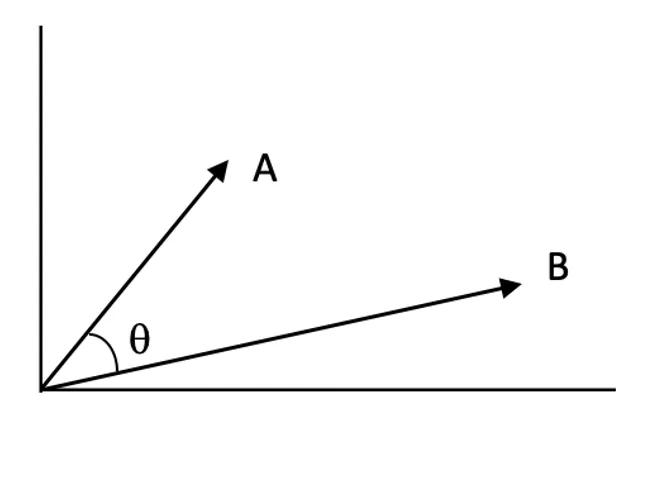
Escores de Similaridade:
Os escores de similaridade quantificam o quão relacionados dois vetores estão no espaço vetorial. Um escore mais alto indica maior relevância entre a consulta e um documento.
Algoritmos de Vizinho Mais Próximo Aproximado (ANN):
Encontrar vizinhos exatos em espaços de alta dimensão é computacionalmente intensivo. Algoritmos ANN fornecem aproximações eficientes.
A Busca por IA abre uma ampla gama de aplicações em diversos setores devido à sua capacidade de compreender e interpretar dados além da simples correspondência de palavras-chave.
Descrição: A Busca Semântica aprimora a experiência do usuário ao interpretar a intenção por trás das consultas e fornecer resultados contextualmente relevantes.
Exemplos:
Descrição: Ao compreender as preferências e o comportamento do usuário, a Busca por IA pode fornecer recomendações personalizadas de conteúdo ou produtos.
Exemplos:
Descrição: A Busca por IA permite que sistemas entendam e respondam a consultas dos usuários com informações precisas extraídas de documentos.
Exemplos:
Descrição: A Busca por IA pode indexar e pesquisar por tipos de dados não estruturados como imagens, áudios e vídeos convertendo-os em embeddings.
Exemplos:
Integrar a Busca por IA em automação e chatbots potencializa significativamente suas capacidades.
Benefícios:
Etapas de Implementação:
Exemplo de Caso de Uso:
Apesar das diversas vantagens, há desafios a serem considerados:
Estratégias de Mitigação:
A busca semântica e vetorial em IA emergiu como alternativa poderosa às buscas tradicionais por palavras-chave e busca difusa, aumentando significativamente a relevância e precisão dos resultados ao compreender o contexto e o significado das consultas.
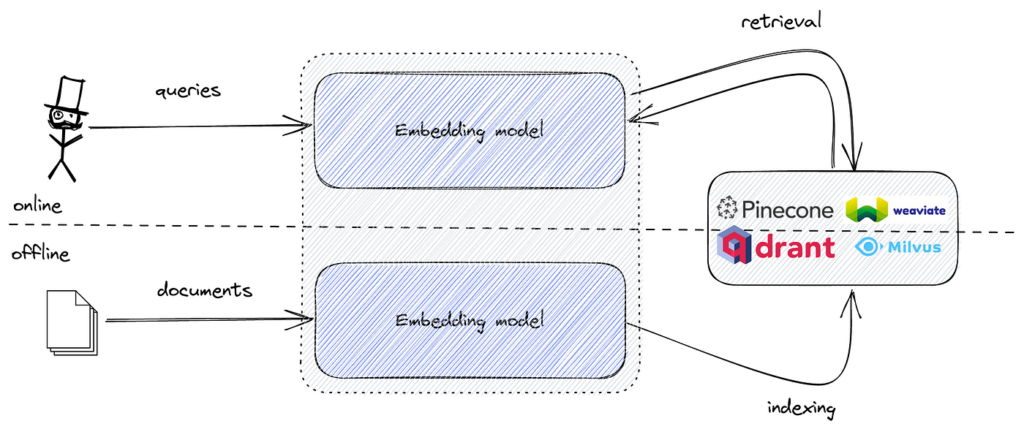
Ao implementar a busca semântica, os dados textuais são convertidos em embeddings vetoriais que capturam o significado semântico do texto. Esses embeddings são representações numéricas de alta dimensão. Para pesquisar esses embeddings de forma eficiente e encontrar os mais similares ao embedding da consulta, é necessário uma ferramenta otimizada para busca de similaridade em espaços de alta dimensão.
O FAISS fornece os algoritmos e estruturas de dados necessários para realizar essa tarefa com eficiência. Ao combinar embeddings semânticos com o FAISS, é possível criar um mecanismo de busca semântica poderoso, capaz de lidar com grandes volumes de dados com baixa latência.
A implementação de busca semântica com FAISS em Python envolve várias etapas:
Vamos detalhar cada etapa.
Prepare seu conjunto de dados (por exemplo, artigos, chamados de suporte, descrições de produtos).
Exemplo:
documents = [
"Como redefinir sua senha em nossa plataforma.",
"Resolução de problemas de conectividade de rede.",
"Guia para instalar atualizações de software.",
"Melhores práticas para backup e recuperação de dados.",
"Configurando autenticação em dois fatores para maior segurança."
]
Limpe e formate os textos conforme necessário.
Converta os dados textuais em embeddings vetoriais usando modelos Transformer pré-treinados de bibliotecas como Hugging Face (transformers ou sentence-transformers).
Exemplo:
from sentence_transformers import SentenceTransformer
import numpy as np
# Carregue um modelo pré-treinado
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Gere embeddings para todos os documentos
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 como requerido pelo FAISS.Crie um índice FAISS para armazenar os embeddings e permitir buscas por similaridade eficientes.
Exemplo:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 realiza busca exata usando distância L2 (Euclidiana).Converta a consulta do usuário em um embedding e encontre os vizinhos mais próximos.
Exemplo:
query = "Como faço para alterar minha senha da conta?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Use os índices para exibir os documentos mais relevantes.
Exemplo:
print("Principais resultados para sua consulta:")
for idx in indices[0]:
print(documents[idx])
Saída Esperada:
Principais resultados para sua consulta:
Como redefinir sua senha em nossa plataforma.
Configurando autenticação em dois fatores para maior segurança.
Melhores práticas para backup e recuperação de dados.
O FAISS oferece vários tipos de índices:
Utilizando um Índice de Arquivo Invertido (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalização e Busca por Produto Interno:
Usar similaridade cosseno pode ser mais eficaz para dados textuais
A Busca por IA é uma metodologia de busca moderna que utiliza aprendizado de máquina e embeddings vetoriais para entender a intenção e o significado contextual das consultas, entregando resultados mais precisos e relevantes do que a busca tradicional baseada em palavras-chave.
Diferentemente da busca baseada em palavras-chave, que depende de correspondências exatas, a Busca por IA interpreta as relações semânticas e a intenção por trás das consultas, tornando-a eficaz para linguagem natural e entradas ambíguas.
Embeddings vetoriais são representações numéricas de textos, imagens ou outros tipos de dados que capturam seu significado semântico, permitindo que o mecanismo de busca meça a similaridade e o contexto entre diferentes pedaços de dados.
A Busca por IA alimenta buscas semânticas em e-commerce, recomendações personalizadas em streaming, sistemas de perguntas e respostas em suporte ao cliente, navegação em dados não estruturados e recuperação de documentos em pesquisa e empresas.
Ferramentas populares incluem o FAISS para busca eficiente de similaridade vetorial e bancos de dados vetoriais como Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch e Pgvector para armazenamento e recuperação escaláveis de embeddings.
Ao integrar a Busca por IA, chatbots e sistemas de automação podem entender consultas dos usuários de forma mais profunda, recuperar respostas contextualmente relevantes e fornecer respostas dinâmicas e personalizadas.
Os desafios incluem altos requisitos computacionais, complexidade na interpretabilidade dos modelos, necessidade de dados de alta qualidade e garantia de privacidade e segurança com informações sensíveis.
O FAISS é uma biblioteca open-source para busca eficiente de similaridade em embeddings vetoriais de alta dimensão, amplamente usada para construir mecanismos de busca semântica capazes de lidar com conjuntos de dados de grande escala.
Descubra como a busca semântica com IA pode transformar sua recuperação de informações, chatbots e fluxos de automação.
Perplexity AI é um avançado mecanismo de busca alimentado por IA e uma ferramenta conversacional que utiliza PLN e aprendizado de máquina para fornecer resposta...
Descubra o que é um Motor de Insights—uma plataforma avançada, baseada em IA, que aprimora a busca e análise de dados ao compreender contexto e intenção. Saiba ...
A Recuperação de Informação utiliza IA, PLN e aprendizado de máquina para recuperar dados de forma eficiente e precisa de acordo com as necessidades do usuário....