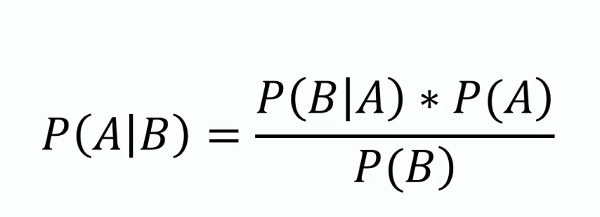
Redes Bayesianas
Uma Rede Bayesiana (RB) é um modelo gráfico probabilístico que representa variáveis e suas dependências condicionais por meio de um Grafo Acíclico Dirigido (DAG...
4 min de leitura
Bayesian Networks
AI
+3
Naive Bayes é uma família simples, porém poderosa, de algoritmos de classificação que utiliza o Teorema de Bayes, comumente usada para tarefas escaláveis como detecção de spam e classificação de texto.
Naive Bayes é uma família de algoritmos de classificação simples e eficazes baseados no Teorema de Bayes, assumindo independência condicional entre as características. É amplamente utilizado para detecção de spam, classificação de texto e muito mais devido à sua simplicidade e escalabilidade.
Naive Bayes é uma família de algoritmos de classificação baseada no Teorema de Bayes, que aplica o princípio da probabilidade condicional. O termo “naive” refere-se à suposição simplificadora de que todas as características em um conjunto de dados são condicionalmente independentes entre si, dado o rótulo da classe. Apesar de essa suposição ser frequentemente violada em dados do mundo real, classificadores Naive Bayes são reconhecidos por sua simplicidade e eficácia em várias aplicações, como classificação de texto e detecção de spam.
Teorema de Bayes
Este teorema forma a base do Naive Bayes, fornecendo um método para atualizar a estimativa de probabilidade de uma hipótese à medida que mais evidências ou informações se tornam disponíveis. Matematicamente, é expresso como:
onde ( P(A|B) ) é a probabilidade a posteriori, ( P(B|A) ) é a verossimilhança, ( P(A) ) é a probabilidade a priori, e ( P(B) ) é a evidência.
Independência Condicional
A suposição ingênua de que cada característica é independente de todas as outras, dado o rótulo da classe. Essa suposição simplifica o cálculo e permite que o algoritmo escale bem com grandes conjuntos de dados.
Probabilidade a Posteriori
A probabilidade do rótulo da classe dada os valores das características, calculada usando o Teorema de Bayes. Este é o componente central na realização de previsões com Naive Bayes.
Tipos de Classificadores Naive Bayes
Classificadores Naive Bayes funcionam calculando a probabilidade a posteriori para cada classe, dado um conjunto de características, e selecionando a classe com a maior probabilidade a posteriori. O processo envolve os seguintes passos:
Classificadores Naive Bayes são particularmente eficazes nas seguintes aplicações:
Considere uma aplicação de filtro de spam usando Naive Bayes. Os dados de treinamento consistem em e-mails rotulados como “spam” ou “não spam”. Cada e-mail é representado por um conjunto de características, como a presença de palavras específicas. Durante o treinamento, o algoritmo calcula a probabilidade de cada palavra dada o rótulo da classe. Para um novo e-mail, o algoritmo calcula a probabilidade a posteriori para “spam” e “não spam” e atribui o rótulo com a maior probabilidade.
Classificadores Naive Bayes podem ser integrados a sistemas de IA e chatbots para aprimorar suas capacidades de processamento de linguagem natural, servindo de ponte para a interação humano-computador. Por exemplo, eles podem ser usados para detectar a intenção de consultas de usuários, classificar textos em categorias predefinidas ou filtrar conteúdo inadequado. Essa funcionalidade melhora a qualidade e a relevância das interações em soluções baseadas em IA. Além disso, a eficiência do algoritmo o torna adequado para aplicações em tempo real, um aspecto importante para automação de IA e sistemas de chatbot.
Naive Bayes é uma família de algoritmos probabilísticos simples, mas poderosos, baseada na aplicação do teorema de Bayes com fortes suposições de independência entre as características. É amplamente utilizado para tarefas de classificação devido à sua simplicidade e eficácia. Aqui estão alguns artigos científicos que discutem diversas aplicações e melhorias do classificador Naive Bayes:
Improving spam filtering by combining Naive Bayes with simple k-nearest neighbor searches
Autor: Daniel Etzold
Publicado: 30 de novembro de 2003
Este artigo explora o uso de Naive Bayes para classificação de e-mails, destacando sua facilidade de implementação e eficiência. O estudo apresenta resultados empíricos mostrando como a combinação do Naive Bayes com buscas por k-vizinhos mais próximos pode aumentar a precisão do filtro de spam. A combinação proporcionou melhorias leves de precisão com um grande número de características e melhorias significativas com menos características. Leia o artigo.
Locally Weighted Naive Bayes
Autores: Eibe Frank, Mark Hall, Bernhard Pfahringer
Publicado: 19 de outubro de 2012
Este artigo aborda a principal fraqueza do Naive Bayes, que é a suposição de independência entre atributos. Ele introduz uma versão ponderada localmente do Naive Bayes, que aprende modelos locais no momento da predição, relaxando assim a suposição de independência. Os resultados experimentais demonstram que essa abordagem raramente diminui a precisão e frequentemente a melhora significativamente. O método é elogiado por sua simplicidade conceitual e computacional em comparação com outras técnicas. Leia o artigo.
Naive Bayes Entrapment Detection for Planetary Rovers
Autor: Dicong Qiu
Publicado: 31 de janeiro de 2018
Neste estudo, discute-se a aplicação de classificadores Naive Bayes para detecção de aprisionamento em robôs planetários. São definidos os critérios de aprisionamento do robô e demonstrado o uso do Naive Bayes na detecção desses cenários. O artigo detalha experimentos realizados com robôs AutoKrawler, fornecendo insights sobre a eficácia do Naive Bayes em procedimentos autônomos de resgate. Leia o artigo.
Naive Bayes é uma família de algoritmos de classificação baseada no Teorema de Bayes, que assume que todas as características são condicionalmente independentes dado o rótulo da classe. É amplamente utilizado para classificação de texto, filtragem de spam e análise de sentimento.
Os principais tipos são Gaussian Naive Bayes (para características contínuas), Multinomial Naive Bayes (para características discretas, como contagem de palavras) e Bernoulli Naive Bayes (para características binárias/booleanas).
Naive Bayes é simples de implementar, computacionalmente eficiente, escalável para grandes conjuntos de dados e lida bem com dados de alta dimensionalidade.
Sua principal limitação é a suposição de independência entre as características, o que muitas vezes não é verdade para dados do mundo real. Também pode atribuir probabilidade zero a características não vistas, o que pode ser mitigado com técnicas como suavização de Laplace.
Naive Bayes é utilizado em sistemas de IA e chatbots para detecção de intenção, classificação de texto, filtragem de spam e análise de sentimento, aprimorando as capacidades de processamento de linguagem natural e possibilitando tomada de decisão em tempo real.
Chatbots inteligentes e ferramentas de IA em um só lugar. Conecte blocos intuitivos para transformar suas ideias em Fluxos automatizados.
Uma Rede Bayesiana (RB) é um modelo gráfico probabilístico que representa variáveis e suas dependências condicionais por meio de um Grafo Acíclico Dirigido (DAG...
Um classificador de IA é um algoritmo de aprendizado de máquina que atribui rótulos de classe a dados de entrada, categorizando informações em classes predefini...
A classificação de texto, também conhecida como categorização ou marcação de texto, é uma tarefa central de PLN que atribui categorias predefinidas a documentos...