
Geração Aumentada por Recuperação (RAG)
A Geração Aumentada por Recuperação (RAG) é uma estrutura avançada de IA que combina sistemas tradicionais de recuperação de informações com grandes modelos de ...
4 min de leitura
RAG
AI
+4

A Resposta a Perguntas com RAG aprimora LLMs ao integrar recuperação de dados em tempo real e geração de linguagem natural para respostas precisas e contextualmente relevantes.
A Resposta a Perguntas com Geração Aumentada por Recuperação (RAG) aprimora modelos de linguagem ao integrar dados externos em tempo real para respostas precisas e relevantes. Ela otimiza o desempenho em campos dinâmicos, oferecendo maior precisão, conteúdo dinâmico e relevância aprimorada.
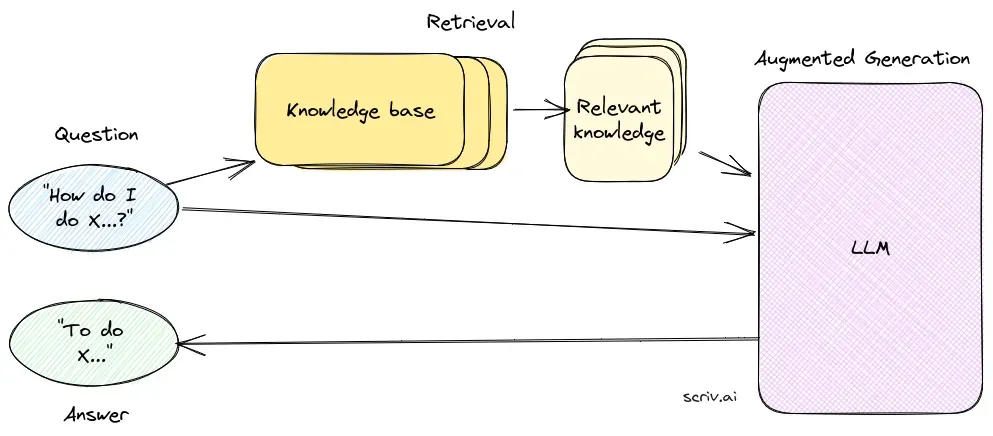
Resposta a Perguntas com Geração Aumentada por Recuperação (RAG) é um método inovador que combina as forças da recuperação de informações e da geração de linguagem natural, criando texto semelhante ao humano a partir de dados, aprimorando IA, chatbots, relatórios e personalizando experiências. Essa abordagem híbrida amplia as capacidades dos grandes modelos de linguagem (LLMs) ao suplementar suas respostas com informações relevantes e atualizadas recuperadas de fontes de dados externas. Ao contrário dos métodos tradicionais que dependem apenas de modelos pré-treinados, o RAG integra dados externos de forma dinâmica, permitindo que os sistemas forneçam respostas mais precisas e contextualmente relevantes, especialmente em domínios que exigem as informações mais recentes ou conhecimento especializado.
O RAG otimiza o desempenho dos LLMs ao garantir que as respostas não sejam apenas geradas a partir de um conjunto de dados interno, mas também informadas por fontes em tempo real e autoritativas. Essa abordagem é fundamental para tarefas de resposta a perguntas em áreas dinâmicas, onde a informação está em constante evolução.
O componente de recuperação é responsável por buscar informações relevantes em grandes conjuntos de dados, normalmente armazenados em um banco de dados vetorial. Esse componente utiliza técnicas de busca semântica para identificar e extrair segmentos de texto ou documentos altamente relevantes para a consulta do usuário.
O componente de geração, geralmente um LLM como GPT-3 ou BERT, sintetiza uma resposta combinando a consulta original do usuário com o contexto recuperado. Esse componente é fundamental para gerar respostas coerentes e contextualmente adequadas.
Implementar um sistema RAG envolve várias etapas técnicas:
Pesquisa sobre Resposta a Perguntas com Geração Aumentada por Recuperação (RAG)
A Geração Aumentada por Recuperação (RAG) é um método que aprimora sistemas de resposta a perguntas ao combinar mecanismos de recuperação com modelos generativos. Pesquisas recentes têm explorado a eficácia e a otimização do RAG em diversos contextos.
RAG é um método que combina recuperação de informações e geração de linguagem natural para fornecer respostas precisas e atualizadas, integrando fontes de dados externas em grandes modelos de linguagem.
Um sistema RAG consiste em um componente de recuperação, que busca informações relevantes em bancos de dados vetoriais utilizando busca semântica, e um componente de geração, geralmente um LLM, que sintetiza respostas usando tanto a consulta do usuário quanto o contexto recuperado.
RAG melhora a precisão ao recuperar informações contextualmente relevantes, suporta atualizações dinâmicas de conteúdo a partir de bases de conhecimento externas e aumenta a relevância e qualidade das respostas geradas.
Casos de uso comuns incluem chatbots de IA, suporte ao cliente, criação automatizada de conteúdo e ferramentas educacionais que exigem respostas precisas, com conhecimento de contexto e atualizadas.
Sistemas RAG podem exigir muitos recursos, necessitam de integração cuidadosa para desempenho ideal e devem garantir precisão factual nas informações recuperadas para evitar respostas enganosas ou desatualizadas.
Descubra como a Geração Aumentada por Recuperação pode impulsionar seu chatbot e soluções de suporte com respostas precisas e em tempo real.
A Geração Aumentada por Recuperação (RAG) é uma estrutura avançada de IA que combina sistemas tradicionais de recuperação de informações com grandes modelos de ...
Descubra as principais diferenças entre Geração com Recuperação (RAG) e Geração com Cache (CAG) em IA. Saiba como o RAG recupera informações em tempo real para ...
As Fontes de Conhecimento tornam o ensino da IA de acordo com suas necessidades muito fácil. Descubra todas as formas de vincular conhecimento com o FlowHunt. C...