Gerar descrições a partir de imagens
Aprenda como automatizar a criação de textos descritivos a partir de imagens usando a API e o construtor de fluxos do FlowHunt.io, aprimorando a presença online...
4 min de leitura
AI
Image Description
+5
Aprenda como automatizar a criação de textos descritivos a partir de imagens usando a API e o construtor de fluxos do FlowHunt.io, aprimorando a presença online...
Gestão de Projetos de IA em P&D refere-se à aplicação estratégica de tecnologias de inteligência artificial (IA) e aprendizado de máquina (ML) para aprimorar a ...
O Google Colaboratory (Google Colab) é uma plataforma de Jupyter notebook baseada na nuvem oferecida pelo Google, permitindo que os usuários escrevam e executem...
O Gradient Boosting é uma poderosa técnica de ensemble em machine learning para regressão e classificação. Ele constrói modelos sequencialmente, geralmente com ...
Heurísticas fornecem soluções rápidas e satisfatórias em IA ao aproveitar conhecimento experiencial e regras práticas, simplificando problemas complexos de busc...
Horovod é uma estrutura robusta e de código aberto para treinamento distribuído de deep learning, projetada para facilitar o escalonamento eficiente em múltipla...
Human-in-the-Loop (HITL) é uma abordagem de IA e aprendizado de máquina que integra a experiência humana no treinamento, ajuste e aplicação de sistemas de IA, a...
IA Conversacional refere-se a tecnologias que permitem que computadores simulem conversas humanas usando PLN, aprendizado de máquina e outras tecnologias de lin...
Explore como a Inteligência Artificial impacta os direitos humanos, equilibrando benefícios como o acesso aprimorado a serviços com riscos como violações de pri...
A Inteligência Artificial (IA) na cibersegurança utiliza tecnologias de IA, como aprendizado de máquina e PLN, para detectar, prevenir e responder a ameaças cib...
A Inteligência Artificial (IA) na manufatura está transformando a produção ao integrar tecnologias avançadas para aumentar a produtividade, eficiência e tomada ...
A Inteligência Artificial (IA) na saúde utiliza algoritmos avançados e tecnologias como aprendizado de máquina, PLN e deep learning para analisar dados médicos ...
A IA está revolucionando o entretenimento, aprimorando jogos, filmes e música por meio de interações dinâmicas, personalização e evolução de conteúdo em tempo r...
A Inteligência Artificial (IA) no varejo utiliza tecnologias avançadas como aprendizado de máquina, PLN, visão computacional e robótica para aprimorar a experiê...
Descubra como a IA está transformando o SEO ao automatizar pesquisas de palavras-chave, otimização de conteúdo e engajamento do usuário. Explore estratégias-cha...
Inferência causal é uma abordagem metodológica usada para determinar as relações de causa e efeito entre variáveis, crucial nas ciências para compreender mecani...
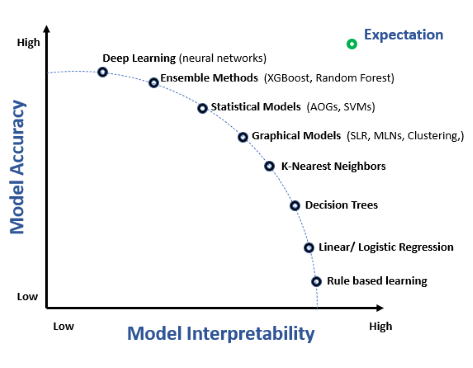
Interpretabilidade de modelos refere-se à capacidade de entender, explicar e confiar nas previsões e decisões tomadas por modelos de aprendizado de máquina. É f...
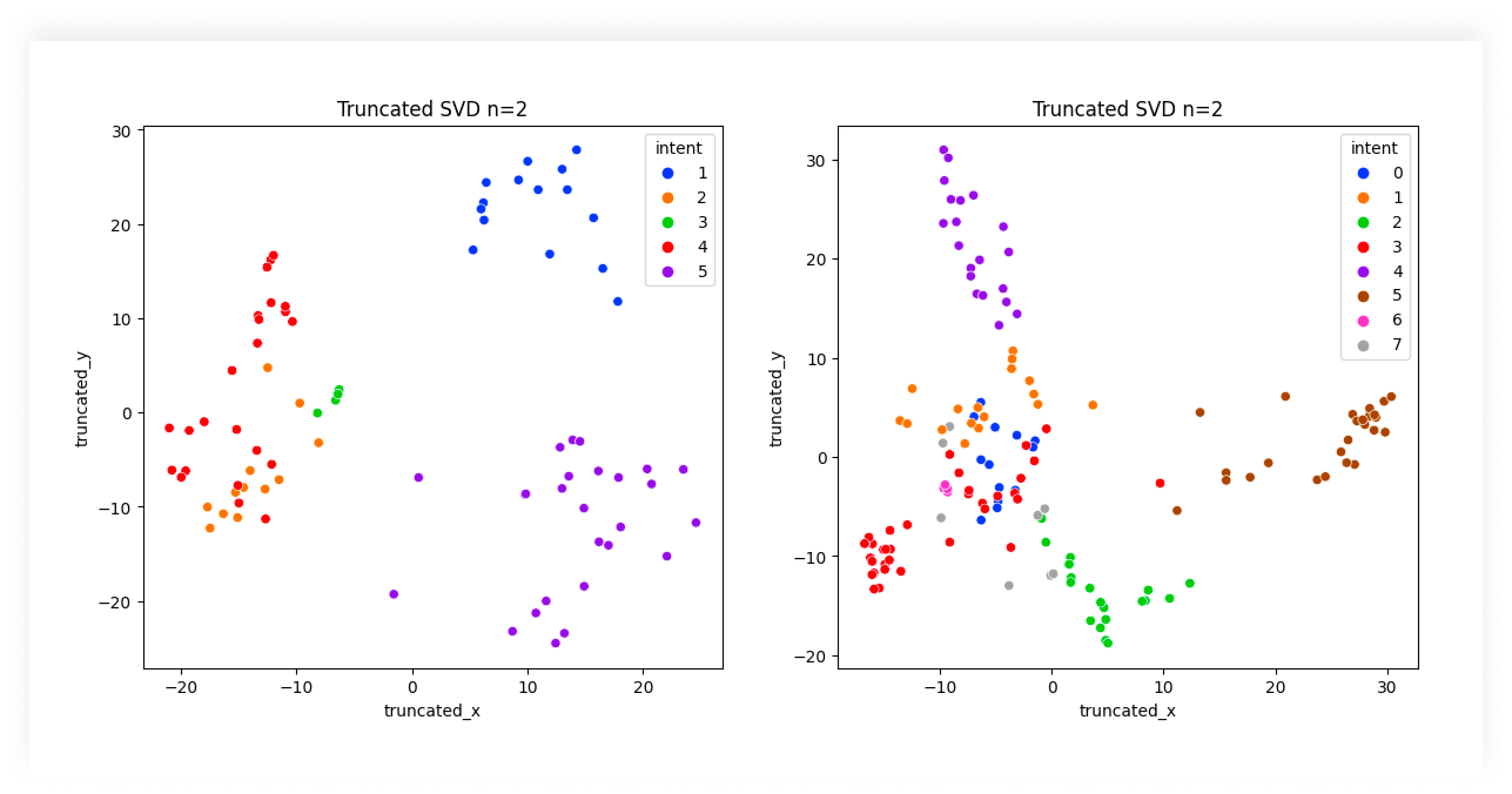
Descubra o papel essencial da Classificação de Intenções em IA para aprimorar as interações dos usuários com a tecnologia, melhorar o suporte ao cliente e otimi...
Jupyter Notebook é um aplicativo web de código aberto que permite aos usuários criar e compartilhar documentos com código executável, equações, visualizações e ...
O algoritmo k-vizinhos mais próximos (KNN) é um algoritmo de aprendizado supervisionado não paramétrico usado para tarefas de classificação e regressão em apren...
O Kaggle é uma comunidade online e plataforma para cientistas de dados e engenheiros de machine learning colaborarem, aprenderem, competirem e compartilharem in...
Keras é uma API open-source poderosa e fácil de usar para redes neurais de alto nível, escrita em Python e capaz de rodar sobre TensorFlow, CNTK ou Theano. Ela ...
KNIME (Konstanz Information Miner) é uma poderosa plataforma open-source de análise de dados que oferece fluxos de trabalho visuais, integração de dados sem int...
Kubeflow é uma plataforma de machine learning (ML) de código aberto baseada em Kubernetes, que simplifica a implantação, o gerenciamento e a escalabilidade de f...
LightGBM, ou Light Gradient Boosting Machine, é uma estrutura avançada de gradient boosting desenvolvida pela Microsoft. Projetada para tarefas de aprendizado d...
A limpeza de dados é o processo crucial de detectar e corrigir erros ou inconsistências nos dados para aprimorar sua qualidade, garantindo precisão, consistênci...
Lixo Entra, Lixo Sai (GIGO) destaca como a qualidade do resultado de sistemas de IA e outros sistemas depende diretamente da qualidade da entrada. Saiba mais so...
O marketing impulsionado por IA utiliza tecnologias de inteligência artificial como machine learning, PLN e análises preditivas para automatizar tarefas, obter ...
O Marketing Personalizado com IA aproveita a inteligência artificial para adaptar estratégias e comunicações de marketing aos clientes individuais com base em c...
Uma matriz de confusão é uma ferramenta de aprendizado de máquina para avaliar o desempenho de modelos de classificação, detalhando verdadeiros/falsos positivos...
A mineração de dados é um processo sofisticado de análise de grandes conjuntos de dados brutos para descobrir padrões, relacionamentos e insights que podem orie...
O MLflow é uma plataforma de código aberto projetada para simplificar e gerenciar o ciclo de vida do aprendizado de máquina (ML). Ela fornece ferramentas para r...
A modelagem preditiva é um processo sofisticado em ciência de dados e estatística que prevê resultados futuros ao analisar padrões históricos de dados. Ela util...
O Modelo de Linguagem Pathways (PaLM) é a avançada família de grandes modelos de linguagem da Google, projetada para aplicações versáteis como geração de texto,...
O Modelo Flux AI da Black Forest Labs é um avançado sistema de geração de imagens a partir de texto que converte comandos em linguagem natural em imagens altame...
Um Modelo Fundamental de IA é um modelo de aprendizado de máquina em larga escala treinado com enormes quantidades de dados, adaptável a uma ampla variedade de ...
Modelos Ocultos de Markov (HMMs) são modelos estatísticos sofisticados para sistemas onde os estados subjacentes são inobserváveis. Amplamente utilizados em rec...
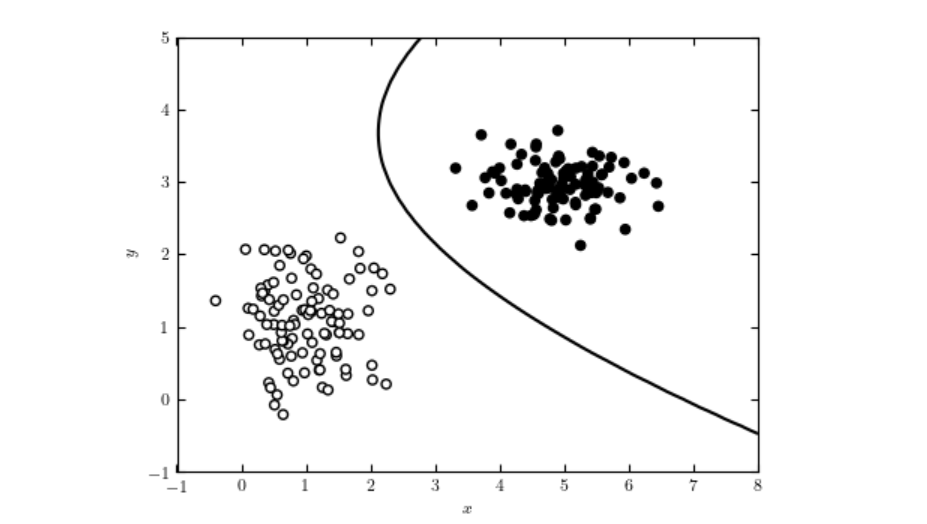
Saiba mais sobre Modelos de IA Discriminativos—modelos de aprendizado de máquina focados em classificação e regressão por meio da modelagem das fronteiras de de...
Descubra o que é um Motor de Insights—uma plataforma avançada, baseada em IA, que aprimora a busca e análise de dados ao compreender contexto e intenção. Saiba ...
O Apache MXNet é um framework de deep learning open-source projetado para treinamento e implantação eficientes e flexíveis de redes neurais profundas. Conhecido...
Naive Bayes é uma família de algoritmos de classificação baseada no Teorema de Bayes, aplicando probabilidade condicional com a suposição simplificadora de que ...
Natural Language Toolkit (NLTK) é um conjunto abrangente de bibliotecas e programas em Python para processamento de linguagem natural (PLN) simbólico e estatíst...
Plataformas de IA No-Code permitem que usuários criem, implantem e gerenciem modelos de IA e machine learning sem escrever código. Essas plataformas oferecem in...
A normalização em lote é uma técnica transformadora em deep learning que aprimora significativamente o processo de treinamento de redes neurais ao lidar com o d...
NumPy é uma biblioteca Python de código aberto crucial para computação numérica, oferecendo operações eficientes com arrays e funções matemáticas. Ela fundament...
Descubra como a IA agente e os sistemas multiagentes revolucionam a automação de fluxos de trabalho com tomada de decisão autônoma, adaptabilidade e colaboração...
Fastai é uma biblioteca de deep learning construída sobre o PyTorch, oferecendo APIs de alto nível, aprendizado por transferência e uma arquitetura em camadas p...
Open Neural Network Exchange (ONNX) é um formato de código aberto para a troca fluida de modelos de aprendizado de máquina entre diferentes frameworks, ampliand...
A OpenAI é uma organização líder em pesquisa de inteligência artificial, conhecida pelo desenvolvimento do GPT, DALL-E e ChatGPT, e tem como objetivo criar uma ...
OpenCV é uma biblioteca avançada de visão computacional e aprendizado de máquina de código aberto, oferecendo mais de 2500 algoritmos para processamento de imag...
Overfitting é um conceito crítico em inteligência artificial (IA) e aprendizado de máquina (ML), ocorrendo quando um modelo aprende excessivamente os dados de t...
Pandas é uma biblioteca open-source para manipulação e análise de dados em Python, reconhecida por sua versatilidade, estruturas de dados robustas e facilidade ...
A perda logarítmica, ou perda logarítmica/entropia cruzada, é uma métrica fundamental para avaliar o desempenho de modelos de machine learning—especialmente par...
Perplexity AI é um avançado mecanismo de busca alimentado por IA e uma ferramenta conversacional que utiliza PLN e aprendizado de máquina para fornecer resposta...
Um pipeline de machine learning é um fluxo de trabalho automatizado que simplifica e padroniza o desenvolvimento, treinamento, avaliação e implantação de modelo...
Descubra a importância da precisão e estabilidade de modelos de IA em machine learning. Saiba como esses indicadores impactam aplicações como detecção de fraude...
A previsão financeira é um processo analítico sofisticado utilizado para prever os resultados financeiros futuros de uma empresa por meio da análise de dados hi...
O Processamento de Linguagem Natural (PLN) permite que computadores compreendam, interpretem e gerem linguagem humana utilizando linguística computacional, apre...
O Processamento de Linguagem Natural (PLN) é um subcampo da inteligência artificial (IA) que permite aos computadores compreenderem, interpretarem e gerarem lin...
PyTorch é uma estrutura de aprendizado de máquina de código aberto desenvolvida pela Meta AI, conhecida por sua flexibilidade, gráficos computacionais dinâmicos...
Q-learning é um conceito fundamental em inteligência artificial (IA) e aprendizado de máquina, especialmente dentro do aprendizado por reforço. Ele permite que ...
O R-quadrado ajustado é uma medida estatística usada para avaliar a qualidade do ajuste de um modelo de regressão, levando em conta o número de preditores para ...
O raciocínio é o processo cognitivo de tirar conclusões, fazer inferências ou resolver problemas com base em informações, fatos e lógica. Explore sua importânci...
Explore o recall em aprendizado de máquina: uma métrica crucial para avaliar o desempenho do modelo, especialmente em tarefas de classificação onde identificar ...
O Reconhecimento de Entidades Nomeadas (NER) é um subcampo fundamental do Processamento de Linguagem Natural (PLN) na IA, focado na identificação e classificaçã...
O reconhecimento de fala, também conhecido como reconhecimento automático de fala (ASR) ou conversão de fala em texto, permite que computadores interpretem e co...
Descubra o que é Reconhecimento de Imagens em IA. Para que serve, quais são as tendências e como se diferencia de tecnologias semelhantes.
O reconhecimento de padrões é um processo computacional para identificar padrões e regularidades em dados, fundamental em áreas como IA, ciência da computação, ...
O Reconhecimento Óptico de Caracteres (OCR) é uma tecnologia transformadora que converte documentos como papéis digitalizados, PDFs ou imagens em dados editávei...
Explore a Reconstrução 3D: Saiba como esse processo avançado captura objetos ou ambientes do mundo real e os transforma em modelos 3D detalhados usando técnicas...
A Recuperação de Informação utiliza IA, PLN e aprendizado de máquina para recuperar dados de forma eficiente e precisa de acordo com as necessidades do usuário....
Uma Rede Generativa Adversarial (GAN) é uma estrutura de aprendizado de máquina composta por duas redes neurais—um gerador e um discriminador—que competem para ...
Uma Rede Bayesiana (RB) é um modelo gráfico probabilístico que representa variáveis e suas dependências condicionais por meio de um Grafo Acíclico Dirigido (DAG...
Uma Rede de Crença Profunda (DBN) é um sofisticado modelo generativo que utiliza arquiteturas profundas e Máquinas de Boltzmann Restritas (RBMs) para aprender r...
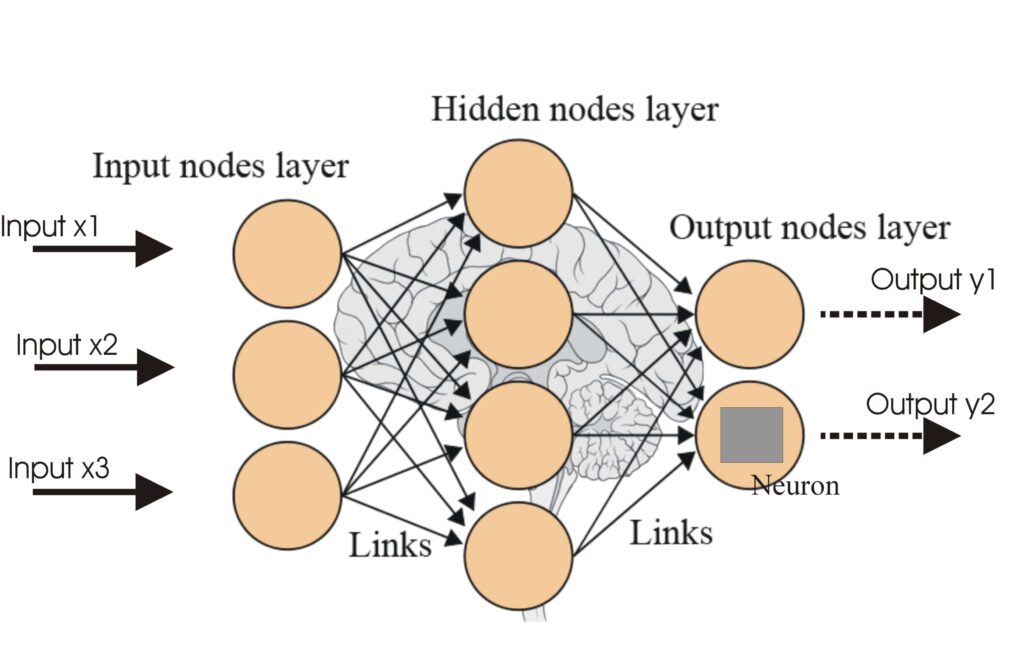
Uma rede neural, ou rede neural artificial (RNA), é um modelo computacional inspirado no cérebro humano, essencial em IA e aprendizado de máquina para tarefas c...
Redes Neurais Artificiais (ANNs) são um subconjunto de algoritmos de aprendizado de máquina inspirados no cérebro humano. Esses modelos computacionais consistem...
A redução de dimensionalidade é uma técnica fundamental no processamento de dados e aprendizado de máquina, reduzindo o número de variáveis de entrada em um con...
A regressão linear é uma técnica analítica fundamental em estatística e aprendizado de máquina, modelando a relação entre variáveis dependentes e independentes....
A regressão logística é um método estatístico e de aprendizado de máquina utilizado para prever desfechos binários a partir de dados. Ela estima a probabilidade...
A Regressão por Floresta Aleatória é um poderoso algoritmo de aprendizado de máquina usado para análises preditivas. Ela constrói múltiplas árvores de decisão e...
Regularização em inteligência artificial (IA) refere-se a um conjunto de técnicas usadas para evitar overfitting em modelos de aprendizado de máquina, introduzi...
A resolução de correferência é uma tarefa fundamental de PLN que identifica e vincula expressões em um texto que se referem à mesma entidade, sendo crucial para...
A retropropagação é um algoritmo para treinar redes neurais artificiais ajustando pesos para minimizar o erro de previsão. Saiba como funciona, seus passos e se...
A Inteligência Artificial (IA) na revisão de documentos jurídicos representa uma mudança significativa na forma como os profissionais do Direito lidam com o gra...
A robustez do modelo refere-se à capacidade de um modelo de aprendizado de máquina (ML) de manter desempenho consistente e preciso, apesar de variações e incert...
Scikit-learn é uma poderosa biblioteca de aprendizado de máquina de código aberto para Python, oferecendo ferramentas simples e eficientes para análise preditiv...
SciPy é uma robusta biblioteca open-source em Python para computação científica e técnica. Baseando-se no NumPy, oferece algoritmos matemáticos avançados, otimi...
Descubra o que é um SDR de IA e como os Representantes de Desenvolvimento de Vendas com Inteligência Artificial automatizam a prospecção, qualificação de leads,...
Um Sistema de Automação com IA integra tecnologias de inteligência artificial com processos de automação, aprimorando a automação tradicional com habilidades co...
spaCy é uma robusta biblioteca Python de código aberto para Processamento de Linguagem Natural (PLN) avançado, conhecida por sua velocidade, eficiência e recurs...
Stable Diffusion é um modelo avançado de geração de imagens a partir de texto que utiliza aprendizado profundo para produzir imagens fotorrealistas de alta qual...
Uma startup impulsionada por IA é um negócio que centra suas operações, produtos ou serviços em tecnologias de inteligência artificial para inovar, automatizar ...
A Superinteligência Artificial (ASI) é uma IA teórica que supera a inteligência humana em todos os domínios, com capacidades multimodais e de autoaperfeiçoament...
Tendências da tecnologia de IA abrangem avanços atuais e emergentes em inteligência artificial, incluindo aprendizado de máquina, grandes modelos de linguagem, ...
Explore as principais tendências de IA para 2025, incluindo o surgimento de agentes de IA e equipes de IA, e descubra como essas inovações estão transformando i...
TensorFlow é uma biblioteca de código aberto desenvolvida pela equipe do Google Brain, projetada para computação numérica e aprendizado de máquina em larga esca...
Torch é uma biblioteca de aprendizado de máquina de código aberto e um framework de computação científica baseado em Lua, otimizado para tarefas de deep learnin...
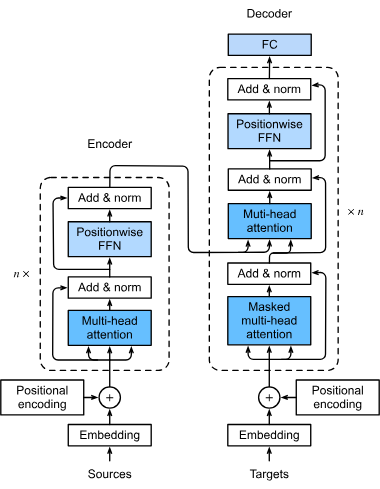
Transformers são uma arquitetura revolucionária de redes neurais que transformou a inteligência artificial, especialmente no processamento de linguagem natural....
Hugging Face Transformers é uma biblioteca Python open-source líder que facilita a implementação de modelos Transformer para tarefas de machine learning em PLN,...
Transparência algorítmica refere-se à clareza e abertura em relação ao funcionamento interno e aos processos de tomada de decisão dos algoritmos. É crucial em I...