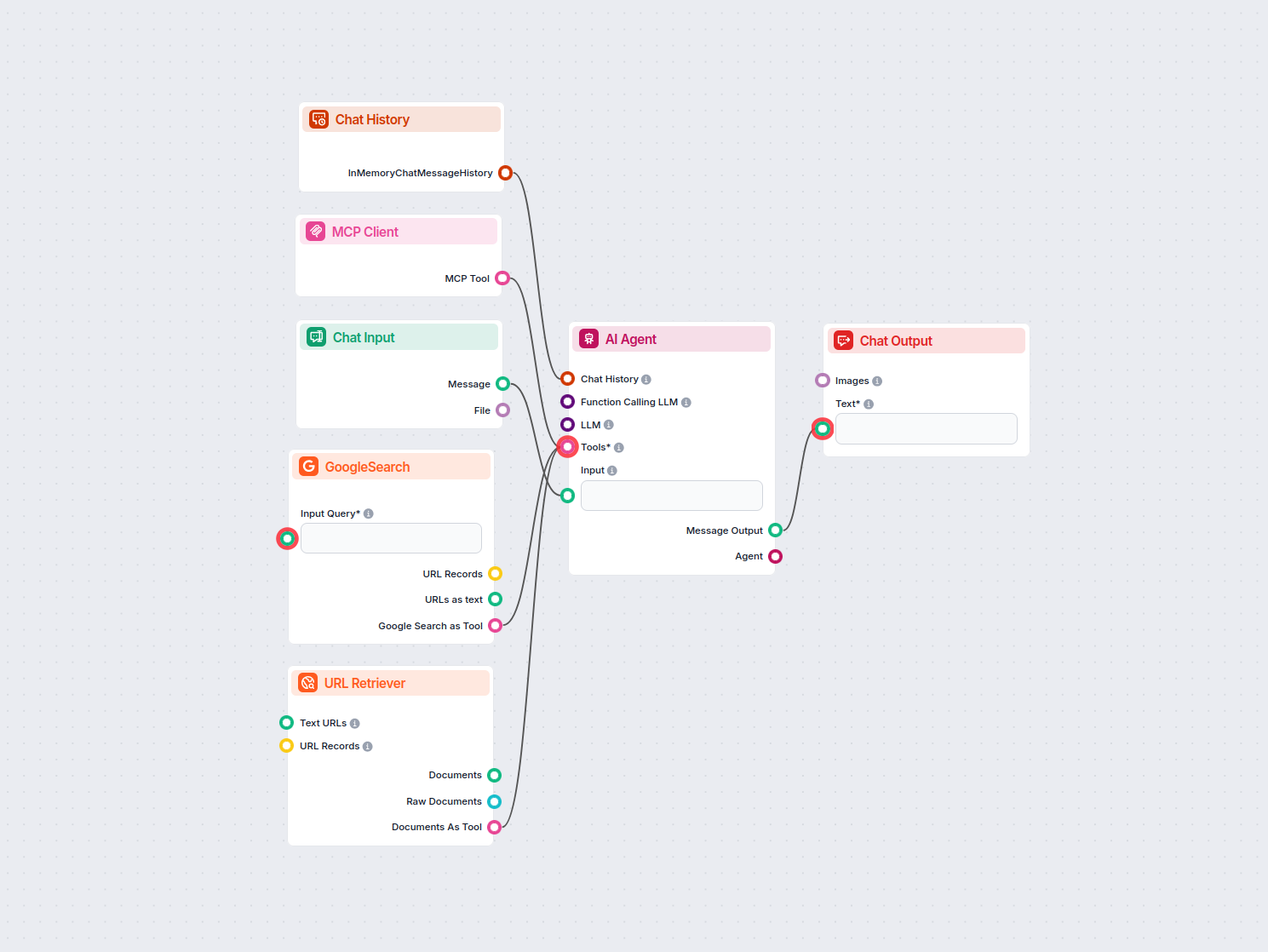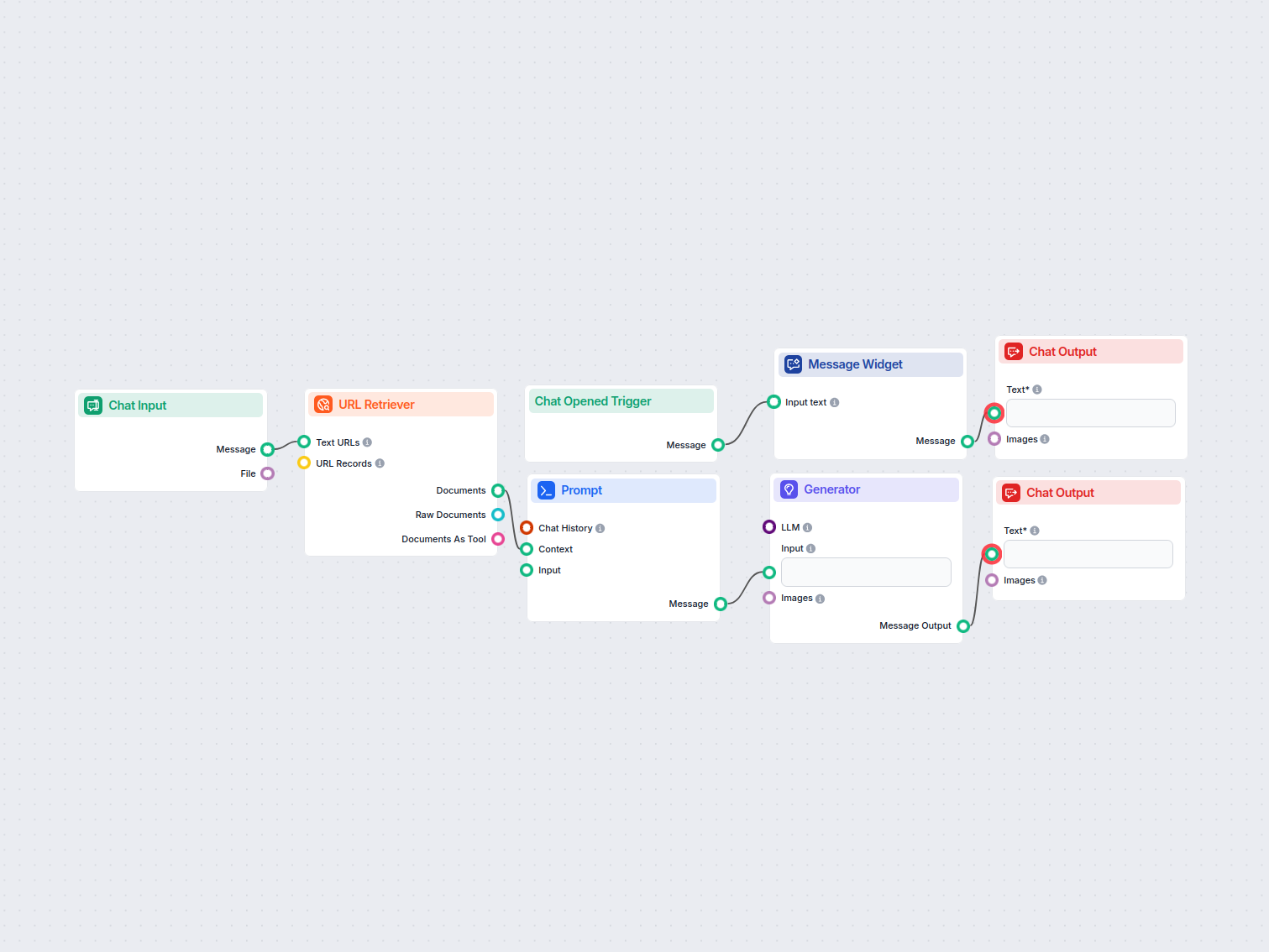
Imagine principală pentru blog de la URL
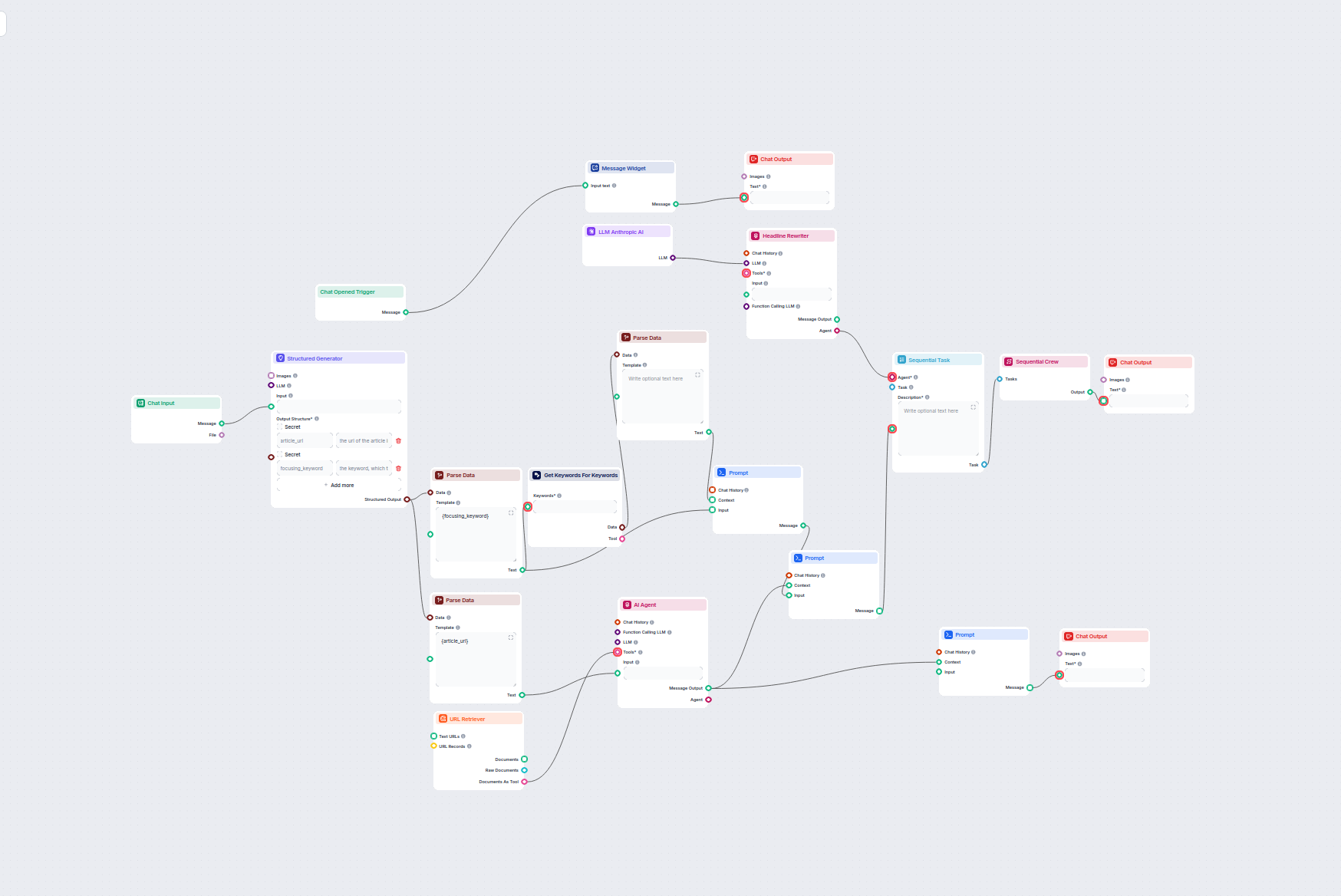
Generează automat o imagine atractivă pentru orice articol de blog, analizând conținutul acestuia. Doar furnizați URL-ul blogului, iar fluxul folosește AI pentr...
3 min citire
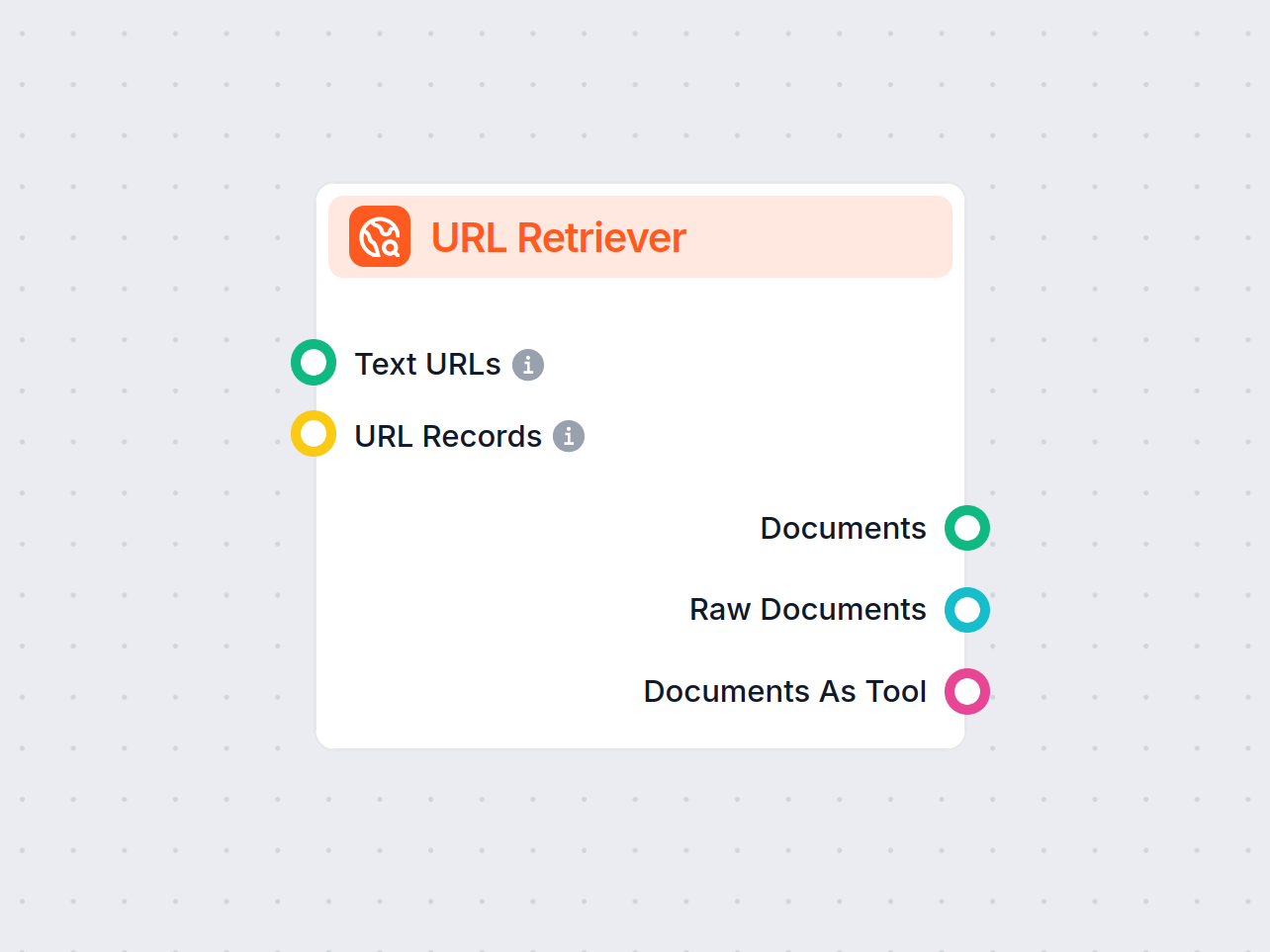
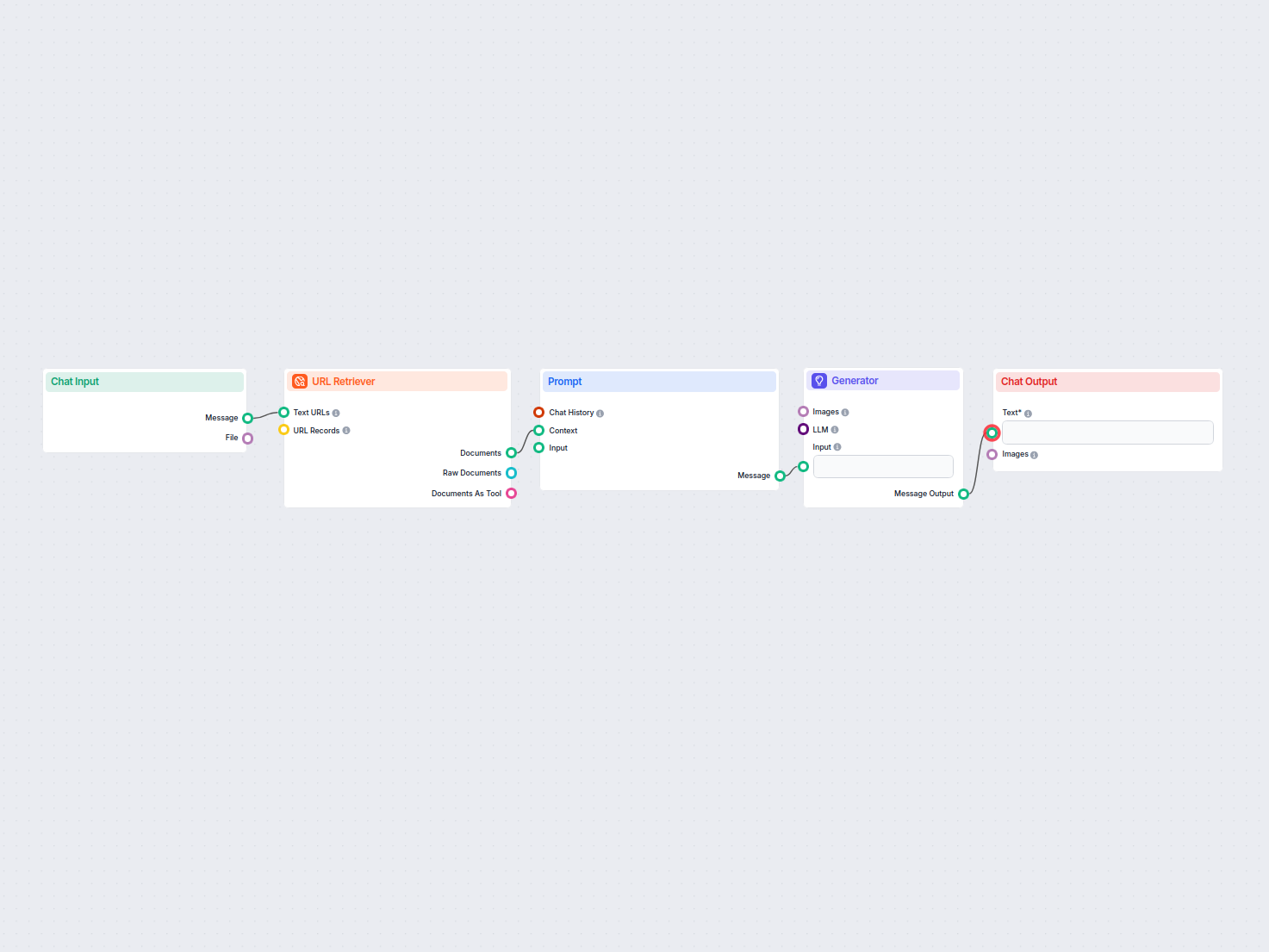
URL Retriever îți permite să preiei și să procesezi conținutul de pe link-uri web, suportând OCR, extragere de metadate și output flexibil pentru alimentarea fluxurilor AI.
Descrierea componentei
URL Retriever este o componentă de flux versatilă, proiectată să preia și să proceseze conținut web de la URL-urile specificate, returnând informațiile sub formă de documente structurate. Servește drept punte între conținutul online extern și fluxul tău de lucru AI, permițând integrarea, analizarea sau procesarea eficientă a informațiilor web.
Această componentă recuperează conținutul unuia sau mai multor URL-uri furnizate ca input. Poate extrage textul principal, metadatele și chiar să proceseze conținutul din imagini folosind Recunoaștere Optică a Caracterelor (OCR). Datele recuperate sunt apoi disponibile în diverse formate structurate, potrivite pentru sarcini AI precum sumarizare, răspuns la întrebări sau extragere de cunoștințe.
Poți furniza URL-uri componentei în două moduri:
URL-uri text:
MessageÎnregistrări URL:
UrlRecord| Parametru | Tip | Implicit | Descriere |
|---|---|---|---|
| Aplică OCR | Boolean | false | Dacă este activat, aplică OCR pentru a extrage text din imagini din document. |
| Cache TTL | Dropdown | 2 săptămâni | Durata de păstrare în cache a conținutului, cu opțiuni de la fără cache până la 1 an. |
| Din H1 dacă există | Boolean | true | Începe extragerea din tag-ul H1, dacă este prezent, concentrându-se pe conținutul principal. |
| Încarcă din pointer | Boolean | true | Încarcă conținutul pornind din secțiunea cea mai relevantă pe baza interogării tale. |
| Ascunde resursele | Boolean | false | Ascunde resursele recuperate pentru a nu fi afișate sau returnate în output. |
| Maxim tokeni | Integer | 3000 | Setează numărul maxim de tokeni pentru textul rezultat. |
| Sari peste ultimul header | Boolean | true | Sari peste ultimul titlu la extragere pentru un conținut mai concis. |
| Strategie | Dropdown | Include părți egale din fiecare document | Determină cum este combinat conținutul: concatenare completă sau părți egale din fiecare document. |
| Exportă conținut | Multi-select | Toate | Alege ce elemente HTML să fie exportate (H1-H6, Paragraf). |
| Include metadate | Multi-select | Produs | Specifică ce câmpuri de metadate să fie incluse (ex: Produs, Autor, Website etc.). |
| Verbos | Boolean | false | Activează output detaliat pentru depanare sau informare. |
| Nume unealtă | String | (gol) | Opțional, atribuie un nume personalizat uneltei pentru referință de către agent. |
| Descriere unealtă | Multiline | (gol) | Oferă o descriere care să ajute agenții să înțeleagă scopul uneltei. |
URL Retriever oferă output-urile sale în mai multe formate, permițând integrare flexibilă cu diverse procese AI:
| Nume Output | Tip | Descriere |
|---|---|---|
| Documente | Message | Conținutul procesat din URL-uri, gata de folosit în fluxuri de lucru bazate pe mesaje. |
| Documente brute | Document | Obiectele de document neprocesate pentru procesare avansată ulterioară. |
| Documente ca unealtă | Tool | Conținutul împachetat ca unealtă, permițând fluxuri de lucru cu agenți ce utilizează documente. |
| Funcționalitate | Descriere |
|---|---|
| Preia URL-uri | Recuperează și procesează conținutul web de la URL-urile furnizate. |
| Suport OCR | Extrage text din imagini în documente, dacă este activat. |
| Extragere de metadate | Include opțional metadate precum autor, produs sau tipuri schema.org. |
| Output personalizabil | Selectează ce elemente HTML sau metadate să fie exportate. |
| Cache | Durate de stocare în cache configurabile pentru eficiență. |
| Tipuri de output multiple | Suportă output ca mesaj, document brut și unealtă pentru flexibilitate. |
URL Retriever este o punte puternică și flexibilă între conținutul web și fluxurile tale AI, oferind control granular asupra extragerii și integrării conținutului.
Pentru a te ajuta să începi rapid, am pregătit mai multe șabloane flow exemplu care demonstrează cum să folosești componenta URL Retriever eficient. Aceste șabloane prezintă diferite cazuri de utilizare și cele mai bune practici, făcând mai ușor pentru tine să înțelegi și să implementezi componenta în propriile tale proiecte.
Generează automat o imagine atractivă pentru orice articol de blog, analizând conținutul acestuia. Doar furnizați URL-ul blogului, iar fluxul folosește AI pentr...
Acest flux de lucru bazat pe AI îmbogățește datele de lead-uri din Google Sheets, recuperând automat profiluri LinkedIn lipsă, titluri de job și industrii de pe...
Acest flux de lucru îmbogățește automat datele de contact din Google Sheets prin găsirea profilurilor LinkedIn, extragerea funcțiilor și industriilor, și actual...
Acest flux de lucru asistat de AI îmbunătățește descrierile produselor Shopify pe baza numelui produsului sau a URL-ului furnizat de utilizator. Folosește LLM-u...
Acest flux de lucru bazat pe AI găsește cele mai bune cuvinte cheie SEO pentru articolul tău de blog și rescrie automat titlurile pentru a viza acele cuvinte ch...
Optimizează automat titlurile și subtitlurile articolului tău pentru un anumit cuvânt cheie sau un grup de cuvinte cheie pentru a îmbunătăți performanța SEO. Ac...
Acest flux de lucru bazat pe AI simplifică procesul de adaptare a CV-ului unui utilizator la un anumit anunț de angajare. Prin analizarea atât a CV-ului origina...
Acest flux de lucru alimentat de AI automatizează programarea întâlnirilor prin Google Calendar. Utilizatorii interacționează cu un chatbot care găsește interva...
Acest flux de lucru bazat pe inteligență artificială cercetează conținutul existent al blogului unui site Wordpress, generează un articol nou optimizat SEO pe o...
Generează rapid rezumate concise ale oricărei pagini web, oferind pur și simplu un URL. Acest flux de lucru alimentat de AI preia conținutul de la linkul furniz...
Creează automat o meta descriere captivantă și optimizată SEO pentru orice pagină web, PDF, videoclip YouTube sau link de document, analizând conținutul și gene...
Transformă documentația tehnică de la o adresă URL într-un articol captivant, optimizat SEO pentru site-ul tău. Acest flux analizează conținutul competitorilor ...
Transformă automat conținutul oricărui URL furnizat într-o postare concisă și captivantă, potrivită pentru X (Twitter), ajutând marketerii și creatorii să își c...
Se afișează 61 până la 73 din 73 rezultate
URL Retriever preia și procesează conținutul de pe link-urile web specificate, făcând textul și metadatele din documente online disponibile pentru fluxul tău de lucru sau pentru agentul AI.
Da, prin activarea opțiunii OCR, componenta poate extrage text din documente bazate pe imagine sau PDF-uri scanate.
Returnează documente procesate ca mesaje text, obiecte de document brute sau ca instrument pentru fluxuri de lucru cu agenți, în funcție de configurare.
Poți seta cât timp este păstrat în cache conținutul recuperat, reducând descărcările repetate și accelerând fluxurile tale.
Da, poți specifica ce titluri, paragrafe sau câmpuri de metadate să fie incluse în output, permițând o extragere direcționată.
Absolut. URL Retriever este esențial pentru orice automatizare sau chatbot care trebuie să citească, proceseze sau să rezume conținut web live.
Propulsează-ți fluxurile de lucru integrând conținut web live. Extrage, procesează și utilizează date din URL-uri cu ușurință.
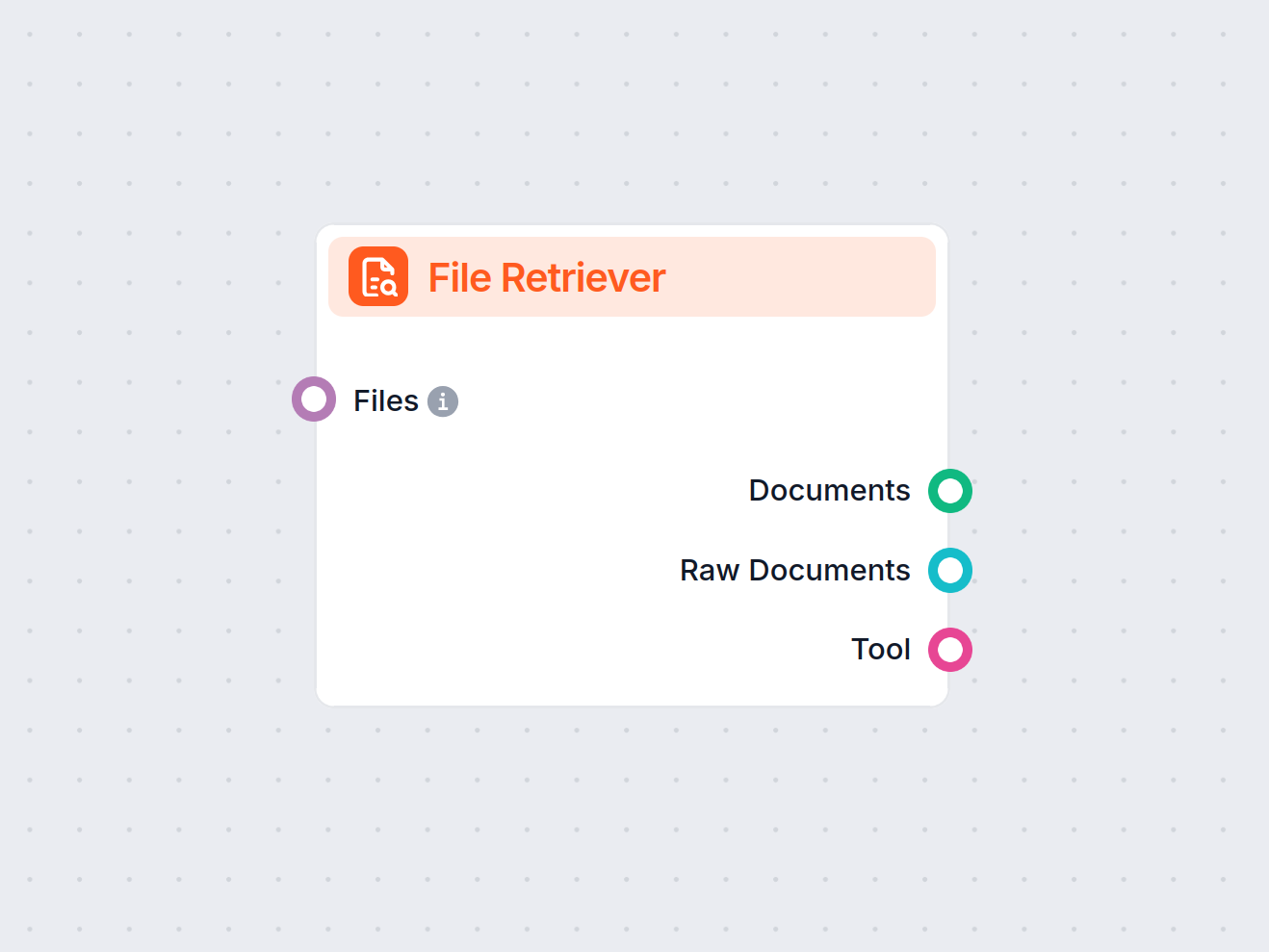
Componenta File Retriever din FlowHunt vă permite să aduceți fișiere în fluxul de lucru și să le convertiți în documente pentru procesare ulterioară. Suportă st...
Generează rapid rezumate concise ale oricărei pagini web, oferind pur și simplu un URL. Acest flux de lucru alimentat de AI preia conținutul de la linkul furniz...
Integrează-ți fluxurile de lucru cu Google Docs folosind componenta Google Docs Retriever—preia fără efort conținutul documentelor pentru a fi folosit în automa...