Insight Engine
Descoperă ce este un Insight Engine—o platformă avansată, bazată pe inteligență artificială, care îmbunătățește căutarea și analiza datelor prin înțelegerea con...
11 min citire
AI
Insight Engine
+5

Căutarea AI utilizează învățarea automată și embeddings vectoriale pentru a înțelege intenția și contextul căutărilor, oferind rezultate extrem de relevante dincolo de potrivirile exacte ale cuvintelor-cheie.
Căutarea AI folosește învățarea automată pentru a înțelege contextul și intenția interogărilor de căutare, transformându-le în vectori numerici pentru rezultate mai precise. Spre deosebire de căutarea tradițională după cuvinte-cheie, Căutarea AI interpretează relații semantice, făcându-se eficientă pentru tipuri diverse de date și limbi.
Căutarea AI, denumită adesea căutare semantică sau vectorială, este o metodologie de căutare care valorifică modelele de învățare automată pentru a înțelege intenția și sensul contextual al interogărilor de căutare. Spre deosebire de căutarea tradițională după cuvinte-cheie, căutarea AI transformă datele și interogările în reprezentări numerice cunoscute sub numele de vectori sau embeddings. Acest lucru permite motorului de căutare să înțeleagă relațiile semantice dintre diferite fragmente de date, oferind rezultate mai relevante și mai precise chiar și atunci când cuvintele-cheie exacte nu sunt prezente.
Căutarea AI reprezintă o evoluție semnificativă în tehnologiile de căutare. Motoarele de căutare tradiționale se bazează foarte mult pe potrivirea cuvintelor-cheie, unde prezența anumitor termeni atât în interogare, cât și în documente determină relevanța. Căutarea AI, însă, utilizează modele de învățare automată pentru a surprinde contextul și sensul real al interogărilor și datelor.
Prin conversia textului, imaginilor, audio și a altor date nestructurate în vectori de înaltă dimensiune, Căutarea AI poate măsura similitudinea dintre diferite conținuturi. Această abordare permite motorului de căutare să livreze rezultate relevante contextual, chiar dacă nu conțin exact cuvintele-cheie folosite în interogare.
Componente cheie:
La baza Căutării AI stă conceptul de embeddings vectoriale. Embeddings-urile vectoriale sunt reprezentări numerice ale datelor care surprind sensul semantic al textului, imaginilor sau altor tipuri de date. Aceste embeddings plasează fragmente de date similare aproape unul de altul într-un spațiu vectorial multidimensional.
Cum funcționează:
Exemplu:
Motoarele de căutare tradiționale pe bază de cuvinte-cheie operează prin potrivirea termenilor din interogare cu documente ce conțin acei termeni. Ele se bazează pe tehnici precum indici inversați și frecvența termenilor pentru a stabili relevanța.
Limitări ale căutării pe cuvinte-cheie:
Avantajele Căutării AI:
| Aspect | Căutare după cuvinte-cheie | Căutare AI (Semantică/Vectorială) |
|---|---|---|
| Potrivire | Potriviri exacte ale cuvintelor | Similaritate semantică |
| Conștientizare context | Limitată | Ridicată |
| Gestionare sinonime | Necesită liste manuale de sinonime | Automat prin embeddings |
| Greșeli de scriere | Eșuează fără căutare fuzzy | Mai tolerantă datorită contextului |
| Înțelegerea intenției | Minimală | Semnificativă |
Căutarea Semantică este o aplicație de bază a Căutării AI care se concentrează pe înțelegerea intenției utilizatorului și a sensului contextual al interogărilor.
Proces:
Tehnici cheie:
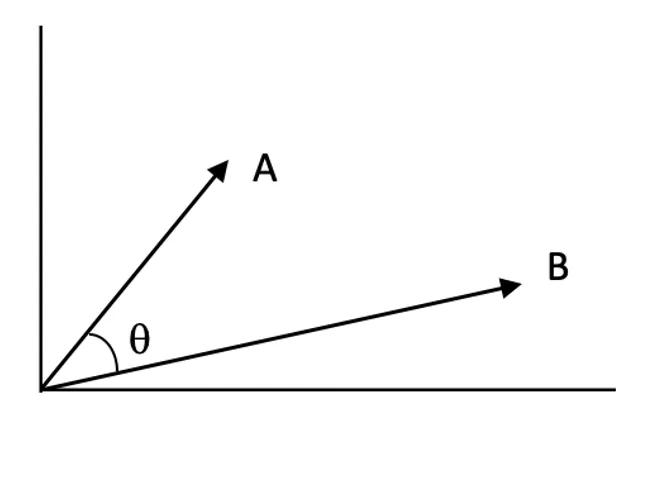
Scoruri de similitudine:
Scorurile de similitudine cuantifică cât de apropiate sunt două vectori în spațiul vectorial. Un scor mai mare indică o relevanță mai mare între interogare și un document.
Algoritmi Approximate Nearest Neighbor (ANN):
Găsirea vecinilor exacți în spații de înaltă dimensiune este costisitoare computațional. Algoritmii ANN oferă aproximări eficiente.
Căutarea AI deschide o gamă largă de aplicații în diverse industrii datorită capacității de a interpreta și înțelege datele dincolo de potrivirile simple de cuvinte-cheie.
Descriere: Căutarea Semantică îmbunătățește experiența utilizatorului interpretând intenția din spatele interogărilor și oferind rezultate relevante contextual.
Exemple:
Descriere: Prin înțelegerea preferințelor și comportamentului utilizatorului, Căutarea AI poate oferi conținut sau produse personalizate.
Exemple:
Descriere: Căutarea AI permite sistemelor să înțeleagă și să răspundă la interogări cu informații precise extrase din documente.
Exemple:
Descriere: Căutarea AI poate indexa și căuta în date nestructurate precum imagini, audio sau video prin conversia lor în embeddings.
Exemple:
Integrarea Căutării AI în automatizarea AI și chatboți îmbunătățește semnificativ capabilitățile acestora.
Beneficii:
Pași de implementare:
Exemplu de caz de utilizare:
Deși Căutarea AI oferă numeroase avantaje, există și provocări:
Strategii de atenuare:
Căutarea semantică și vectorială în AI au apărut ca alternative puternice la căutarea tradițională bazată pe cuvinte-cheie și căutarea fuzzy, îmbunătățind semnificativ relevanța și precizia rezultatelor prin înțelegerea contextului și a sensului interogărilor.
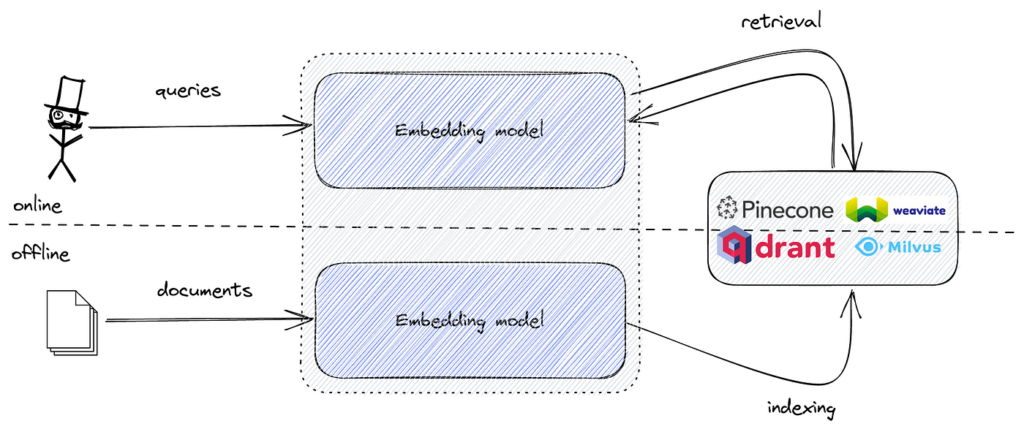
La implementarea căutării semantice, datele textuale sunt convertite în embeddings vectoriale ce surprind sensul semantic al textului. Aceste embeddings sunt reprezentări numerice de înaltă dimensiune. Pentru a căuta eficient printre aceste embeddings și a găsi cele mai apropiate față de embedding-ul interogării, avem nevoie de un instrument optimizat pentru căutarea similarității în spații de înaltă dimensiune.
FAISS oferă algoritmi și structuri de date necesare pentru a efectua această sarcină eficient. Combinând embeddings semantice cu FAISS, putem crea un motor de căutare semantică puternic, capabil să gestioneze seturi mari de date cu latență scăzută.
Implementarea căutării semantice cu FAISS în Python implică mai mulți pași:
Să detaliem fiecare pas:
Pregătește setul de date (ex: articole, tichete de suport, descrieri de produse).
Exemplu:
documents = [
"Cum să resetezi parola pe platforma noastră.",
"Depanarea problemelor de conectivitate la rețea.",
"Ghid pentru instalarea actualizărilor software.",
"Cele mai bune practici pentru backup și recuperare date.",
"Configurarea autentificării cu doi factori pentru securitate sporită."
]
Curăță și formatează datele textuale după necesitate.
Convertește datele textuale în embeddings vectoriale folosind modele Transformer pre-antrenate din librării precum Hugging Face (transformers sau sentence-transformers).
Exemplu:
from sentence_transformers import SentenceTransformer
import numpy as np
# Încarcă un model pre-antrenat
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generează embeddings pentru toate documentele
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 așa cum cere FAISS.Creează un index FAISS pentru a stoca embeddings-urile și a permite căutarea eficientă pe bază de similaritate.
Exemplu:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 realizează căutare brută folosind distanța L2 (euclidiană).Convertește interogarea utilizatorului într-un embedding și găsește cei mai apropiați vecini.
Exemplu:
query = "Cum îmi schimb parola de cont?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Folosește indicii pentru a afișa cele mai relevante documente.
Exemplu:
print("Cele mai relevante rezultate pentru interogarea ta:")
for idx in indices[0]:
print(documents[idx])
Rezultat așteptat:
Cele mai relevante rezultate pentru interogarea ta:
Cum să resetezi parola pe platforma noastră.
Configurarea autentificării cu doi factori pentru securitate sporită.
Cele mai bune practici pentru backup și recuperare date.
FAISS oferă mai multe tipuri de indexuri:
Folosirea unui index cu fișier inversat (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalizare și căutare cu produs intern:
Folosirea similarității cosinus poate fi mai eficientă pentru date textuale
Căutarea AI este o metodologie modernă de căutare care utilizează învățarea automată și embeddings vectoriale pentru a înțelege intenția și sensul contextual al interogărilor, oferind rezultate mai precise și relevante decât căutarea tradițională bazată pe cuvinte-cheie.
Spre deosebire de căutarea pe cuvinte-cheie, care se bazează pe potriviri exacte, Căutarea AI interpretează relațiile semantice și intenția din spatele interogărilor, fiind eficientă pentru limbaj natural și inputuri ambigue.
Embeddings vectoriale sunt reprezentări numerice ale textului, imaginilor sau altor tipuri de date care surprind sensul semantic, permițând motorului de căutare să măsoare similitudinea și contextul între diferite bucăți de date.
Căutarea AI alimentează căutarea semantică în e-commerce, recomandări personalizate în streaming, sisteme de întrebări-răspunsuri în suportul clienților, navigarea datelor nestructurate și regăsirea documentelor în cercetare și companii.
Instrumente populare includ FAISS pentru căutarea eficientă a similarității vectoriale și baze de date vectoriale precum Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch și Pgvector pentru stocare și regăsire scalabilă a embeddings-urilor.
Prin integrarea Căutării AI, chatboții și sistemele de automatizare pot înțelege mai profund interogările utilizatorilor, regăsi răspunsuri contextual relevante și oferi răspunsuri dinamice, personalizate.
Provocările includ cerințe computaționale ridicate, complexitatea interpretării modelelor, necesitatea datelor de calitate și asigurarea confidențialității și securității informațiilor sensibile.
FAISS este o librărie open-source pentru căutare eficientă a similarității pe embeddings vectoriale de dimensiuni mari, fiind folosită pe scară largă pentru a construi motoare de căutare semantică care pot gestiona seturi mari de date.
Descoperă cum căutarea semantică alimentată de AI poate transforma regăsirea informațiilor, chatboții și fluxurile de lucru de automatizare.
Descoperă ce este un Insight Engine—o platformă avansată, bazată pe inteligență artificială, care îmbunătățește căutarea și analiza datelor prin înțelegerea con...
Perplexity AI este un motor de căutare avansat, alimentat de inteligență artificială, și un instrument conversațional care valorifică NLP și învățarea automată ...
Căutarea făcetară este o tehnică avansată care permite utilizatorilor să rafineze și să navigheze volume mari de date aplicând mai multe filtre bazate pe catego...