Învățarea Automată
Învățarea automată (ML) este o subramură a inteligenței artificiale (IA) care permite mașinilor să învețe din date, să identifice tipare, să facă predicții și s...
3 min citire
Machine Learning
AI
+4
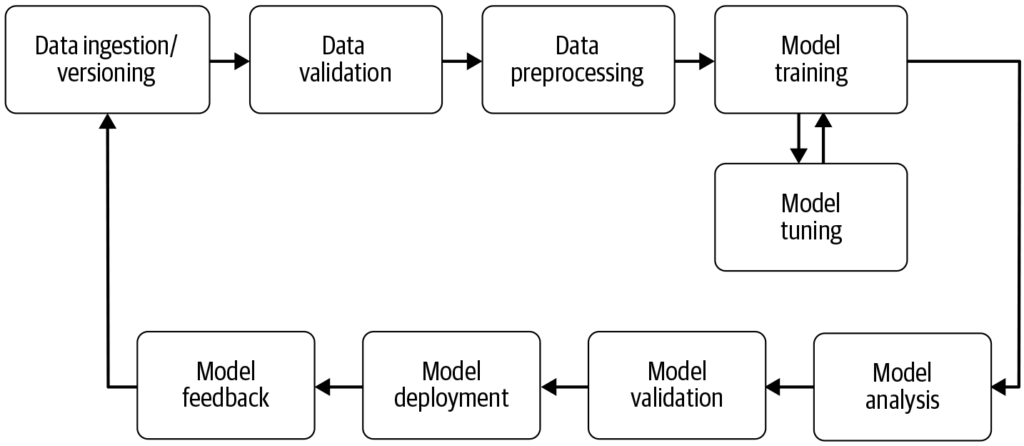
Un flux de lucru învățare automată automatizează pașii de la colectarea datelor la implementarea modelului, sporind eficiența, reproductibilitatea și scalabilitatea în proiectele de învățare automată.
Un flux de lucru învățare automată este un proces automatizat care eficientizează dezvoltarea, antrenarea, evaluarea și implementarea modelelor. Acesta sporește eficiența, reproductibilitatea și scalabilitatea, facilitând activitățile de la colectarea datelor la implementarea și întreținerea modelului.
Un flux de lucru învățare automată este un proces automatizat care cuprinde o serie de pași implicați în dezvoltarea, antrenarea, evaluarea și implementarea modelelor de învățare automată. Este conceput pentru a eficientiza și standardiza procesele necesare pentru a transforma date brute în perspective acționabile prin algoritmi de învățare automată. Abordarea pe bază de flux permite gestionarea eficientă a datelor, antrenarea și implementarea modelelor, facilitând managementul și extinderea operațiunilor de învățare automată.
Sursa: Building Machine Learning
Colectarea datelor: Etapa inițială în care datele sunt adunate din diverse surse precum baze de date, API-uri sau fișiere. Colectarea datelor este o practică metodică ce urmărește obținerea unor informații relevante pentru a construi un set de date coerent pentru un scop de afaceri specific. Aceste date brute sunt esențiale pentru construirea modelelor de învățare automată, dar necesită adesea preprocesare pentru a deveni utile. După cum subliniază AltexSoft, colectarea datelor implică acumularea sistematică de informații pentru a susține analizele și luarea deciziilor. Acest proces este crucial deoarece pune bazele tuturor pașilor următori ai fluxului și este adesea continuu pentru a asigura antrenarea modelelor cu date relevante și actualizate.
Preprocesarea datelor: Datele brute sunt curățate și transformate într-un format adecvat pentru antrenarea modelului. Pașii obișnuiți de preprocesare includ gestionarea valorilor lipsă, codificarea variabilelor categorice, scalarea caracteristicilor numerice și împărțirea datelor în seturi de antrenare și testare. Această etapă asigură că datele au formatul corect și sunt lipsite de inconsistențe care ar putea afecta performanța modelului.
Ingineria caracteristicilor: Crearea de noi caracteristici sau selectarea celor relevante din date pentru a îmbunătăți puterea predictivă a modelului. Acest pas poate necesita cunoștințe de domeniu și creativitate. Ingineria caracteristicilor este un proces creativ care transformă datele brute în caracteristici semnificative ce reflectă mai bine problema și mărește performanța modelelor de învățare automată.
Selecția modelului: Alegerea algoritmului (sau algoritmilor) de învățare automată potrivit(ți), în funcție de tipul problemei (ex: clasificare, regresie), caracteristicile datelor și cerințele de performanță. În această etapă se pot lua în calcul și ajustarea hiperparametrilor. Alegerea modelului potrivit este crucială, deoarece influențează acuratețea și eficiența predicțiilor.
Antrenarea modelului: Modelul (sau modelele) selectat(e) sunt antrenate folosind setul de date de antrenament. Acest lucru presupune învățarea tiparelor și relațiilor din date. Se pot folosi și modele pre-antrenate, în locul antrenării unui model de la zero. Antrenarea este un pas esențial în care modelul învață din date pentru a face predicții informate.
Evaluarea modelului: După antrenare, performanța modelului este evaluată folosind un set de date de test sau prin validare încrucișată. Metricile de evaluare depind de problema specifică, dar pot include acuratețe, precizie, recall, scor F1, eroare medie pătratică etc. Acest pas este crucial pentru a asigura performanța modelului pe date nevăzute.
Implementarea modelului: Odată ce un model satisfăcător este dezvoltat și evaluat, acesta poate fi implementat într-un mediu de producție pentru a face predicții pe date noi. Implementarea poate implica crearea de API-uri și integrarea cu alte sisteme. Este ultima etapă a fluxului, unde modelul devine accesibil pentru utilizare reală.
Monitorizare și întreținere: După implementare, este esențială monitorizarea continuă a performanței modelului și reantrenarea acestuia, dacă este necesar, pentru a se adapta la schimbările din date, menținând astfel acuratețea și fiabilitatea în mediul real. Acest proces continuu asigură relevanța și acuratețea modelului în timp.
Procesarea limbajului natural (NLP): Sarcinile NLP implică adesea mai mulți pași repetabili, precum ingestia datelor, curățarea textului, tokenizarea și analiza sentimentului. Fluxurile permit modularizarea acestor pași, facilitând modificările și actualizările fără a afecta alte componente.
Mentenanță predictivă: În industrii precum producția, fluxurile pot fi folosite pentru a prezice defectarea echipamentelor prin analizarea datelor de la senzori, permițând mentenanță proactivă și reducând timpii de nefuncționare.
Finanțe: Fluxurile pot automatiza procesarea datelor financiare pentru a detecta fraude, evalua riscuri de credit sau a prezice prețul acțiunilor, îmbunătățind procesul decizional.
Sănătate: În domeniul medical, fluxurile pot prelucra imagini medicale sau fișe ale pacienților pentru a ajuta la diagnostic sau a prezice evoluția pacienților, îmbunătățind strategiile de tratament.
Fluxurile de lucru învățare automată sunt esențiale pentru AI și automatizare deoarece oferă un cadru structurat pentru automatizarea sarcinilor de învățare automată. În domeniul automatizării AI, fluxurile asigură antrenarea și implementarea eficientă a modelelor, permițând sistemelor AI precum [chatbot-urile să învețe și să se adapteze la date noi fără intervenție manuală. Această automatizare este crucială pentru scalarea aplicațiilor AI și pentru a asigura performanță constantă și fiabilă în diverse domenii. Utilizând fluxuri, organizațiile își pot îmbunătăți capabilitățile AI și pot menține modelele de învățare automată relevante și eficiente într-un mediu în schimbare.
Cercetare despre fluxurile de lucru învățare automată
“Deep Pipeline Embeddings for AutoML” de Sebastian Pineda Arango și Josif Grabocka (2023) abordează provocările optimizării fluxurilor de lucru învățare automată în AutoML. Lucrarea introduce o arhitectură neuronală nouă, concepută pentru a surprinde interacțiuni profunde între componentele fluxului. Autorii propun încorporarea fluxurilor în reprezentări latente printr-un mecanism unic de encoder per componentă. Aceste încorporări sunt utilizate într-un cadru de Optimizare Bayesiana pentru a căuta fluxuri optime. Lucrarea evidențiază utilizarea meta-învățării pentru ajustarea parametrilor rețelei de încorporare a fluxului, demonstrând rezultate de ultimă generație în optimizarea fluxurilor pe mai multe seturi de date. Citește mai mult.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” de Tien-Dung Nguyen și colab. (2020) abordează evaluarea consumatoare de timp a fluxurilor de lucru în procesele AutoML. Studiul critică metodele tradiționale, precum optimizările bayesiene și genetice, pentru ineficiența lor. Pentru a contracara acest lucru, autorii prezintă AVATAR, un model surrogate care evaluează eficient validitatea fluxurilor fără execuție. Această abordare accelerează semnificativ compoziția și optimizarea fluxurilor complexe filtrând din timp cele invalide. Citește mai mult.
“Data Pricing in Machine Learning Pipelines” de Zicun Cong și colab. (2021) explorează rolul crucial al datelor în fluxurile de învățare automată și necesitatea stabilirii unui preț pentru date pentru a facilita colaborarea între mai mulți actori. Lucrarea trece în revistă cele mai noi evoluții privind stabilirea prețului datelor în contextul fluxurilor de învățare automată, concentrându-se pe importanța acestora în diverse etape ale fluxului. Oferă perspective despre strategii de prețuire pentru colectarea datelor de antrenament, antrenarea colaborativă a modelelor și furnizarea serviciilor de învățare automată, evidențiind formarea unui ecosistem dinamic. Citește mai mult.
Un flux de lucru învățare automată este o succesiune automată de pași—de la colectarea și preprocesarea datelor la antrenarea, evaluarea și implementarea modelului—care eficientizează și standardizează procesul de construire și întreținere a modelelor de învățare automată.
Componentele cheie includ colectarea datelor, preprocesarea datelor, ingineria caracteristicilor, selecția modelului, antrenarea modelului, evaluarea modelului, implementarea modelului și monitorizarea și întreținerea ulterioară.
Fluxurile de lucru învățare automată oferă modularizare, eficiență, reproductibilitate, scalabilitate, colaborare îmbunătățită și implementare mai ușoară a modelelor în mediile de producție.
Cazuri de utilizare includ procesarea limbajului natural (NLP), mentenanță predictivă în producție, evaluarea riscului financiar și detectarea fraudelor, precum și diagnostic medical.
Provocările includ asigurarea calității datelor, gestionarea complexității fluxului, integrarea cu sistemele existente și controlul costurilor legate de resursele computaționale și infrastructură.
Programați o demonstrație pentru a descoperi cum FlowHunt vă poate ajuta să automatizați și să scalați fluxurile de lucru învățare automată cu ușurință.
Învățarea automată (ML) este o subramură a inteligenței artificiale (IA) care permite mașinilor să învețe din date, să identifice tipare, să facă predicții și s...
MLflow este o platformă open-source concepută pentru a simplifica și gestiona ciclul de viață al învățării automate (ML). Oferă instrumente pentru urmărirea exp...
Acest flux automatizează asistența clienți pentru compania dvs. prin integrarea conversațiilor LiveAgent, extragerea datelor relevante din conversații, generare...