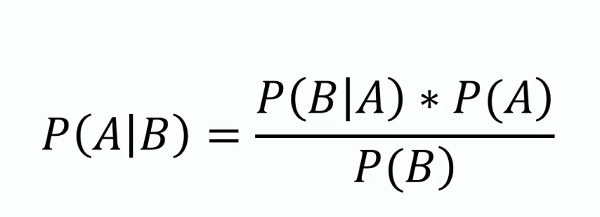
Rețele Bayesiene
O Rețea Bayesiană (BN) este un model grafic probabilistic care reprezintă variabilele și dependențele lor condiționale printr-un Graf Orientat Aaciclic (DAG). R...
3 min citire
Bayesian Networks
AI
+3
Naive Bayes este o familie simplă, dar puternică, de algoritmi de clasificare care utilizează Teorema lui Bayes, folosită frecvent pentru sarcini scalabile precum filtrarea spamului și clasificarea textelor.
Naive Bayes este o familie de algoritmi de clasificare simpli și eficienți, bazată pe Teorema lui Bayes, care presupune independența condiționată a atributelor. Este utilizat pe scară largă pentru detectarea spamului, clasificarea textelor și multe altele datorită simplității și scalabilității sale.
Naive Bayes este o familie de algoritmi de clasificare bazată pe Teorema lui Bayes, care aplică principiul probabilității condiționate. Termenul „naiv” se referă la presupunerea simplificatoare că toate atributele dintr-un set de date sunt condiționat independente între ele, având în vedere eticheta clasei. Chiar dacă această presupunere este adesea încălcată în datele reale, clasificatoarele Naive Bayes sunt recunoscute pentru simplitatea și eficiența lor în diverse aplicații, precum clasificarea textelor și filtrarea spamului.
Teorema lui Bayes
Această teoremă formează baza Naive Bayes, oferind o metodă de actualizare a estimării probabilității unei ipoteze pe măsură ce devin disponibile mai multe dovezi sau informații. Din punct de vedere matematic, se exprimă astfel:
unde ( P(A|B) ) este probabilitatea posterioară, ( P(B|A) ) este verosimilitatea, ( P(A) ) este probabilitatea anterioară, iar ( P(B) ) este evidența.
Independența condiționată
Presupunerea naivă că fiecare atribut este independent de oricare alt atribut, având în vedere eticheta clasei. Această presupunere simplifică calculele și permite algoritmului să fie scalabil pentru seturi mari de date.
Probabilitatea posterioară
Probabilitatea ca eticheta clasei să fie adevărată având în vedere valorile atributelor, calculată folosind Teorema lui Bayes. Aceasta este componenta centrală în realizarea predicțiilor cu Naive Bayes.
Tipuri de clasificatoare Naive Bayes
Clasificatoarele Naive Bayes funcționează prin calcularea probabilității posterioare pentru fiecare clasă, având în vedere un set de atribute, și selectarea clasei cu cea mai mare probabilitate posterioară. Procesul implică următorii pași:
Clasificatoarele Naive Bayes sunt deosebit de eficiente în următoarele aplicații:
Să luăm ca exemplu o aplicație de filtrare a spamului folosind Naive Bayes. Datele de antrenament constau în emailuri etichetate ca „spam” sau „non-spam”. Fiecare email este reprezentat de un set de atribute, precum prezența anumitor cuvinte. În timpul antrenării, algoritmul calculează probabilitatea fiecărui cuvânt având în vedere eticheta clasei. Pentru un email nou, algoritmul calculează probabilitatea posterioară pentru „spam” și „non-spam” și atribuie eticheta cu probabilitatea mai mare.
Clasificatoarele Naive Bayes pot fi integrate în sisteme AI și chatboți pentru a îmbunătăți procesarea limbajului natural și interacțiunea om-calculator. De exemplu, pot fi folosite pentru a detecta intenția interogărilor utilizatorilor, a clasifica texte în categorii predefinite sau a filtra conținutul inadecvat. Această funcționalitate îmbunătățește calitatea și relevanța interacțiunii cu soluțiile AI. În plus, eficiența algoritmului îl face potrivit pentru aplicații în timp real, un aspect important pentru automatizări AI și sisteme de tip chatbot.
Naive Bayes este o familie de algoritmi probabilistici simpli, dar puternici, bazată pe aplicarea teoremei lui Bayes cu presupuneri puternice de independență între atribute. Este utilizat pe scară largă pentru sarcini de clasificare datorită simplității și eficienței sale. Mai jos sunt câteva lucrări științifice care discută diverse aplicații și îmbunătățiri ale clasificatorului Naive Bayes:
Îmbunătățirea filtrării spamului prin combinarea Naive Bayes cu căutări k-nearest simple
Autor: Daniel Etzold
Publicat: 30 noiembrie 2003
Această lucrare explorează utilizarea Naive Bayes pentru clasificarea emailurilor, evidențiind ușurința de implementare și eficiența sa. Studiul prezintă rezultate empirice care arată cum combinarea Naive Bayes cu căutări k-nearest neighbor poate îmbunătăți acuratețea filtrării spamului. Combinația a oferit îmbunătățiri ușoare pentru un număr mare de atribute și îmbunătățiri semnificative pentru un număr redus de atribute. Citește lucrarea.
Naive Bayes ponderat local
Autori: Eibe Frank, Mark Hall, Bernhard Pfahringer
Publicat: 19 octombrie 2012
Această lucrare abordează principala slăbiciune a Naive Bayes, și anume presupunerea de independență a atributelor. Introduce o versiune ponderată local a Naive Bayes care învață modele locale în momentul predicției, relaxând astfel presupunerea de independență. Rezultatele experimentale arată că această abordare rareori degradează acuratețea și adesea o îmbunătățește semnificativ. Metoda este apreciată pentru simplitatea conceptuală și computațională în comparație cu alte tehnici. Citește lucrarea.
Detectarea blocării roverelor planetare folosind Naive Bayes
Autor: Dicong Qiu
Publicat: 31 ianuarie 2018
În acest studiu este discutată aplicarea clasificatoarelor Naive Bayes pentru detectarea blocării roverelor planetare. Se definesc criteriile de blocare a roverului și se demonstrează utilizarea Naive Bayes pentru detectarea acestor scenarii. Lucrarea detaliază experimente realizate cu rovere AutoKrawler, oferind perspective asupra eficienței Naive Bayes pentru proceduri autonome de salvare. Citește lucrarea.
Naive Bayes este o familie de algoritmi de clasificare bazată pe Teorema lui Bayes, care presupune că toate atributele sunt condiționat independente, având în vedere eticheta clasei. Este folosit pe scară largă pentru clasificarea textelor, filtrarea spamului și analiza sentimentului.
Principalele tipuri sunt Gaussian Naive Bayes (pentru atribute continue), Multinomial Naive Bayes (pentru atribute discrete precum numărarea cuvintelor) și Bernoulli Naive Bayes (pentru atribute binare/booleene).
Naive Bayes este simplu de implementat, eficient din punct de vedere computațional, scalabil la seturi mari de date și gestionează bine datele de înaltă dimensiune.
Principala sa limitare este presupunerea de independență a atributelor, care adesea nu este adevărată pentru datele reale. De asemenea, poate atribui probabilitate zero pentru atribute nevăzute, ceea ce poate fi atenuat cu tehnici precum netezirea Laplace.
Naive Bayes este folosit în sisteme AI și chatboți pentru detectarea intenției, clasificarea textelor, filtrarea spamului și analiza sentimentului, îmbunătățind capacitățile de procesare a limbajului natural și permițând luarea deciziilor în timp real.
Chatboți inteligenți și instrumente AI sub un singur acoperiș. Conectează blocuri intuitive pentru a-ți transforma ideile în fluxuri automate.
O Rețea Bayesiană (BN) este un model grafic probabilistic care reprezintă variabilele și dependențele lor condiționale printr-un Graf Orientat Aaciclic (DAG). R...
Un clasificator AI este un algoritm de învățare automată care atribuie etichete de clasă datelor de intrare, categorisind informația în clase predefinite pe baz...
Clasificarea textului, cunoscută și ca categorizarea sau etichetarea textului, este o sarcină centrală NLP care atribuie categorii predefinite documentelor text...