Chatbot AI pentru Serviciul Clienți
Un chatbot AI pentru serviciul clienți care folosește sursele interne de cunoștințe pentru a oferi răspunsuri instantanee, precise și utile la întrebările clien...
3 min citire
Un flux de preluare permite chatboților să acceseze și să proceseze cunoștințe externe relevante pentru răspunsuri precise, în timp real și contextuale utilizând RAG, embedding-uri și baze de date vectoriale.
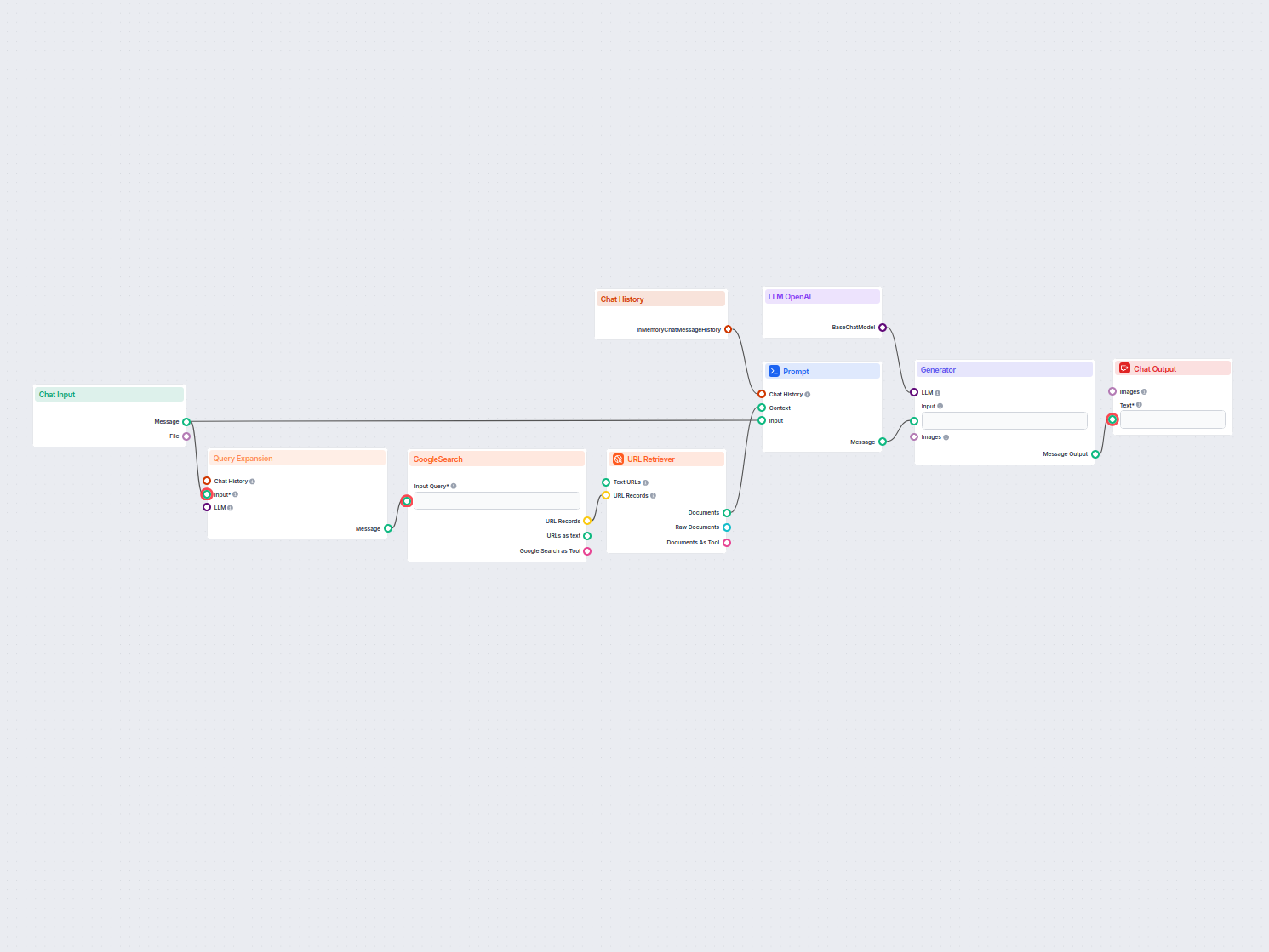
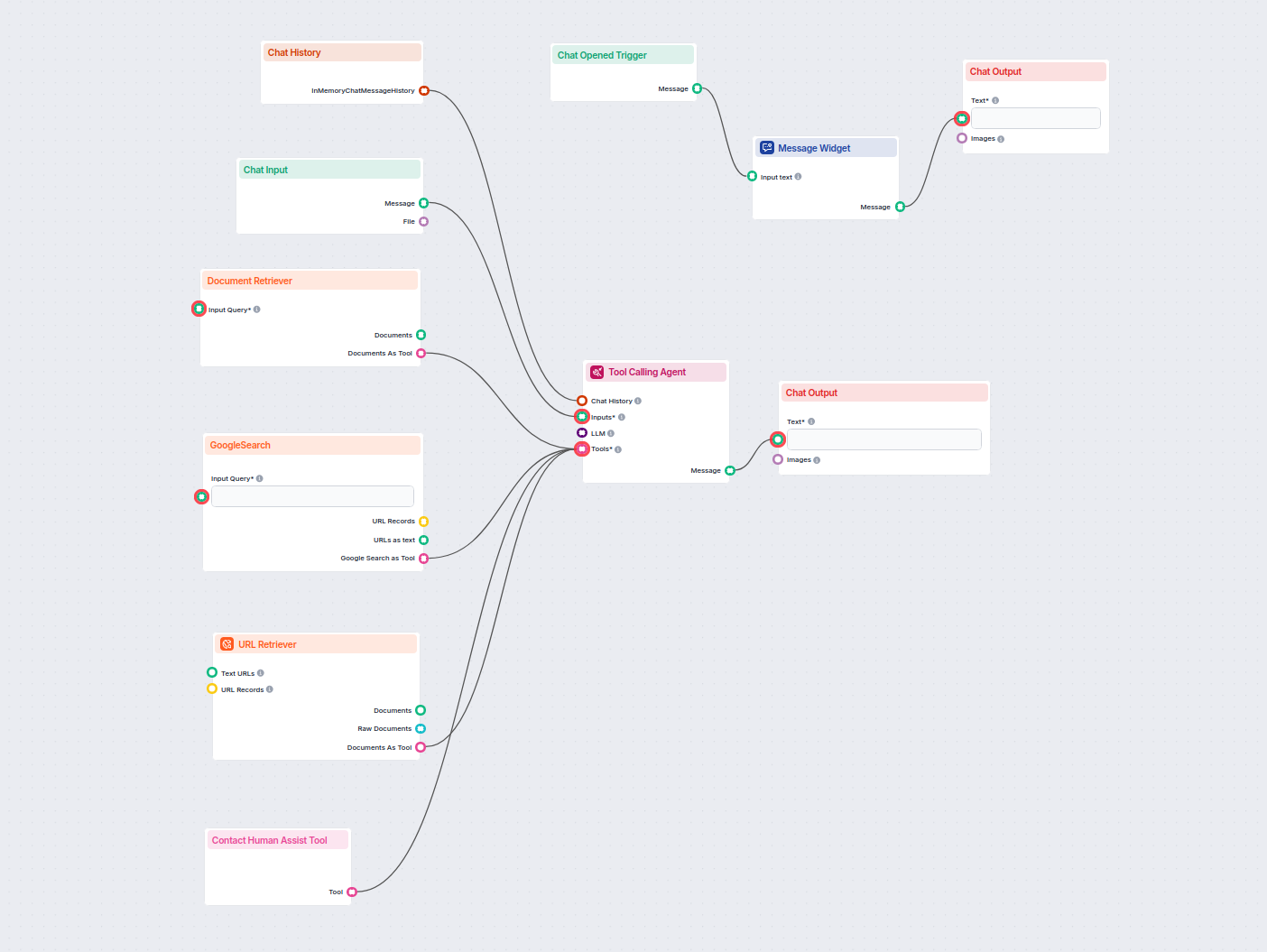
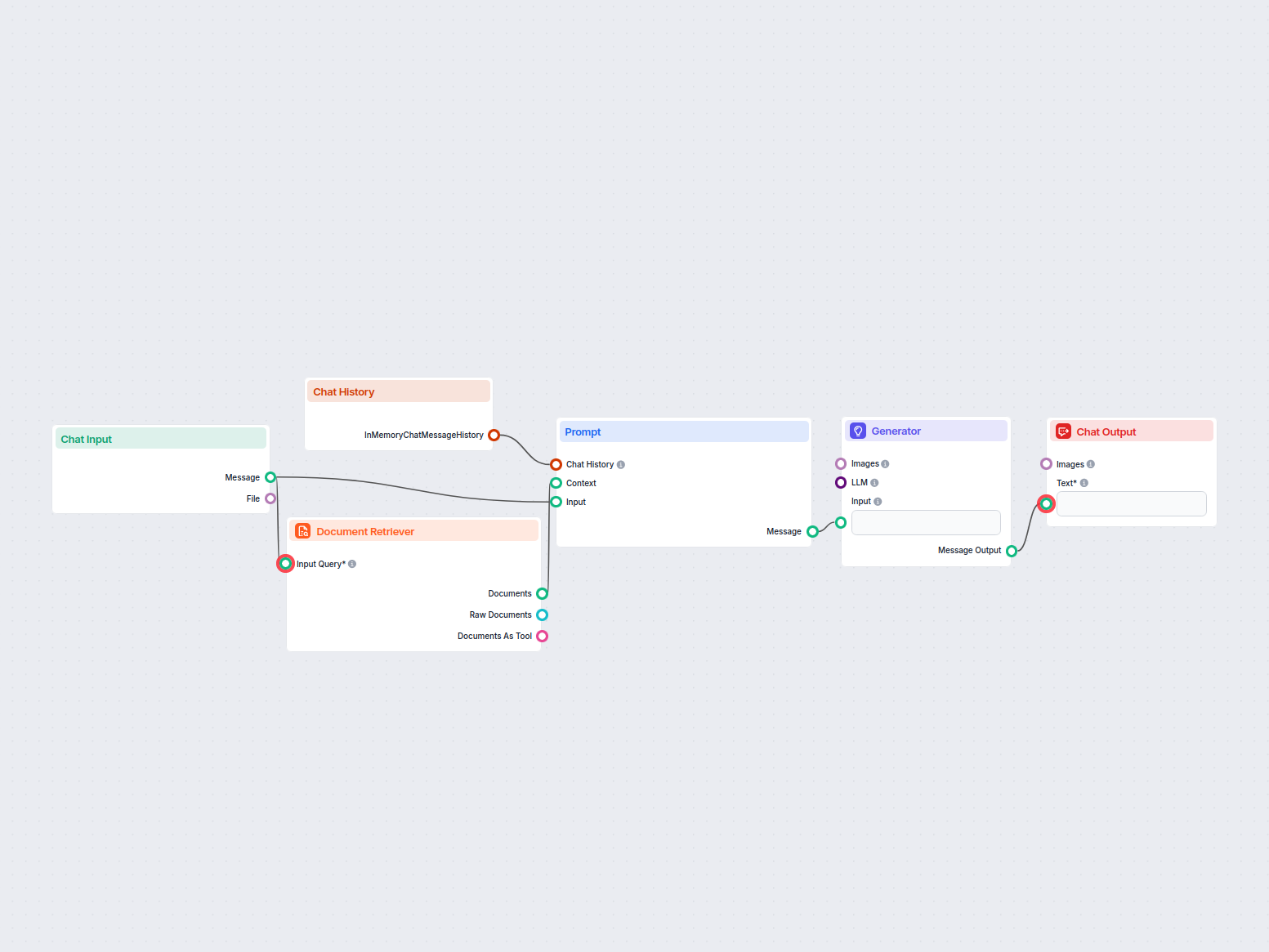
Un flux de preluare pentru chatboți se referă la arhitectura tehnică și procesul care permit chatboților să acceseze, proceseze și să recupereze informații relevante ca răspuns la întrebările utilizatorilor. Spre deosebire de sistemele simple de tip întrebare-răspuns care se bazează doar pe modele lingvistice pre-antrenate, fluxurile de preluare integrează baze de cunoștințe sau surse de date externe. Astfel, chatbotul poate oferi răspunsuri precise, relevante contextual și actualizate, chiar și atunci când datele respective nu sunt parte din modelul lingvistic în sine.
Fluxul de preluare conține de obicei mai multe componente, inclusiv ingestia datelor, crearea embedding-urilor, stocarea vectorială, preluarea contextului și generarea răspunsului. Implementarea sa folosește adesea Generarea Augmentată prin Preluare (RAG), care combină punctele forte ale sistemelor de preluare a datelor și ale modelelor lingvistice mari (LLM) pentru generarea răspunsurilor.
Un flux de preluare este utilizat pentru a îmbunătăți capabilitățile unui chatbot, permițându-i să:
Ingestia documentelor
Colectarea și preprocesarea datelor brute, ce pot include PDF-uri, fișiere text, baze de date sau API-uri. Instrumente precum LangChain sau LlamaIndex sunt adesea folosite pentru ingestia eficientă a datelor.
Exemplu: Încărcarea FAQ-urilor de suport clienți sau a specificațiilor produselor în sistem.
Preprocesarea documentelor
Documentele lungi sunt împărțite în fragmente mai mici, cu sens semantic. Acest lucru este esențial pentru a putea introduce textul în modele de embedding cu limite de tokeni (ex: 512 tokeni).
Exemplu de fragment de cod:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Generarea embedding-urilor
Datele textuale sunt convertite în reprezentări vectoriale de înaltă dimensiune folosind modele de embedding. Aceste embedding-uri codifică numeric sensul semantic al datelor.
Exemplu de model de embedding: OpenAI text-embedding-ada-002 sau Hugging Face e5-large-v2.
Stocarea vectorială
Embedding-urile sunt stocate în baze de date vectoriale optimizate pentru căutări pe bază de similitudine. Instrumente ca Milvus, Chroma sau PGVector sunt frecvent utilizate.
Exemplu: Stocarea descrierilor de produse și a embedding-urilor pentru recuperare eficientă.
Procesarea interogărilor
Când se primește o întrebare de la utilizator, aceasta este transformată într-un vector de interogare folosind același model de embedding. Acest lucru permite potrivirea semantică cu embedding-urile stocate.
Exemplu de fragment de cod:
query_vector = embedding_model.encode("Care sunt specificațiile produsului X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Preluarea datelor
Sistemul recuperează cele mai relevante fragmente de date pe baza scorurilor de similitudine (ex: similitudine cosinus). Sistemele de preluare multimodale pot combina baze de date SQL, grafuri de cunoștințe și căutări vectoriale pentru rezultate mai robuste.
Generarea răspunsului
Datele recuperate sunt combinate cu întrebarea utilizatorului și transmise unui model lingvistic mare (LLM) pentru a genera un răspuns final, în limbaj natural. Această etapă este adesea numită generare augmentată.
Exemplu de șablon de prompt:
prompt_template = """
Context: {context}
Întrebare: {question}
Te rog oferă un răspuns detaliat folosind contextul de mai sus.
"""
Post-procesare și validare
Fluxurile avansate includ detectarea halucinațiilor, verificări de relevanță sau evaluări ale răspunsurilor pentru a asigura că ieșirea este factuală și relevantă.
Suport clienți
Chatboții pot recupera manuale de produs, ghiduri de depanare sau FAQ-uri pentru a oferi răspunsuri instantanee clienților.
Exemplu: Un chatbot care ajută un client să reseteze un router, recuperând secțiunea relevantă din manualul de utilizare.
Managementul cunoștințelor în întreprinderi
Chatboții interni pot accesa date specifice companiei, ca politici HR, documentație IT sau ghiduri de conformitate.
Exemplu: Angajații întreabă chatbotul intern despre politica de concedii medicale.
E-Commerce
Chatboții ajută utilizatorii preluând detalii despre produse, recenzii sau disponibilitatea stocului.
Exemplu: „Care sunt principalele caracteristici ale produsului Y?”
Sănătate
Chatboții preiau literatură medicală, ghiduri sau date despre pacienți pentru a asista profesioniștii din sănătate sau pacienții.
Exemplu: Un chatbot care recuperează avertizări privind interacțiunile medicamentoase dintr-o bază farmaceutică.
Educație și cercetare
Chatboții academici folosesc fluxuri RAG pentru a prelua articole științifice, a răspunde la întrebări sau a rezuma concluzii de cercetare.
Exemplu: „Poți rezuma concluziile studiului din 2023 despre schimbările climatice?”
Legal și conformitate
Chatboții recuperează documente legale, jurisprudență sau cerințe de conformitate pentru a asista profesioniștii din domeniu.
Exemplu: „Care sunt ultimele actualizări privind reglementările GDPR?”
Un chatbot construit pentru a răspunde la întrebări din raportul anual financiar al unei companii, în format PDF.
Un chatbot care combină SQL, căutare vectorială și grafuri de cunoștințe pentru a răspunde la întrebările angajaților.
Prin utilizarea fluxurilor de preluare, chatboții nu mai sunt limitați de datele statice de antrenament, putând oferi interacțiuni dinamice, precise și bogate în context.
Fluxurile de preluare joacă un rol esențial în sistemele moderne de chatboți, permițând interacțiuni inteligente și adaptate contextului.
„Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” de Pengfei Zhu et al. (2018)
Prezentarea Lingke, un chatbot care integrează preluarea de informații pentru a gestiona conversații multi-turn. Utilizează procesare fină pe fluxuri pentru a distila răspunsuri din documente nestructurate și folosește potrivire atentă context-răspuns pentru interacțiuni secvențiale, îmbunătățind semnificativ capacitatea chatbotului de a răspunde la întrebări complexe.
Citește articolul aici.
„FACTS About Building Retrieval Augmented Generation-based Chatbots” de Rama Akkiraju et al. (2024)
Explorează provocările și metodologiile dezvoltării de chatboți enterprise folosind fluxuri Generare Augmentată prin Preluare (RAG) și modele lingvistice mari (LLM). Autorii propun cadrul FACTS, punând accent pe Freshness, Architectures, Cost, Testing și Security în ingineria fluxurilor RAG. Concluziile lor evidențiază compromisurile între acuratețe și latență la scalarea LLM-urilor, oferind perspective valoroase pentru construirea de chatboți siguri și performanți. Citește articolul aici.
„From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” de Subash Neupane et al. (2024)
Prezintă BARKPLUG V.2, un sistem chatbot creat pentru universități. Utilizând fluxuri RAG, sistemul oferă răspunsuri precise și specifice domeniului despre resursele de pe campus, îmbunătățind accesul la informații. Studiul evaluează eficiența chatbotului folosind cadre ca RAG Assessment (RAGAS) și evidențiază utilitatea sa în mediile academice. Citește articolul aici.
Un flux de preluare este o arhitectură tehnică ce permite chatboților să acceseze, proceseze și să recupereze informații relevante din surse externe ca răspuns la întrebările utilizatorilor. Acesta combină ingestia de date, embedding-uri, stocare vectorială și generare de răspunsuri cu LLM pentru replici dinamice și contextuale.
RAG combină punctele forte ale sistemelor de preluare a datelor cu modelele lingvistice mari (LLM), permițând chatboților să fundamenteze răspunsurile pe date externe, actuale și factuale, reducând astfel halucinațiile și crescând acuratețea.
Componentele cheie includ ingestia documentelor, preprocesare, generarea embedding-urilor, stocarea vectorială, procesarea interogărilor, preluarea datelor, generarea răspunsurilor și validarea post-procesare.
Cazurile de utilizare includ suportul pentru clienți, managementul cunoștințelor în întreprinderi, informații despre produse în e-commerce, ghidare medicală, educație și cercetare, precum și asistență pentru conformitate legală.
Provocările includ latența cauzată de preluarea în timp real, costurile operaționale, preocupările privind confidențialitatea datelor și cerințele de scalabilitate pentru gestionarea unor volume mari de date.
Descătușați puterea Generării Augmentate prin Preluare (RAG) și a integrării datelor externe pentru a livra răspunsuri inteligente și precise cu chatbotul. Încercați platforma no-code FlowHunt chiar azi.
Un chatbot AI pentru serviciul clienți care folosește sursele interne de cunoștințe pentru a oferi răspunsuri instantanee, precise și utile la întrebările clien...
Un chatbot în timp real care utilizează Căutarea Google restricționată la propriul tău domeniu, preia conținut web relevant și folosește OpenAI LLM pentru a răs...
Un chatbot de suport clienți alimentat de inteligență artificială care asistă automat utilizatorii, recuperează informații din documente interne și de pe web și...