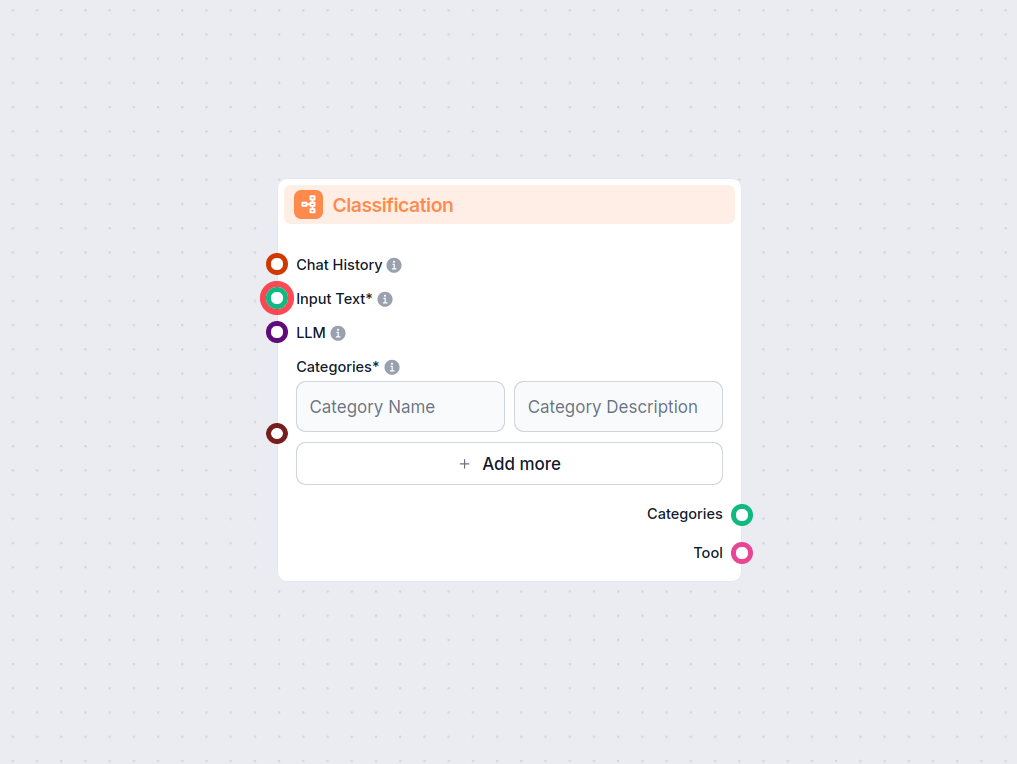
Clasificare de text
Activează categorisirea automată a textului în fluxurile tale de lucru cu componenta de Clasificare de Text pentru FlowHunt. Clasifică cu ușurință textul introd...
3 min citire
AI
Classification
+3
Clasificarea textului folosește NLP și învățarea automată pentru a atribui automat categorii textului, alimentând aplicații precum analiza sentimentelor, detectarea spamului și organizarea datelor.
Clasificarea textului, cunoscută și ca categorizare sau etichetare a textului, este o sarcină esențială de Procesare a Limbajului Natural (NLP) care presupune atribuirea unor categorii predefinite documentelor text. Această metodă organizează, structurează și categorizează datele textuale nestructurate, facilitând analiza și interpretarea acestora. Clasificarea textului este utilizată într-o varietate de aplicații, inclusiv analiza sentimentelor, detectarea spamului și categorizarea subiectelor.
Conform AWS, clasificarea textului servește ca prim pas în organizarea, structurarea și categorizarea datelor pentru analize ulterioare. Ea permite etichetarea și organizarea automată a documentelor, permițând companiilor să gestioneze și să analizeze eficient volume mari de date textuale. Această capacitate de a automatiza etichetarea documentelor reduce intervenția manuală și îmbunătățește procesele de luare a deciziilor bazate pe date.
Clasificarea textului este alimentată de învățarea automată, unde modelele AI sunt antrenate pe seturi de date etichetate pentru a învăța tiparele și corelațiile dintre caracteristicile textuale și categoriile lor respective. Odată antrenate, aceste modele pot clasifica documente text noi și nevăzute cu acuratețe și eficiență ridicată. După cum menționează Towards Data Science, acest proces simplifică organizarea conținutului, făcând mai ușoară căutarea și navigarea utilizatorilor pe site-uri sau în aplicații.
Modelele de clasificare a textului sunt algoritmi care automatizează categorizarea datelor textuale. Aceste modele învață din exemplele dintr-un set de antrenament și aplică cunoștințele dobândite pentru a clasifica noi intrări de text. Modele populare includ:
Support Vector Machines (SVM): Un algoritm de învățare supravegheată eficient atât pentru sarcini de clasificare binară, cât și multiclasă. SVM identifică hiperplanul care separă cel mai bine punctele de date din diferite categorii. Această metodă este potrivită pentru aplicații unde frontiera de decizie trebuie să fie clar definită.
Naive Bayes: Un clasificator probabilistic care aplică Teorema lui Bayes presupunând independența caracteristicilor. Este deosebit de eficient pentru seturi mari de date datorită simplității și rapidității sale. Naive Bayes este folosit frecvent în detectarea spamului și analizele de text unde este necesară o procesare rapidă.
Modele de învățare profundă: Acestea includ Rețele Neuronale Convoluționale (CNN) și Rețele Neuronale Recurente (RNN), care pot surprinde tipare complexe în datele textuale prin utilizarea mai multor straturi de procesare. Modelele de învățare profundă sunt utile pentru sarcini de clasificare de scară mare și pot atinge acuratețe ridicată în analiza sentimentelor și modelarea limbajului.
Arbori de decizie și Păduri aleatoare: Metode bazate pe arbori care clasifică textul prin învățarea regulilor de decizie derivate din caracteristicile datelor. Aceste modele sunt apreciate pentru interpretabilitatea lor și pot fi folosite în diverse aplicații precum categorizarea feedback-ului clienților și clasificarea documentelor.
Procesul de clasificare a textului implică mai mulți pași:
Colectarea și pregătirea datelor: Datele textuale sunt colectate și preprocesate. Acest pas poate implica tokenizarea, stemming-ul și eliminarea cuvintelor stop pentru curățarea datelor. Conform Levity AI, datele textuale sunt un activ valoros pentru înțelegerea comportamentului consumatorilor, iar preprocesarea corectă este esențială pentru extragerea de informații acționabile.
Extragerea caracteristicilor: Transformarea textului în reprezentări numerice pe care algoritmii de învățare automată le pot procesa. Tehnici includ:
Antrenarea modelului: Modelul de învățare automată este antrenat folosind setul de date etichetat. Modelul învață să asocieze caracteristicile cu categoriile corespunzătoare.
Evaluarea modelului: Performanța modelului este evaluată folosind metrici precum acuratețea, precizia, recall-ul și scorul F1. Se folosește adesea validarea încrucișată pentru a asigura generalizarea pe date nevăzute. AWS subliniază importanța evaluării performanței clasificării textului pentru a garanta acuratețea și fiabilitatea dorite.
Predicție și implementare: Odată ce modelul este validat, acesta poate fi implementat pentru a clasifica noi date textuale.
Clasificarea textului este folosită pe scară largă în diverse domenii:
Analiza sentimentelor: Detectarea sentimentului exprimat în text, adesea utilizată pentru feedback-ul clienților și analiza rețelelor sociale pentru a evalua opinia publică. Levity AI evidențiază rolul clasificării textului în social listening, ceea ce ajută companiile să înțeleagă sentimentele clienților din spatele comentariilor și feedback-ului.
Detectarea spamului: Filtrarea e-mailurilor nesolicitate și potențial dăunătoare prin clasificarea lor ca spam sau legitime. Filtrarea și etichetarea automată, precum cele folosite în Gmail, sunt exemple clasice de detectare a spamului prin clasificarea textului.
Categorizarea subiectelor: Organizarea conținutului în subiecte predefinite, utilă pentru articole de știri, bloguri și lucrări de cercetare. Această aplicație simplifică gestionarea și regăsirea conținutului, îmbunătățind experiența utilizatorilor.
Categorizarea tichetelor de suport clienți: Direcționarea automată a tichetelor de suport către departamentul potrivit pe baza conținutului acestora. Această automatizare crește eficiența în gestionarea solicitărilor clienților și reduce volumul de muncă al echipelor de suport.
Detectarea limbii: Identificarea limbii unui document text pentru aplicații multilingve. Această capacitate este esențială pentru companiile globale care operează în mai multe limbi și regiuni.
Clasificarea textului prezintă mai multe provocări:
Calitatea și cantitatea datelor: Performanța modelelor de clasificare a textului depinde în mare măsură de calitatea și cantitatea datelor de antrenament. Datele insuficiente sau zgomotoase pot duce la performanță slabă a modelului. AWS menționează că organizațiile trebuie să asigure colectarea și etichetarea de date de înaltă calitate pentru a obține rezultate corecte de clasificare.
Selecția caracteristicilor: Alegerea caracteristicilor potrivite este crucială pentru acuratețea modelului. Supraadaptarea poate apărea dacă modelul este antrenat pe caracteristici irelevante.
Interpretabilitatea modelului: Modelele de învățare profundă, deși puternice, acționează adesea ca niște „cutii negre”, fiind dificil de înțeles cum sunt luate deciziile. Această lipsă de transparență poate fi o barieră în domenii unde interpretabilitatea este esențială.
Scalabilitatea: Pe măsură ce volumul datelor textuale crește, modelele trebuie să se scaleze eficient pentru a gestiona seturi mari de date. Sunt necesare tehnici de procesare eficiente și infrastructură scalabilă pentru a gestiona sarcina crescută de date.
Clasificarea textului este esențială pentru automatizarea bazată pe AI și [chatboți. Prin categorizarea și interpretarea automată a intrărilor textuale, chatboții pot oferi răspunsuri relevante, pot îmbunătăți interacțiunile cu clienții și pot eficientiza procesele de business. În automatizarea AI, clasificarea textului permite sistemelor să proceseze și să analizeze volume mari de date cu intervenție umană minimă, îmbunătățind eficiența și capacitatea de luare a deciziilor.
Mai mult, progresele în NLP și învățarea profundă au dotat chatboții cu capabilități sofisticate de clasificare a textului, permițându-le să înțeleagă contextul, sentimentul și intenția, oferind astfel interacțiuni mai personalizate și precise cu utilizatorii. AWS sugerează că integrarea clasificării textului în aplicațiile AI poate îmbunătăți semnificativ experiența utilizatorului prin furnizarea de informații relevante și la timp.
Cercetare în clasificarea textului
Clasificarea textului este o sarcină critică în procesarea limbajului natural care presupune categorizarea automată a textului în etichete predefinite. Mai jos sunt rezumate ale unor lucrări științifice recente care oferă perspective asupra diverselor metode și provocări asociate clasificării textului:
Model și evaluare: Către echitate în clasificarea textului multilingv
Autori: Nankai Lin, Junheng He, Zhenghang Tang, Dong Zhou, Aimin Yang
Publicat: 2023-03-28
Această lucrare abordează provocarea părtinirii în modelele de clasificare a textului multilingv. Propune un cadru de debiasare folosind învățarea contrastivă care nu se bazează pe resurse lingvistice externe. Cadrul include module pentru reprezentarea textului multilingv, fuziunea limbajului, debiasarea textului și clasificare. De asemenea, introduce un nou cadru de evaluare a echității multidimensionale, vizând îmbunătățirea echității între diferite limbi. Această lucrare este semnificativă pentru îmbunătățirea echității și acurateței modelelor multilingve de clasificare a textului. Citește mai mult
Clasificarea textului folosind reguli de asociere cu un concept hibrid de clasificator Naive Bayes și algoritm genetic
Autori: S. M. Kamruzzaman, Farhana Haider, Ahmed Ryadh Hasan
Publicat: 2010-09-25
Această cercetare prezintă o abordare inovatoare pentru clasificarea textului folosind reguli de asociere combinate cu Naive Bayes și Algoritmi Genetici. Metoda derivă caracteristici din documente pre-clasificate folosind relații între cuvinte, nu cuvinte individuale. Integrarea algoritmilor genetici îmbunătățește performanța finală a clasificării. Rezultatele demonstrează eficiența acestei abordări hibride în realizarea unei clasificări de succes a textului. Citește mai mult
Clasificarea textului: O perspectivă asupra metodelor de învățare profundă
Autor: Zhongwei Wan
Publicat: 2023-09-24
Odată cu creșterea exponențială a datelor de pe internet, această lucrare evidențiază importanța metodelor de învățare profundă în clasificarea textului. Sunt discutate diverse tehnici de învățare profundă care îmbunătățesc acuratețea și eficiența clasificării textelor complexe. Studiul subliniază rolul în evoluție al învățării profunde în gestionarea seturilor mari de date și furnizarea unor rezultate precise de clasificare. Citește mai mult
Clasificarea textului este o sarcină de Procesare a Limbajului Natural (NLP) în care categorii predefinite sunt atribuite documentelor text, permițând organizarea, analiza și interpretarea automată a datelor nestructurate.
Modelele comune includ Support Vector Machines (SVM), Naive Bayes, modele de învățare profundă precum CNN și RNN, și metode bazate pe arbori, cum ar fi arborii de decizie și pădurile aleatoare (Random Forests).
Clasificarea textului este utilizată pe scară largă în analiza sentimentelor, detectarea spamului, categorizarea subiectelor, direcționarea tichetelor de suport clienți și detectarea limbii.
Provocările includ asigurarea calității și cantității datelor, selecția corectă a caracteristicilor, interpretabilitatea modelului și scalabilitatea pentru a gestiona volume mari de date.
Clasificarea textului permite automatizarea și chatboții alimentați de AI să interpreteze, să categorizeze și să răspundă eficient la intrările utilizatorilor, îmbunătățind interacțiunile cu clienții și procesele de afaceri.
Începe să construiești chatboți inteligenți și instrumente AI care utilizează clasificarea automată a textului pentru a spori eficiența și perspectivele.
Activează categorisirea automată a textului în fluxurile tale de lucru cu componenta de Clasificare de Text pentru FlowHunt. Clasifică cu ușurință textul introd...
Auto-clasificarea automatizează categorizarea conținutului prin analizarea proprietăților și atribuirea etichetelor folosind tehnologii precum învățarea automat...
Un clasificator AI este un algoritm de învățare automată care atribuie etichete de clasă datelor de intrare, categorisind informația în clase predefinite pe baz...
