Transformer
Un model transformer este un tip de rețea neuronală proiectată special pentru a gestiona date secvențiale, cum ar fi textul, vorbirea sau datele de tip time-ser...
3 min citire
Transformer
Neural Networks
+3
Transformatoarele sunt rețele neuronale revoluționare care utilizează mecanismul de self-attention pentru procesarea paralelă a datelor, alimentând modele precum BERT și GPT în NLP, viziune și nu numai.
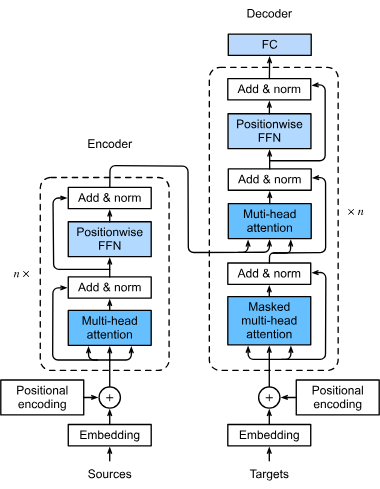
Primul pas în fluxul de procesare al unui model transformator implică transformarea cuvintelor sau tokenilor dintr-o secvență de intrare în vectori numerici, cunoscuți sub numele de embeddings. Aceste reprezentări numerice capturează sensurile semantice și sunt esențiale pentru ca modelul să înțeleagă relațiile dintre tokeni. Această transformare este esențială deoarece permite modelului să proceseze datele textuale într-o formă matematică.
Transformatoarele nu procesează datele în mod inerent secvențial; de aceea, codificarea pozițională este folosită pentru a introduce informații despre poziția fiecărui token în secvență. Acest lucru este vital pentru menținerea ordinii secvenței, crucială pentru sarcini precum traducerea automată, unde contextul poate depinde de ordinea cuvintelor.
Mecanismul de atenție multi-head este o componentă sofisticată a transformatoarelor, care permite modelului să se concentreze simultan pe diferite părți ale secvenței de intrare. Prin calcularea mai multor scoruri de atenție, modelul poate surprinde diverse relații și dependențe în date, sporindu-i capacitatea de a înțelege și genera tipare complexe.
Transformatoarele urmează de obicei o arhitectură encoder-decoder:
După mecanismul de atenție, datele trec prin rețele neuronale feedforward, care aplică transformări neliniare asupra datelor, ajutând modelul să învețe tipare complexe. Aceste rețele procesează suplimentar datele pentru a rafina rezultatul generat de model.
Aceste tehnici sunt integrate pentru a stabiliza și accelera procesul de antrenare. Normalizarea pe straturi asigură că ieșirile rămân într-un anumit interval, facilitând antrenarea eficientă a modelului. Conexiunile reziduale permit propagarea gradientului prin rețele fără să dispară, ceea ce îmbunătățește antrenarea rețelelor neuronale profunde.
Transformatoarele operează pe secvențe de date, care pot fi cuvinte într-o propoziție sau alte informații secvențiale. Ele aplică self-attention pentru a determina relevanța fiecărei părți a secvenței în raport cu celelalte, permițând modelului să se concentreze pe elementele esențiale care influențează rezultatul.
În self-attention, fiecare token din secvență este comparat cu fiecare alt token pentru a calcula scoruri de atenție. Aceste scoruri indică semnificația fiecărui token în contextul celorlalte, permițând modelului să se concentreze pe cele mai relevante părți ale secvenței. Acest lucru este esențial pentru înțelegerea contextului și sensului în sarcinile de limbaj.
Acestea sunt blocurile de bază ale unui model transformator, formate din straturi de self-attention și feedforward. Mai multe astfel de blocuri sunt stivuite pentru a forma modele de învățare profundă capabile să capteze tipare complexe în date. Această proiectare modulară permite transformatoarelor să se scaleze eficient odată cu complexitatea sarcinii.
Transformatoarele sunt mai eficiente decât RNN-urile și CNN-urile datorită capacității lor de a procesa secvențe întregi simultan. Această eficiență permite scalarea la modele foarte mari, precum GPT-3, care are 175 de miliarde de parametri. Scalabilitatea transformatoarelor le permite să gestioneze eficient cantități vaste de date.
Modelele tradiționale întâmpină dificultăți cu dependențele pe termen lung din cauza naturii lor secvențiale. Transformatoarele depășesc această limitare prin self-attention, care poate lua în considerare toate părțile secvenței simultan. Acest lucru le face deosebit de eficiente în sarcini ce necesită înțelegerea contextului pe secvențe lungi de text.
Deși inițial concepute pentru sarcinile NLP, transformatoarele au fost adaptate pentru diverse aplicații, inclusiv viziune computerizată, plierea proteinelor și chiar prognoza seriilor temporale. Această versatilitate demonstrează aplicabilitatea largă a transformatoarelor în diferite domenii.
Transformatoarele au îmbunătățit semnificativ performanța sarcinilor NLP precum traducerea, rezumarea și analiza sentimentelor. Modele precum BERT și GPT sunt exemple proeminente care utilizează arhitectura de transformator pentru a înțelege și genera text asemănător celui uman, stabilind noi standarde în NLP.
În traducerea automată, transformatoarele excelează prin înțelegerea contextului cuvintelor într-o propoziție, permițând traduceri mai precise comparativ cu metodele anterioare. Capacitatea lor de a procesa propoziții întregi simultan permite traduceri mai coerente și corecte contextual.
Transformatoarele pot modela secvențele de aminoacizi din proteine, ajutând la predicția structurilor proteice, esențială pentru descoperirea de medicamente și înțelegerea proceselor biologice. Această aplicație evidențiază potențialul transformatoarelor în cercetarea științifică.
Prin adaptarea arhitecturii de transformator, este posibilă prezicerea valorilor viitoare în date de tip serie temporală, precum prognoza cererii de energie electrică, prin analizarea secvențelor anterioare. Aceasta deschide noi posibilități pentru transformatoare în domenii precum finanțele și managementul resurselor.
Modelele BERT sunt concepute pentru a înțelege contextul unui cuvânt analizând cuvintele din jurul său, ceea ce le face extrem de eficiente pentru sarcini ce necesită înțelegerea relațiilor dintre cuvinte într-o propoziție. Această abordare bidirecțională permite lui BERT să capteze contextul mai eficient decât modelele unidirecționale.
Modelele GPT sunt autoregresive, generând text prin prezicerea următorului cuvânt dintr-o secvență pe baza cuvintelor precedente. Sunt utilizate pe scară largă în aplicații precum completarea textului și generarea de dialoguri, demonstrând capacitatea lor de a produce texte asemănătoare celor scrise de oameni.
Deși au fost dezvoltate inițial pentru NLP, transformatoarele au fost adaptate pentru sarcini de viziune computerizată. Vision transformers procesează datele de imagine ca secvențe, permițând aplicarea tehnicilor de transformator pe intrări vizuale. Această adaptare a dus la progrese în recunoașterea și procesarea imaginilor.
Antrenarea modelelor mari de transformator necesită resurse computaționale substanțiale, adesea implicând seturi de date vaste și hardware performant, precum GPU-uri. Aceasta reprezintă o provocare în ceea ce privește costurile și accesibilitatea pentru multe organizații.
Pe măsură ce transformatoarele devin tot mai răspândite, probleme precum prejudecățile din modelele AI și utilizarea etică a conținutului generat de AI devin din ce în ce mai importante. Cercetătorii dezvoltă metode pentru a minimiza aceste probleme și a asigura dezvoltarea responsabilă a AI, subliniind nevoia unor cadre etice în cercetarea AI.
Versatilitatea transformatoarelor continuă să deschidă noi direcții de cercetare și aplicare, de la îmbunătățirea chatbot-urilor bazate pe AI până la optimizarea analizei de date în domenii precum sănătatea și finanțele. Viitorul transformatoarelor aduce perspective interesante pentru inovație în diverse industrii.
În concluzie, transformatoarele reprezintă un progres semnificativ în tehnologia AI, oferind capabilități fără precedent în procesarea datelor secvențiale. Arhitectura lor inovatoare și eficiența ridicată au stabilit un nou standard în domeniu, propulsând aplicațiile AI către noi orizonturi. Fie că este vorba despre înțelegerea limbajului, cercetare științifică sau procesarea datelor vizuale, transformatoarele continuă să redefinească ceea ce este posibil în universul inteligenței artificiale.
Transformatoarele au revoluționat domeniul inteligenței artificiale, în special procesarea limbajului natural și înțelegerea acestuia. Lucrarea „AI Thinking: A framework for rethinking artificial intelligence in practice” de Denis Newman-Griffis (publicată în 2024) explorează un nou cadru conceptual numit AI Thinking. Acest cadru modelează deciziile și considerațiile cheie implicate în utilizarea AI din perspective disciplinare diverse, abordând competențe în motivarea folosirii AI, formularea metodelor AI și plasarea AI în contexte sociotehnice. Scopul său este să unească disciplinele academice și să remodeleze viitorul AI în practică. Citește mai mult.
O altă contribuție semnificativă este prezentată în „Artificial intelligence and the transformation of higher education institutions” de Evangelos Katsamakas și colaboratorii (publicată în 2024), care utilizează o abordare a sistemelor complexe pentru a cartografia mecanismele de feedback cauzal ale transformării AI în instituțiile de învățământ superior (HEIs). Studiul discută forțele care conduc transformarea AI și impactul acesteia asupra creării de valoare, subliniind necesitatea ca HEIs să se adapteze la avansul tehnologic AI gestionând în același timp integritatea academică și schimbările de ocupare a forței de muncă. Citește mai mult.
În domeniul dezvoltării software, lucrarea „Can Artificial Intelligence Transform DevOps?” de Mamdouh Alenezi și colegii săi (publicată în 2022) analizează intersecția dintre AI și DevOps. Studiul evidențiază modul în care AI poate îmbunătăți funcționalitatea proceselor DevOps, facilitând livrarea eficientă a software-ului. Acesta subliniază implicațiile practice pentru dezvoltatorii de software și companii în valorificarea AI pentru a transforma practicile DevOps. Citește mai mult
Transformatoarele sunt o arhitectură de rețea neuronală introdusă în 2017 care utilizează mecanisme de self-attention pentru procesarea paralelă a datelor secvențiale. Ele au revoluționat inteligența artificială, în special procesarea limbajului natural și viziunea computerizată.
Spre deosebire de RNN-uri și CNN-uri, transformatoarele procesează toate elementele unei secvențe simultan folosind self-attention, permițând o eficiență mai mare, scalabilitate și capacitatea de a captura dependențe pe distanțe lungi.
Transformatoarele sunt utilizate pe scară largă în sarcini NLP precum traducerea, rezumarea și analiza sentimentelor, precum și în viziunea computerizată, predicția structurii proteinelor și prognoza seriilor temporale.
Modele notabile de transformatoare includ BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) și Vision Transformers pentru procesarea imaginilor.
Transformatoarele necesită resurse computaționale semnificative pentru antrenare și implementare. De asemenea, ridică probleme etice precum posibilele prejudecăți în modelele AI și utilizarea responsabilă a conținutului generat de AI.
Chatboți inteligenți și instrumente AI sub același acoperiș. Conectează blocuri intuitive pentru a transforma ideile tale în Fluxuri automatizate.
Un model transformer este un tip de rețea neuronală proiectată special pentru a gestiona date secvențiale, cum ar fi textul, vorbirea sau datele de tip time-ser...
Un Transformator Generativ Pre-antrenat (GPT) este un model AI care utilizează tehnici de învățare profundă pentru a produce texte ce imită îndeaproape scrierea...
O Rețea de Convingere Profundă (Deep Belief Network, DBN) este un model generativ sofisticat care utilizează arhitecturi profunde și Mașini Boltzmann Restricțio...