Oricât de puternic ar fi, AI-ul este tot o mașină care redă informațiile pe care le învață. Nu înțelege glume, ipotetice sau sarcasm, care sunt adesea responsabile pentru cele mai amuzante (și uneori grav dăunătoare) răspunsuri. Pentru a te asigura că chatbotul tău nu creează cel mai nou scandal AI și pentru a-l ajuta să înțeleagă mai bine conținutul tău, îi poți indica ce conținut să ignore.
Modalitatea de a garanta fiabilitatea AI-ului este monitorizarea informațiilor din care învață. Nu tot conținutul tău va fi potrivit pentru chatbot. Clasa flowhunt-skip îți permite să marchezi conținutul pe care FlowHunt nu ar trebui să îl indexeze. Orice element HTML cu această clasă va fi ignorat la procesarea conținutului.
Când să folosești parametrul de omiterea indexării
Există două motive principale pentru care ar trebui să folosești această clasă, dar o poți folosi pe orice conținut pe care îl consideri inutil sau nepotrivit pentru bot.
Omiterea conținutului repetitiv: Dacă un conținut similar este indexat în mod repetat, AI-ul va avea dificultăți în a distinge și a categoriza despre ce este vorba. Omiterea informațiilor duplicate te ajută și să economisești bani pe termen lung la procesarea textului.
Omiterea informațiilor riscante sau nepotrivite: Ar trebui să omiți orice informație care ar putea determina AI-ul să ofere răspunsuri greșite, dăunătoare sau scoase din context. Fii deosebit de atent dacă tonul brandului tău folosește frecvent glume sau un limbaj puternic. Deși este potrivit în alte tipuri de conținut, utilizatorii s-ar putea să nu aprecieze un bot sarcastic.
Cum se folosește parametrul flowhunt-skip
FlowHunt scanează și indexează website-ul tău pentru a oferi context chatbotului. Orice indexează FlowHunt poate fi folosit de chatbot la un moment dat.
Adăugarea clasei flowhunt-skip la elemente HTML îți permite să marchezi conținutul pe care nu vrei să-l indexezi. Orice element cu această clasă va fi ignorat și nu va ajunge niciodată la chatbot.
Iată un exemplu de utilizare a clasei:
<div class="flowhunt-skip">
<h2>Conținut duplicat</h2>
<p>Acest conținut este duplicat. Nu vreau ca FlowHunt să îl indexeze din nou.</p>
</div>
Poți să omiți și doar un singur paragraf sau o parte dintr-un element:
<div>
<h2>Conținutul meu</h2>
<p>Acest paragraf ar trebui să fie indexat.</p>
<p class="flowhunt-skip">Nu vreau ca chatbotul să folosească această informație.</p>
<p>Acest paragraf ar trebui să fie indexat.</p>
</div>
Pregătit să îți dezvolți afacerea?
Începe perioada de probă gratuită astăzi și vezi rezultate în câteva zile.
Cum funcționează indexarea
Procesul de crawling rulează în fundal și se bazează pe programările pe care le setezi. Se descarcă doar pagina HTML. Imaginile sau fișierele media sunt stocate doar ca linkuri. Redirecționările sunt urmărite, iar URL-urile canonice sunt evaluate.
După ce crawling-ul este finalizat, conținutul HTML este convertit în text markdown simplu. O parte din informații pot fi eliminate în acest proces. Textul final în markdown este oferit chatbotului ca și context. Botul poate apoi să recupereze aceste informații oricând este nevoie.
Cum știe AI-ul ce informație să aleagă
Textul markdown este împărțit în fragmente, vectorizat și stocat într-o bază de date vectorială. Acest tip de bază de date atribuie valori semnificațiilor cuvintelor. Astfel, AI-ul poate înțelege cuvinte înrudite, fără a avea nevoie de o potrivire exactă a cuvintelor.
Cuvintele sunt distribuite pe o grilă în funcție de valorile atribuite. Acest lucru permite computerului să înțeleagă care cuvinte sunt apropiate ca sens:
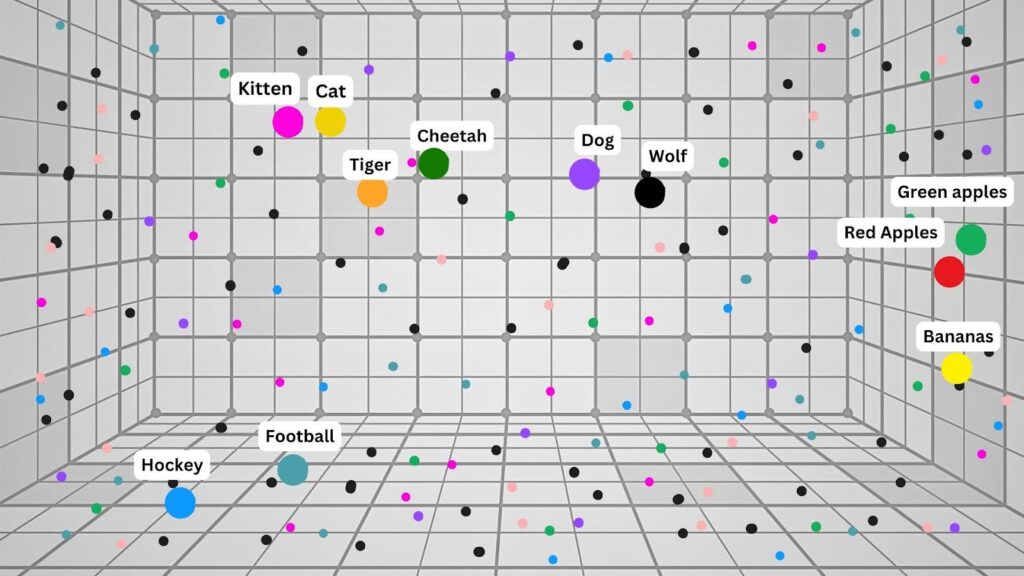
Notă: Acesta este un model foarte simplificat. În practică, AI-ul face acest lucru cu mii de cuvinte, expresii și chiar propoziții întregi.
Recuperarea informațiilor din bazele de date vectoriale se numește căutare semantică. Este abilitatea AI-ului de a căuta și evalua sensul cuvintelor în baza de date vectorială, folosindu-le pentru a oferi răspunsuri.
Când un utilizator trimite o întrebare, botul convertește cuvintele în vectori. Apoi caută în baza de date orice potriviri apropiate din conținutul tău. Găsind potriviri sau conținut similar, folosește acele informații pentru a construi un răspuns.
Abonează-te la newsletter-ul nostru
Primește cele mai recente sfaturi, tendințe și oferte gratuit.
De ce este atât de importantă căutarea semantică
Imaginează-ți că deții un magazin online pentru animale de companie. Un client pune următoarea întrebare:
„Vindeți mâncare pentru pisoi?”
Vindeți, dar denumirea produsului conține cuvântul „junior” în loc de „pisoi”. Botul va putea înțelege că „mâncare pentru pisici junior” este același lucru (sau foarte asemănător) cu „mâncare pentru pisoi” și va ghida cu succes clientul către produsul potrivit.
Fără căutarea semantică în baza de date vectorială, chatbotul ar răspunde simplu că nu comercializezi „mâncare pentru pisoi”, făcându-te să pierzi un potențial client. Nu trebuie să-ți faci griji pentru astfel de situații atunci când folosești FlowHunt.