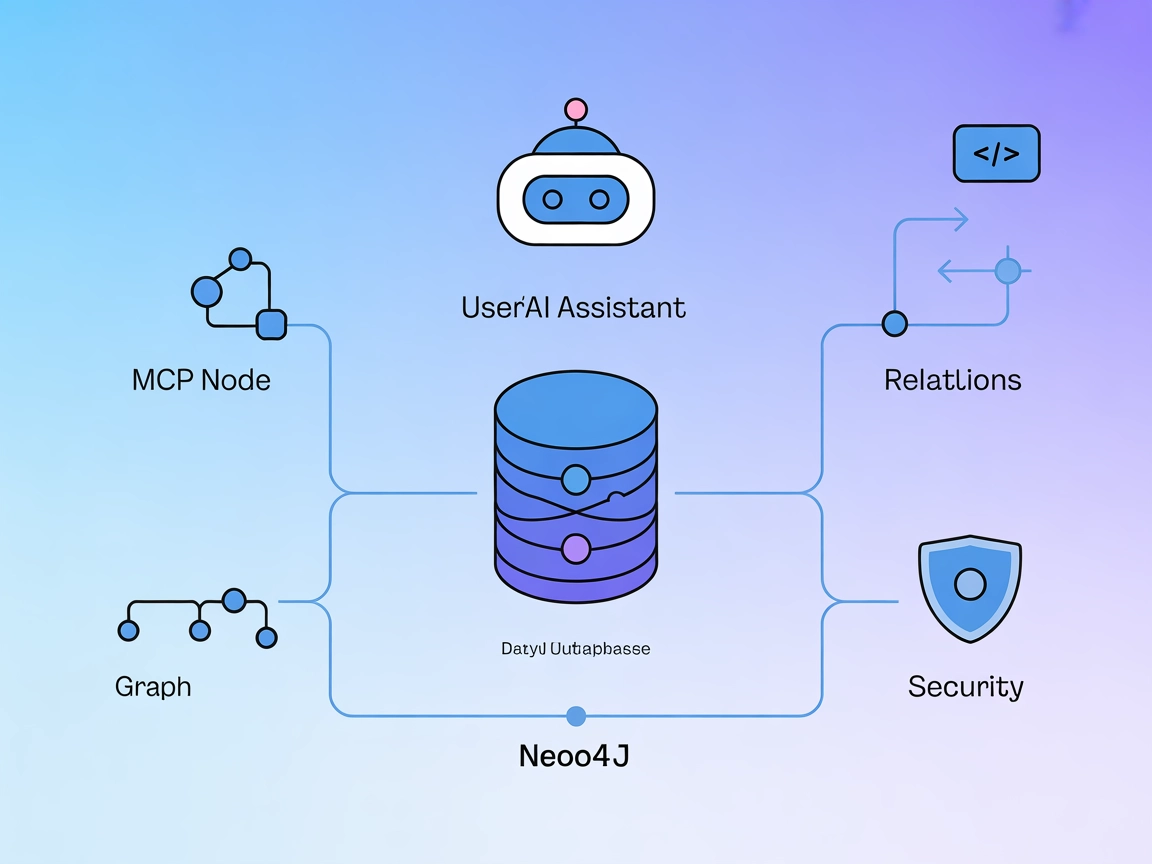
Integrarea serverului Neo4j MCP
Serverul Neo4j MCP realizează legătura dintre asistenții AI și baza de date grafică Neo4j, permițând operațiuni graf bazate pe limbaj natural, interogări Cypher...
5 min citire
AI
Graph Database
+5
Serverul Neo4j MCP realizează legătura dintre asistenții AI și baza de date grafică Neo4j, permițând operațiuni graf bazate pe limbaj natural, interogări Cypher...
Serverul NASA MCP oferă o interfață unificată pentru modelele AI și dezvoltatori pentru a accesa peste 20 de surse de date NASA. Standardizează recuperarea, pro...
Serverul MCP Code Executor MCP permite FlowHunt și altor instrumente bazate pe LLM să execute în siguranță cod Python în medii izolate, să gestioneze dependențe...
Reexpress MCP Server aduce verificare statistică fluxurilor de lucru LLM. Folosind estimatorul Similarity-Distance-Magnitude (SDM), oferă estimări robuste ale n...
Serverul MCP pentru Explorarea Datelor conectează asistenții AI cu seturi de date externe pentru analiză interactivă. Permite utilizatorilor să exploreze seturi...
JupyterMCP permite integrarea fără întreruperi a Jupyter Notebook (6.x) cu asistenți AI prin Model Context Protocol. Automatizează execuția codului, gestionează...
Serverul Databricks Genie MCP permite modelelor lingvistice mari să interacționeze cu mediile Databricks prin intermediul API-ului Genie, susținând explorarea c...
Un Analist de Date AI valorifică abilitățile tradiționale de analiză a datelor împreună cu inteligența artificială (AI) și învățarea automată (ML) pentru a extr...
Un arbore de decizie este un instrument puternic și intuitiv pentru luarea deciziilor și analiza predictivă, folosit atât în sarcini de clasificare, cât și de r...
Aria de sub curbă (AUC) este o metrică fundamentală în învățarea automată, folosită pentru a evalua performanța modelelor de clasificare binară. Ea cuantifică a...
Anaconda este o distribuție open-source cuprinzătoare de Python și R, concepută pentru a simplifica gestionarea pachetelor și implementarea pentru calcul științ...
BigML este o platformă de machine learning concepută pentru a simplifica crearea și implementarea modelelor predictive. Fondată în 2011, misiunea sa este de a f...
Un clasificator AI este un algoritm de învățare automată care atribuie etichete de clasă datelor de intrare, categorisind informația în clase predefinite pe baz...
Clustering K-Means este un algoritm popular de învățare automată nesupravegheată pentru împărțirea seturilor de date într-un număr predefinit de clustere distin...
Curățarea datelor este procesul crucial de detectare și remediere a erorilor sau neconcordanțelor din date pentru a le îmbunătăți calitatea, asigurând acuratețe...
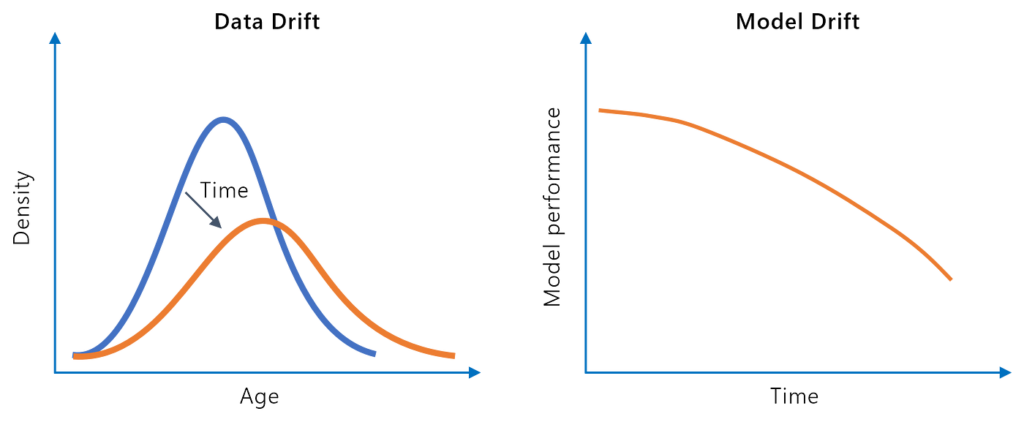
Derivarea modelului, sau degradarea modelului, se referă la scăderea performanței predictive a unui model de învățare automată în timp, din cauza schimbărilor d...
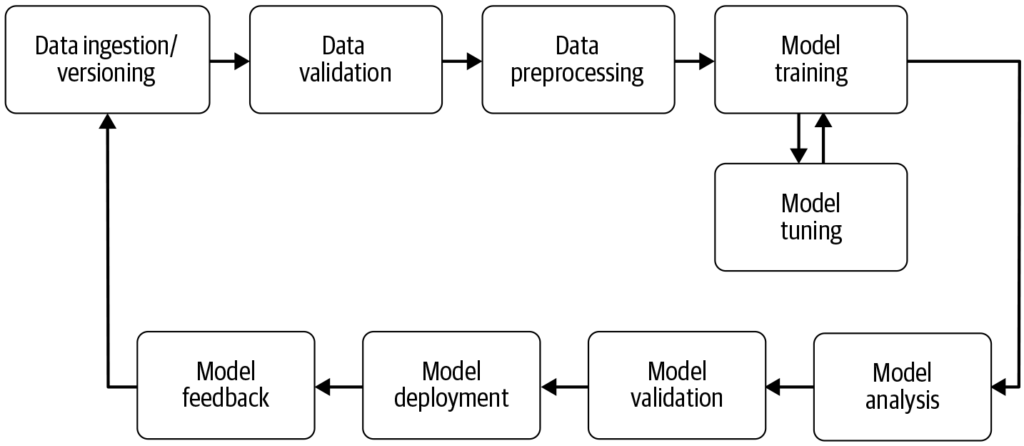
Un flux de lucru învățare automată este un proces automatizat care eficientizează și standardizează dezvoltarea, antrenarea, evaluarea și implementarea modelelo...
Google Colaboratory (Google Colab) este o platformă Jupyter notebook bazată pe cloud, oferită de Google, care permite utilizatorilor să scrie și să execute cod ...
Gradient Boosting este o tehnică puternică de învățare automată de tip ensemble pentru regresie și clasificare. Construiește modele secvențial, de obicei cu arb...
Inferența cauzală este o abordare metodologică folosită pentru a determina relațiile de tip cauză-efect dintre variabile, esențială în științe pentru înțelegere...
Explorează cum Ingineria și Extragerea Caracteristicilor îmbunătățesc performanța modelelor de inteligență artificială prin transformarea datelor brute în infor...
Învățarea semi-supervizată (SSL) este o tehnică de învățare automată care utilizează atât date etichetate, cât și neetichetate pentru antrenarea modelelor, fiin...
Jupyter Notebook este o aplicație web open-source care permite utilizatorilor să creeze și să partajeze documente cu cod live, ecuații, vizualizări și text nara...
Algoritmul k-cei mai apropiați vecini (KNN) este un algoritm de învățare supravegheată, neparametric, utilizat pentru sarcini de clasificare și regresie în învă...
Kaggle este o comunitate online și o platformă pentru data scientists și ingineri de machine learning care colaborează, învață, concurează și împărtășesc perspe...
Lanțurile de modele reprezintă o tehnică de învățare automată în care mai multe modele sunt conectate secvențial, iar ieșirea fiecărui model servește drept intr...
Mineritul de date este un proces sofisticat de analiză a unor seturi vaste de date brute pentru a descoperi tipare, relații și perspective care pot informa stra...
Modelarea predictivă este un proces sofisticat în știința datelor și statistică ce anticipează rezultatele viitoare prin analiza tiparelor din datele istorice. ...
NumPy este o bibliotecă Python open-source esențială pentru calculul numeric, oferind operații eficiente pe tablouri și funcții matematice. Stă la baza calculul...
Pandas este o bibliotecă open-source pentru manipularea și analiza datelor în Python, renumită pentru versatilitatea sa, structurile de date robuste și ușurința...
Explorați părtinirea în AI: înțelegeți sursele, impactul asupra învățării automate, exemple din viața reală și strategii de reducere pentru a construi sisteme A...
R pătrat ajustat este o măsură statistică folosită pentru a evalua cât de bine se potrivește un model de regresie, ținând cont de numărul de predictori pentru a...
Reducerea dimensionalității este o tehnică esențială în procesarea datelor și în învățarea automată, reducând numărul de variabile de intrare dintr-un set de da...
Regresia liniară este o tehnică analitică fundamentală în statistică și învățare automată, modelând relația dintre variabilele dependente și cele independente. ...
Scikit-learn este o bibliotecă open-source puternică pentru învățarea automată în Python, care oferă instrumente simple și eficiente pentru analiza predictivă a...