Toky
Toky sú mozgom celého FlowHunt. Naučte sa ich vytvárať pomocou vizuálneho tvorcu bez kódovania – od umiestnenia prvého komponentu cez integráciu na webstránku, ...
2 min čítania
AI
No-Code
+4

Nový open-source CLI toolkit od FlowHunt umožňuje komplexné hodnotenie workflowov s LLM ako sudcom, poskytuje detailné reporty a automatizované hodnotenie kvality pre AI workflowy.
S radosťou oznamujeme vydanie FlowHunt CLI Toolkit – nášho nového open-source príkazového nástroja, ktorý má zmeniť spôsob, akým vývojári hodnotia a testujú AI workflowy. Tento silný toolkit prináša možnosti hodnotenia na podnikovej úrovni do open-source komunity vrátane pokročilého reportovania a našej inovatívnej implementácie „LLM ako sudca“.
FlowHunt CLI Toolkit predstavuje významný krok vpred v testovaní a hodnotení AI workflowov. Dostupný už teraz na GitHub , tento open-source toolkit poskytuje vývojárom komplexné nástroje na:
Toolkit predstavuje náš záväzok k transparentnosti a komunitou riadenému vývoju, vďaka čomu sú pokročilé techniky AI hodnotenia dostupné vývojárom po celom svete.
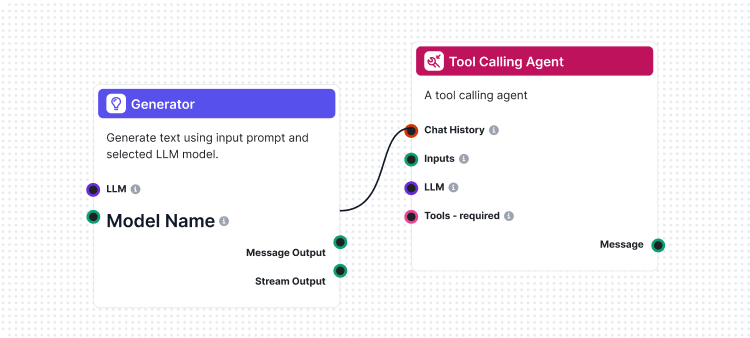
Jednou z najinovatívnejších funkcií nášho CLI toolkit-u je implementácia „LLM ako sudca“. Tento prístup využíva umelú inteligenciu na hodnotenie kvality a správnosti AI-generovaných odpovedí – v podstate umožňuje AI posudzovať výkonnosť inej AI so sofistikovaným zdôvodňovaním.
To, čo robí našu implementáciu výnimočnou, je fakt, že sme na vytvorenie hodnotiaceho workflowu použili samotný FlowHunt. Tento meta-prístup demonštruje silu a flexibilitu našej platformy a zároveň poskytuje robustný hodnotiaci systém. Workflow LLM ako sudca pozostáva z niekoľkých prepojených komponentov:
1. Šablóna promptu: Tvorí hodnotiaci prompt so špecifickými kritériami
2. Generátor štruktúrovaného výstupu: Spracuje hodnotenie pomocou LLM
3. Parser dát: Formátuje štruktúrovaný výstup pre reportovanie
4. Výstup chatu: Zobrazí konečné výsledky hodnotenia
Srdcom nášho systému LLM ako sudca je starostlivo pripravený prompt, ktorý zabezpečuje konzistentné a spoľahlivé hodnotenia. Tu je základná šablóna promptu, ktorú používame:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Tento prompt zabezpečuje, že náš LLM sudca poskytuje:
Začnite svoju 30-dňovú skúšobnú verziu ešte dnes a vidzte výsledky behom pár dní.
Workflow LLM ako sudca demonštruje sofistikovaný dizajn AI workflowu pomocou vizuálneho flow buildera FlowHunt. Tu je, ako spolupracujú jednotlivé komponenty:
Workflow začína komponentom Chat Input, ktorý prijíma požiadavku na hodnotenie obsahujúcu skutočnú odpoveď aj referenčnú odpoveď.
Komponent Šablóna promptu dynamicky zostavuje hodnotiaci prompt nasledovne:
{target_response}{actual_response}Generátor štruktúrovaného výstupu spracuje prompt pomocou vybraného LLM a vygeneruje štruktúrovaný výstup obsahujúci:
total_rating: Číselné hodnotenie od 1 do 4correctness: Binárne určenie správnosti/nesprávnostireasoning: Detailné zdôvodnenie hodnoteniaKomponent Parse Data formátuje štruktúrovaný výstup do čitateľnej podoby a komponent Chat Output zobrazuje konečné výsledky hodnotenia.
Systém LLM ako sudca poskytuje viacero pokročilých funkcií, vďaka ktorým je mimoriadne efektívny pre hodnotenie AI workflowov:
Na rozdiel od jednoduchého porovnávania reťazcov náš LLM sudca rozumie:
Škála 4 bodov umožňuje detailné rozlíšenie:
Každé hodnotenie obsahuje detailné zdôvodnenie, vďaka čomu môžete:
Získajte najnovšie tipy, trendy a ponuky zadarmo.
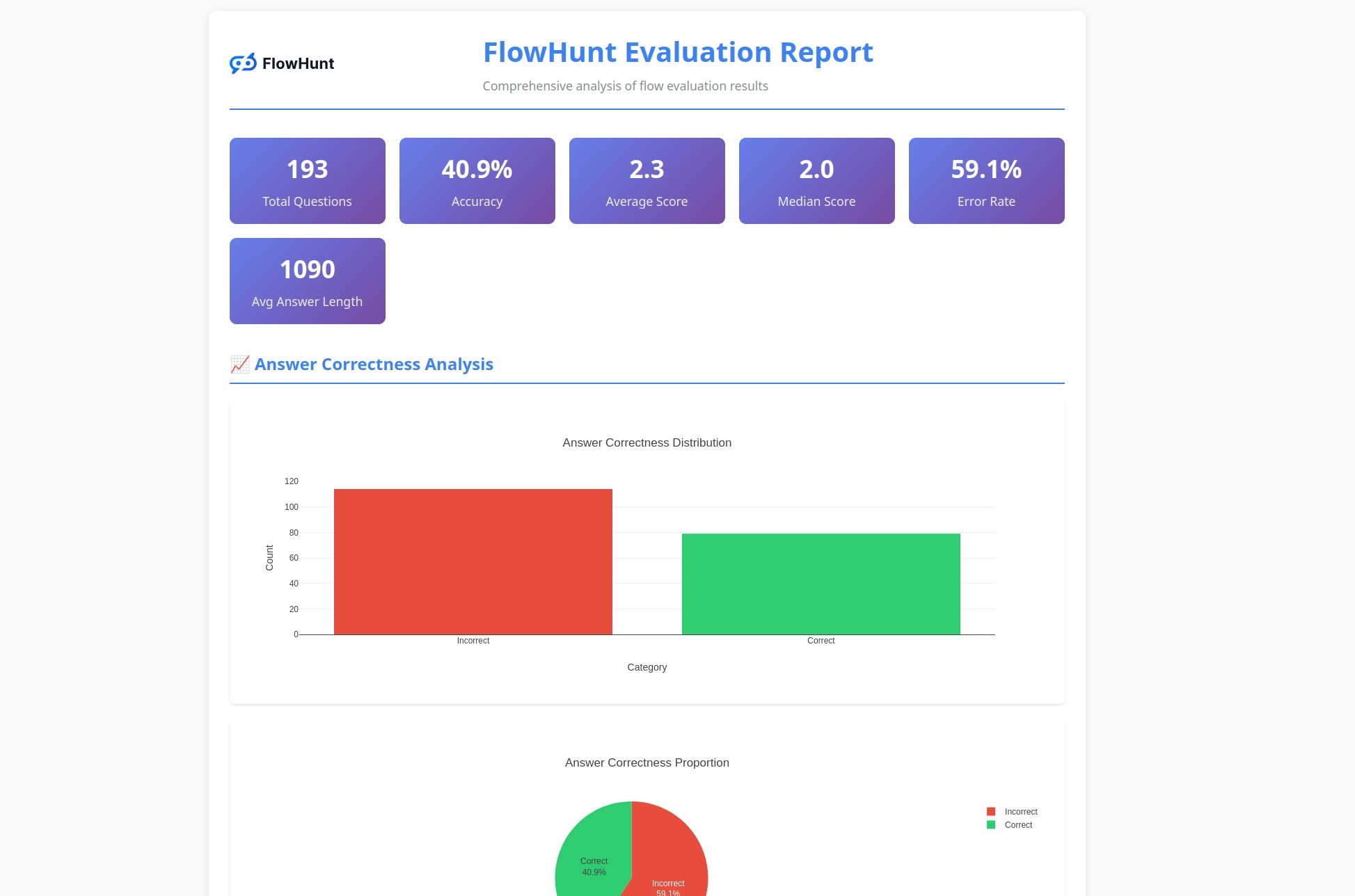
CLI toolkit generuje detailné reporty, ktoré poskytujú akčné poznatky o výkonnosti workflowu:
Chcete začať hodnotiť svoje AI workflowy s profesionálnymi nástrojmi? Tu je postup:
Jednoriadková inštalácia (odporúčané) pre macOS a Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Týmto sa automaticky:
flowhunt do vášho PATHManuálna inštalácia:
# Klonujte repozitár
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Nainštalujte pomocou pip
pip install -e .
Overenie inštalácie:
flowhunt --help
flowhunt --version
1. Autentifikácia Najskôr sa prihláste cez FlowHunt API:
flowhunt auth
2. Zoznam vašich workflowov
flowhunt flows list
3. Hodnotenie workflowu Vytvorte CSV súbor s testovacími dátami:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Spustite hodnotenie s LLM ako sudcom:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Dávkové spúšťanie workflowov
flowhunt batch-run your-flow-id input.csv --output-dir results/
Hodnotiaci systém poskytuje komplexnú analýzu:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Funkcie zahŕňajú:
CLI toolkit sa hladko integruje s platformou FlowHunt, čo vám umožní:
Vydanie nášho CLI toolkitu je viac než len nový nástroj – je to vízia budúcnosti AI vývoja, kde:
Kvalita je merateľná: Pokročilé techniky hodnotenia robia výkonnosť AI kvantifikovateľnou a porovnateľnou.
Testovanie je automatizované: Komplexné testovacie frameworky znižujú manuálnu prácu a zvyšujú spoľahlivosť.
Transparentnosť je štandardom: Detailné zdôvodnenia a reporty robia správanie AI zrozumiteľným a laditeľným.
Komunita poháňa inovácie: Open-source nástroje umožňujú spoločný rozvoj a zdieľanie znalostí.
Open-sourcovým sprístupnením FlowHunt CLI Toolkit demonštrujeme náš záväzok k:
FlowHunt CLI Toolkit s LLM ako sudcom predstavuje významný posun v možnostiach hodnotenia AI workflowov. Spája sofistikovanú hodnotiacu logiku s podrobným reportovaním a open-source dostupnosťou, čím posilňuje vývojárov pri tvorbe lepších a spoľahlivejších AI systémov.
Meta-prístup hodnotenia workflowov FlowHunt pomocou samotného FlowHunt dokazuje vyspelosť a flexibilitu našej platformy a zároveň prináša silný nástroj pre celú AI vývojársku komunitu.
Či už staviate jednoduché chatboty alebo komplexné multiagentné systémy, FlowHunt CLI Toolkit vám poskytne hodnotiacu infraštruktúru potrebnú na zabezpečenie kvality, spoľahlivosti a neustáleho zlepšovania.
Chcete posunúť hodnotenie AI workflowov na vyššiu úroveň? Navštívte náš GitHub repozitár , začnite s FlowHunt CLI Toolkit ešte dnes a zažite silu LLM ako sudcu na vlastné oči.
Budúcnosť AI vývoja je tu – a je open source.
FlowHunt CLI Toolkit je open-source príkazový nástroj na hodnotenie AI workflowov s komplexnými reportovacími možnosťami. Obsahuje funkcie ako hodnotenie LLM ako sudcu, analýzu správnych/nesprávnych výsledkov a detailné metriky výkonu.
LLM ako sudca využíva sofistikovaný AI workflow vytvorený vo FlowHunt na hodnotenie iných workflowov. Porovnáva skutočné odpovede s referenčnými a poskytuje hodnotenia, určenie správnosti a detailné zdôvodnenie pre každé hodnotenie.
FlowHunt CLI Toolkit je open-source a dostupný na GitHube na adrese https://github.com/yasha-dev1/flowhunt-toolkit. Môžete si ho naklonovať, prispievať doň a voľne používať na hodnotenie AI workflowov.
Toolkit generuje podrobné reporty vrátane rozboru správnych/nesprávnych výsledkov, hodnotení LLM ako sudcu s bodovaním a zdôvodnením, metrík výkonu a detailnej analýzy správania workflowov pri rôznych testovacích prípadoch.
Áno! Workflow LLM ako sudca je vytvorený pomocou platformy FlowHunt a dá sa prispôsobiť rôznym hodnotiacim scenárom. Môžete upraviť šablónu promptu a kritériá hodnotenia podľa vlastných potrieb.
Yasha je talentovaný softvérový vývojár so špecializáciou na Python, Javu a strojové učenie. Yasha píše technické články o AI, prompt engineeringu a vývoji chatbotov.

Vytvárajte a hodnotte sofistikované AI workflowy na platforme FlowHunt. Začnite tvoriť workflowy, ktoré dokážu hodnotiť iné workflowy už dnes.
Toky sú mozgom celého FlowHunt. Naučte sa ich vytvárať pomocou vizuálneho tvorcu bez kódovania – od umiestnenia prvého komponentu cez integráciu na webstránku, ...

Tento článok vysvetľuje, ako prepojiť FlowHunt s Langfuse pre komplexnú observabilitu, sledovať výkon AI workflowov a využívať Langfuse dashboardy na monitoring...
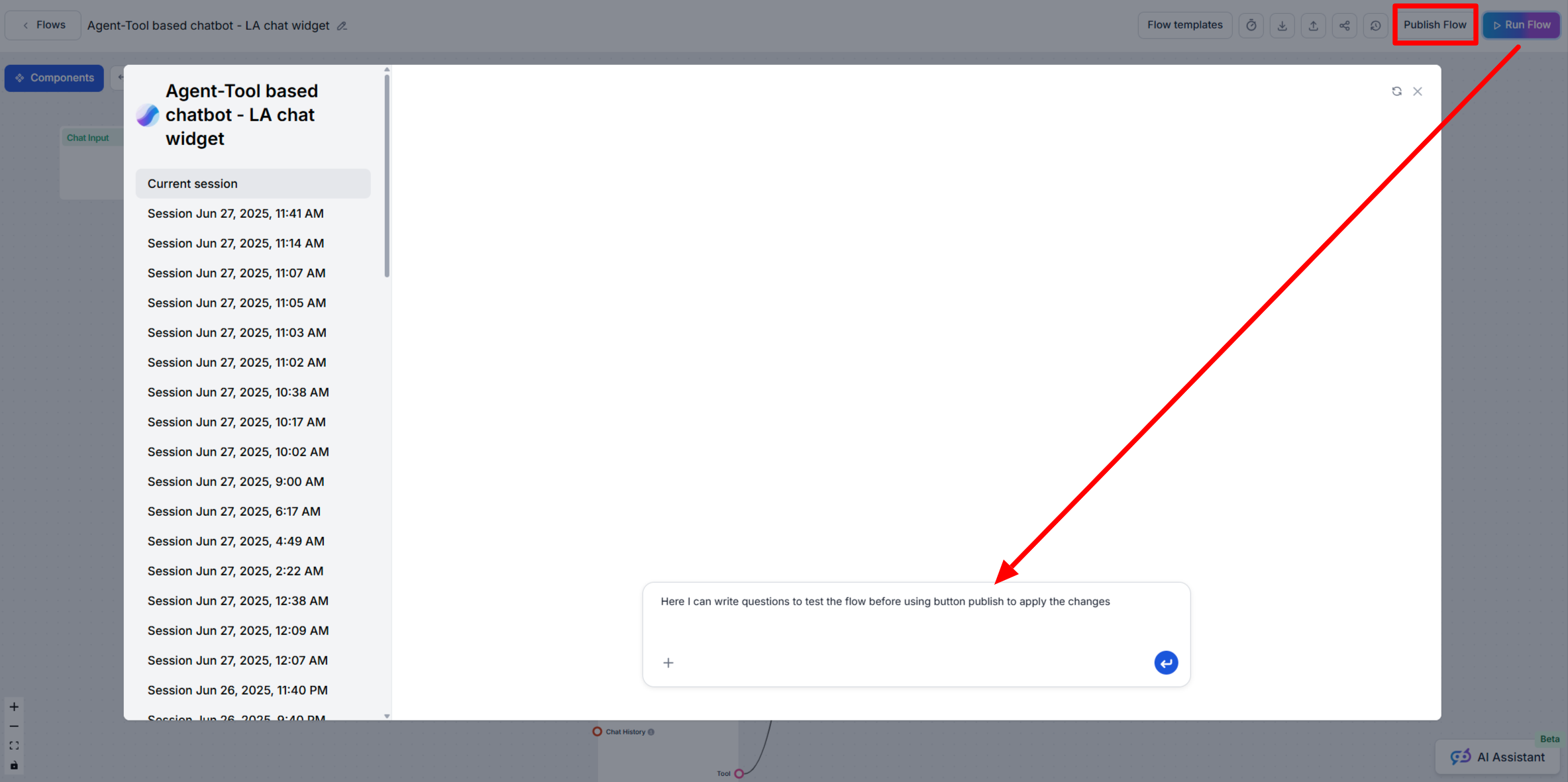
Zistite, kedy použiť funkcie Spustiť Flow a Publikovať Flow v FlowHunt AIStudio na bezpečné testovanie a nasadenie vašich AI workflowov.