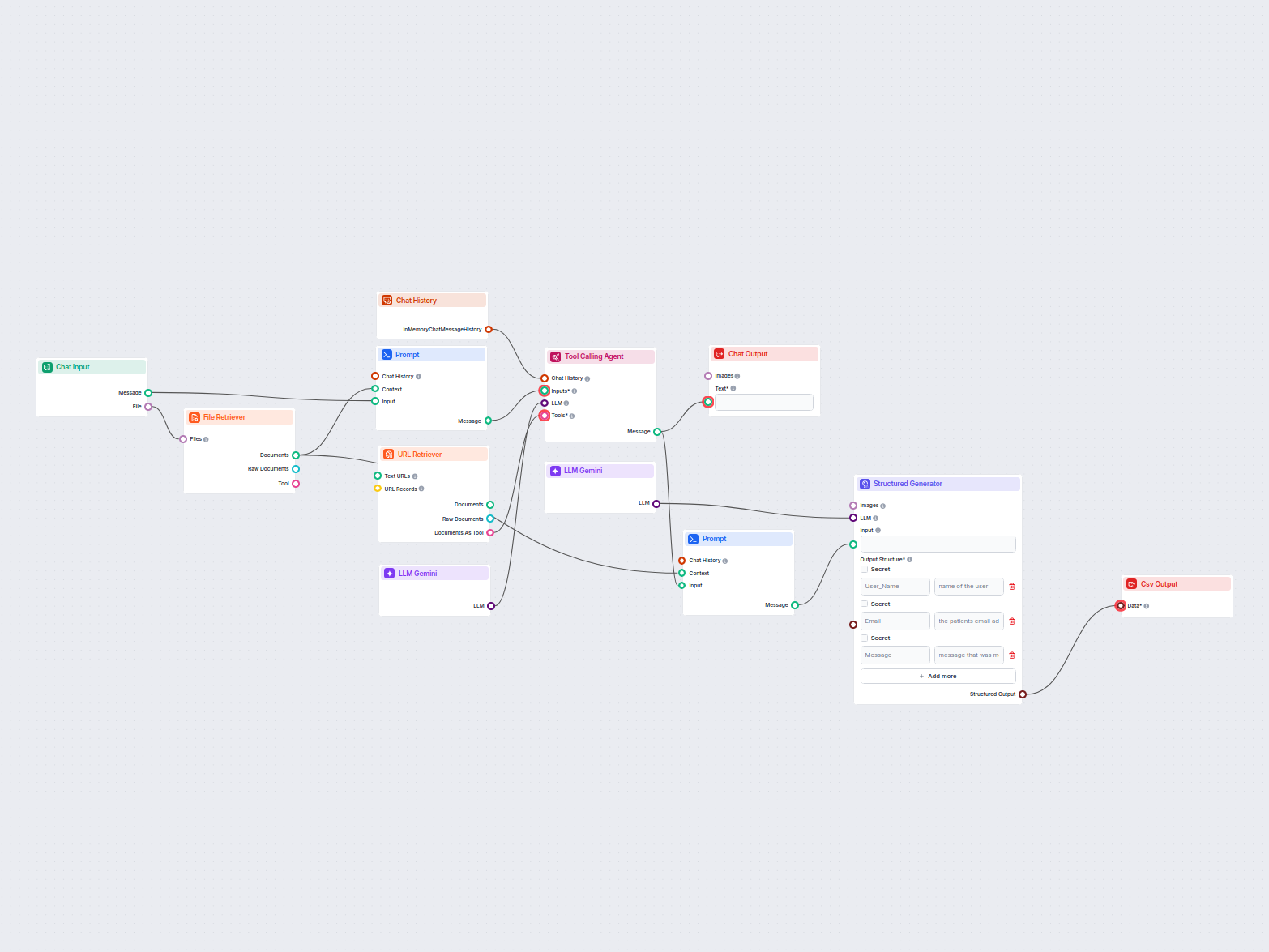
Extrahovanie údajov z e-mailov a súborov do CSV
Tento pracovný postup extrahuje a organizuje kľúčové informácie z e-mailov a priložených súborov, využíva AI na spracovanie a štruktúrovanie dát a výsledky expo...
3 min čítania
Aby sme vám pomohli rýchlo začať, pripravili sme niekoľko ukážkových flow šablón, ktoré demonštrujú efektívne využitie komponentu Urlcontent. Tieto šablóny prezentujú rôzne prípady použitia a osvedčené postupy, čo vám uľahčí pochopenie a implementáciu komponentu vo vašich vlastných projektoch.
Tento pracovný postup extrahuje a organizuje kľúčové informácie z e-mailov a priložených súborov, využíva AI na spracovanie a štruktúrovanie dát a výsledky expo...
Pomáhame firmám, ako je tá vaša, vyvíjať inteligentné chatbota, servery MCP, AI nástroje alebo iné typy AI automatizácie na nahradenie ľudí pri opakujúcich sa úlohách vo vašej organizácii.