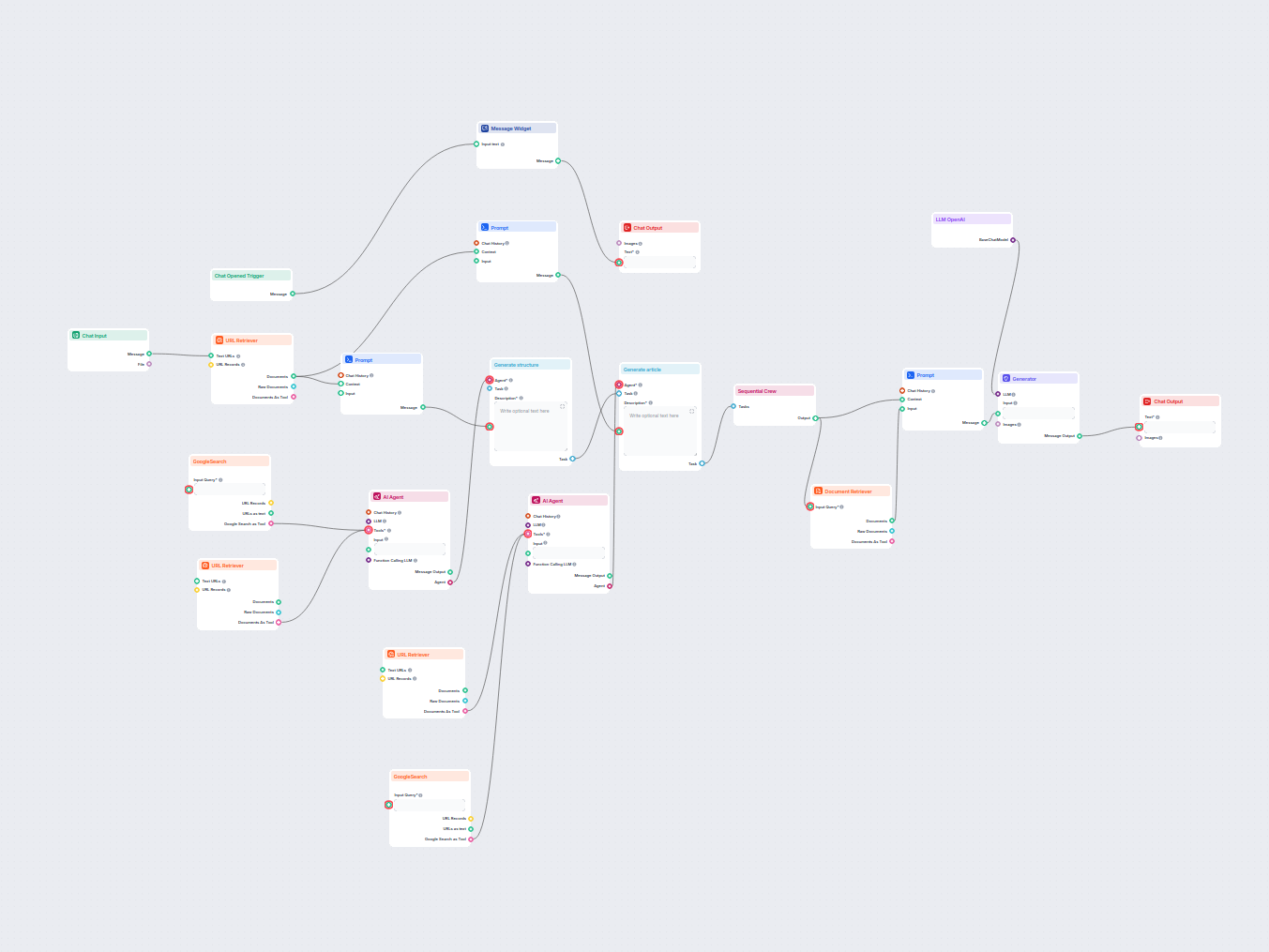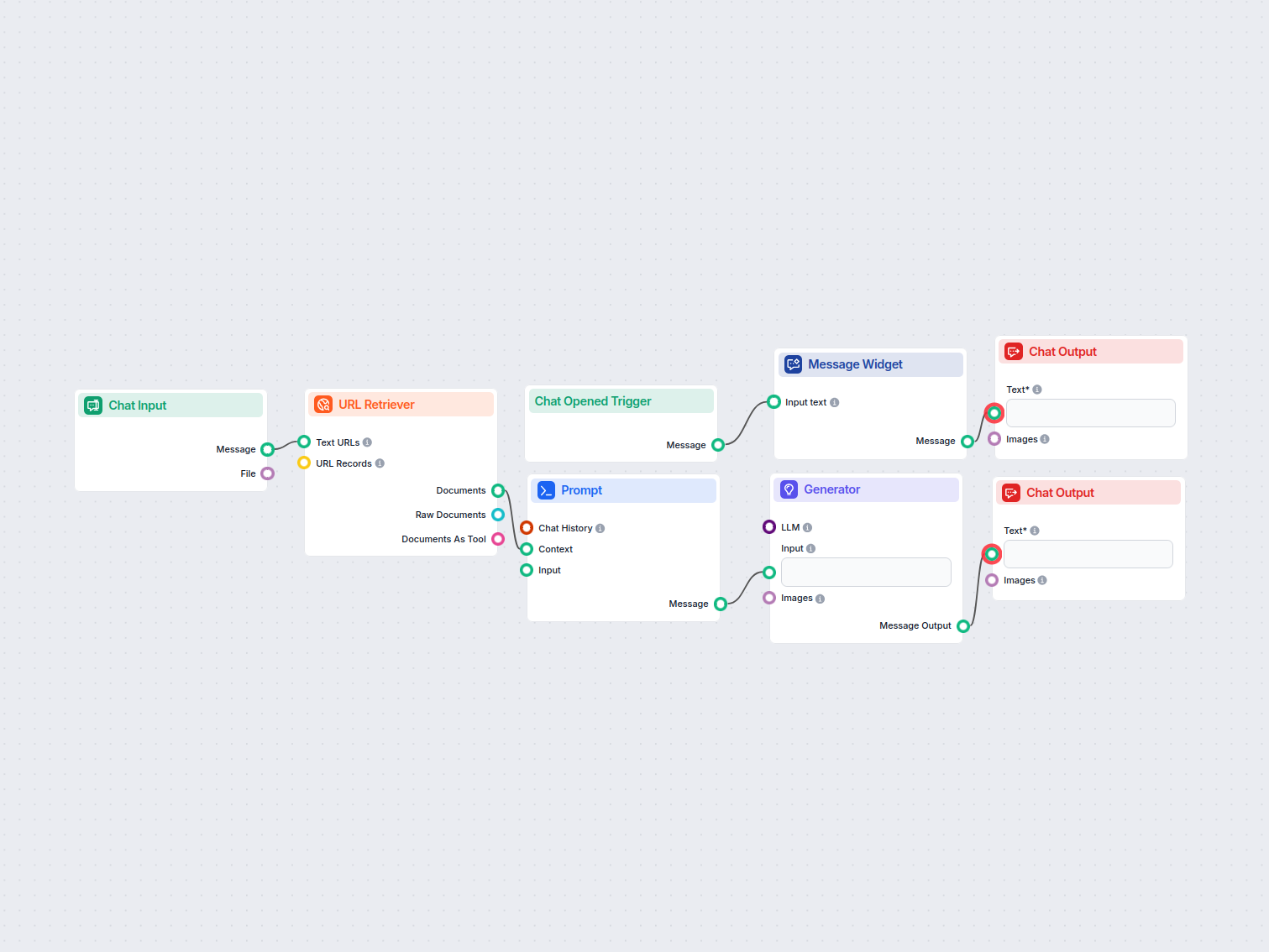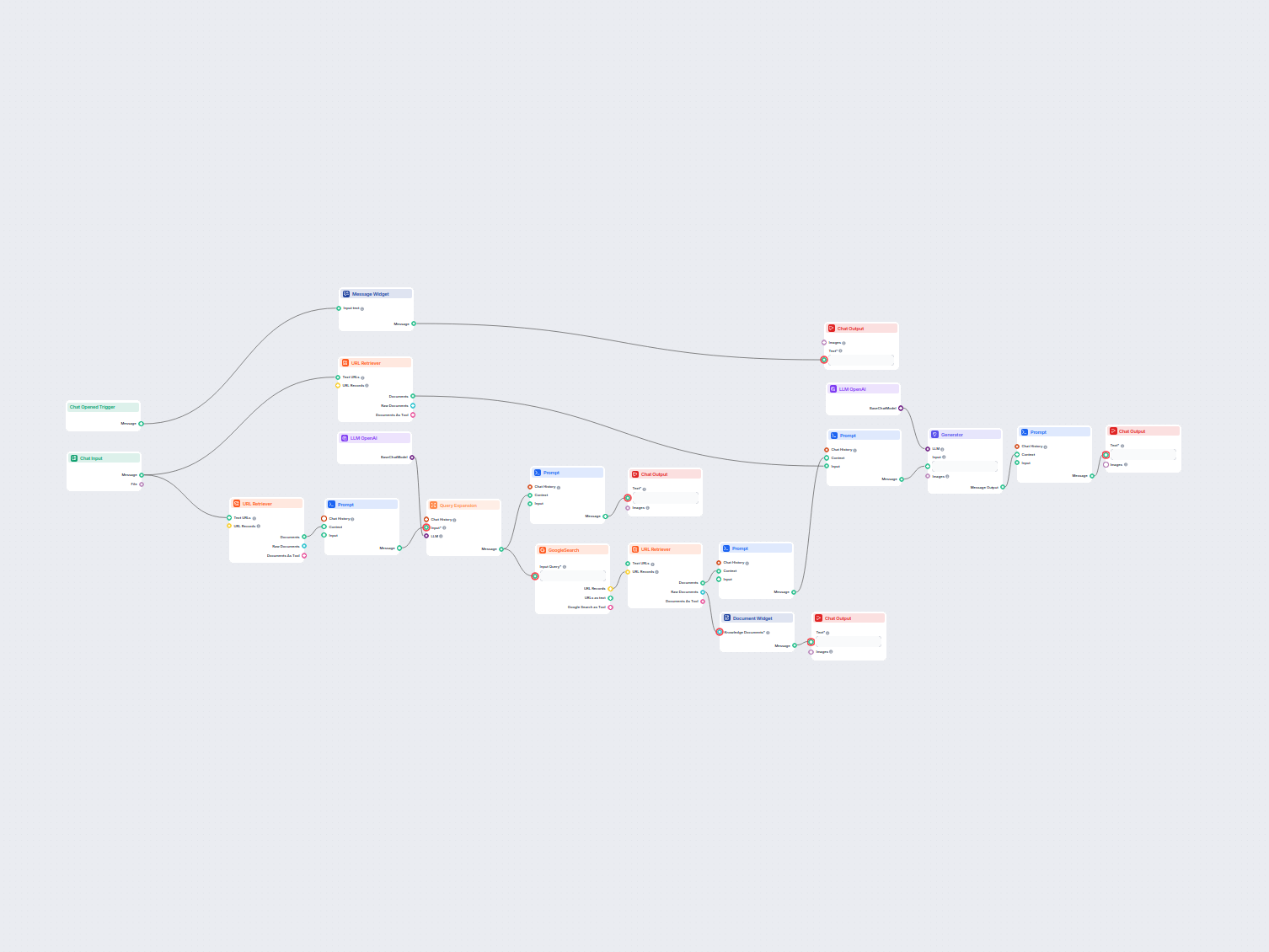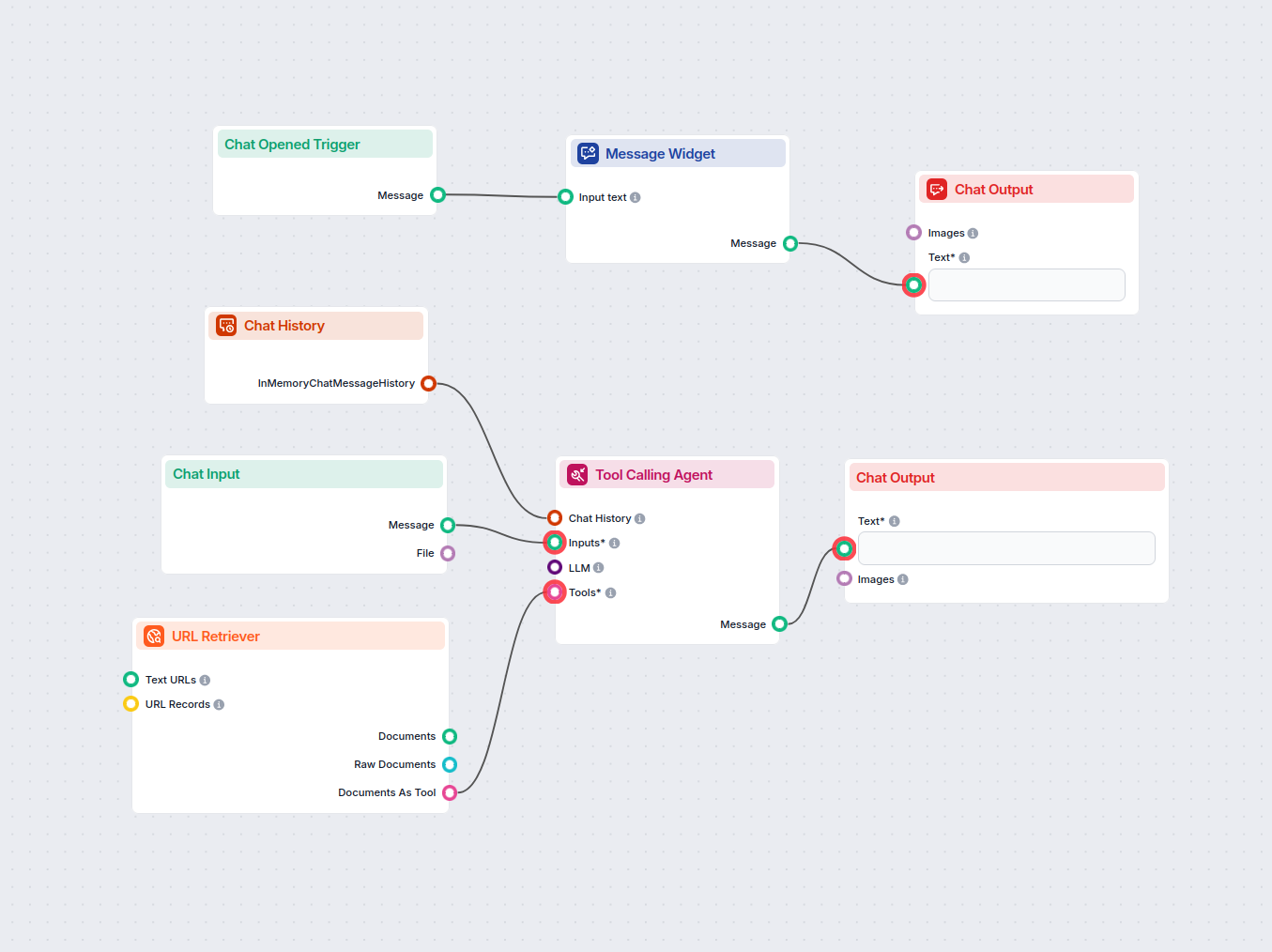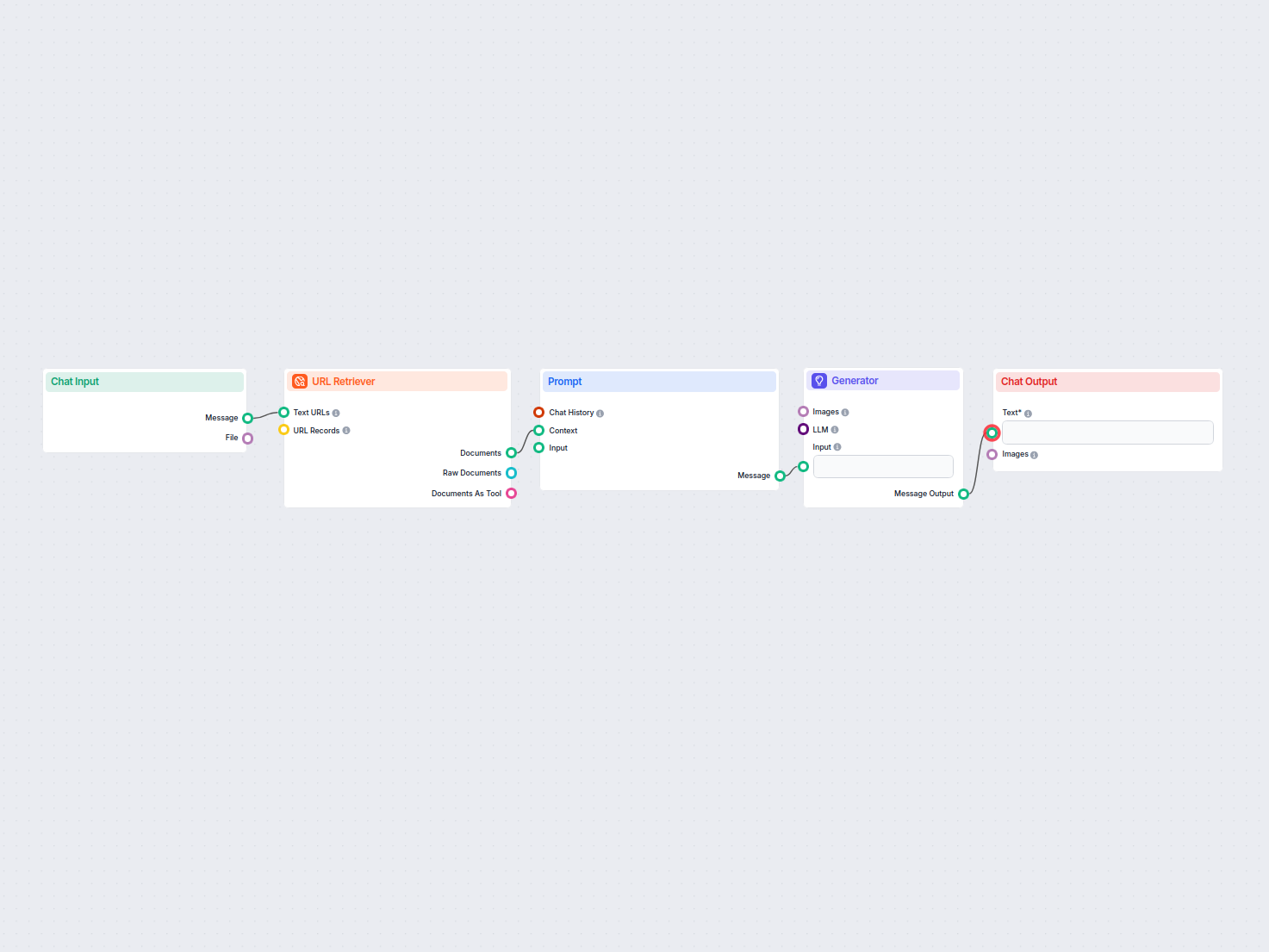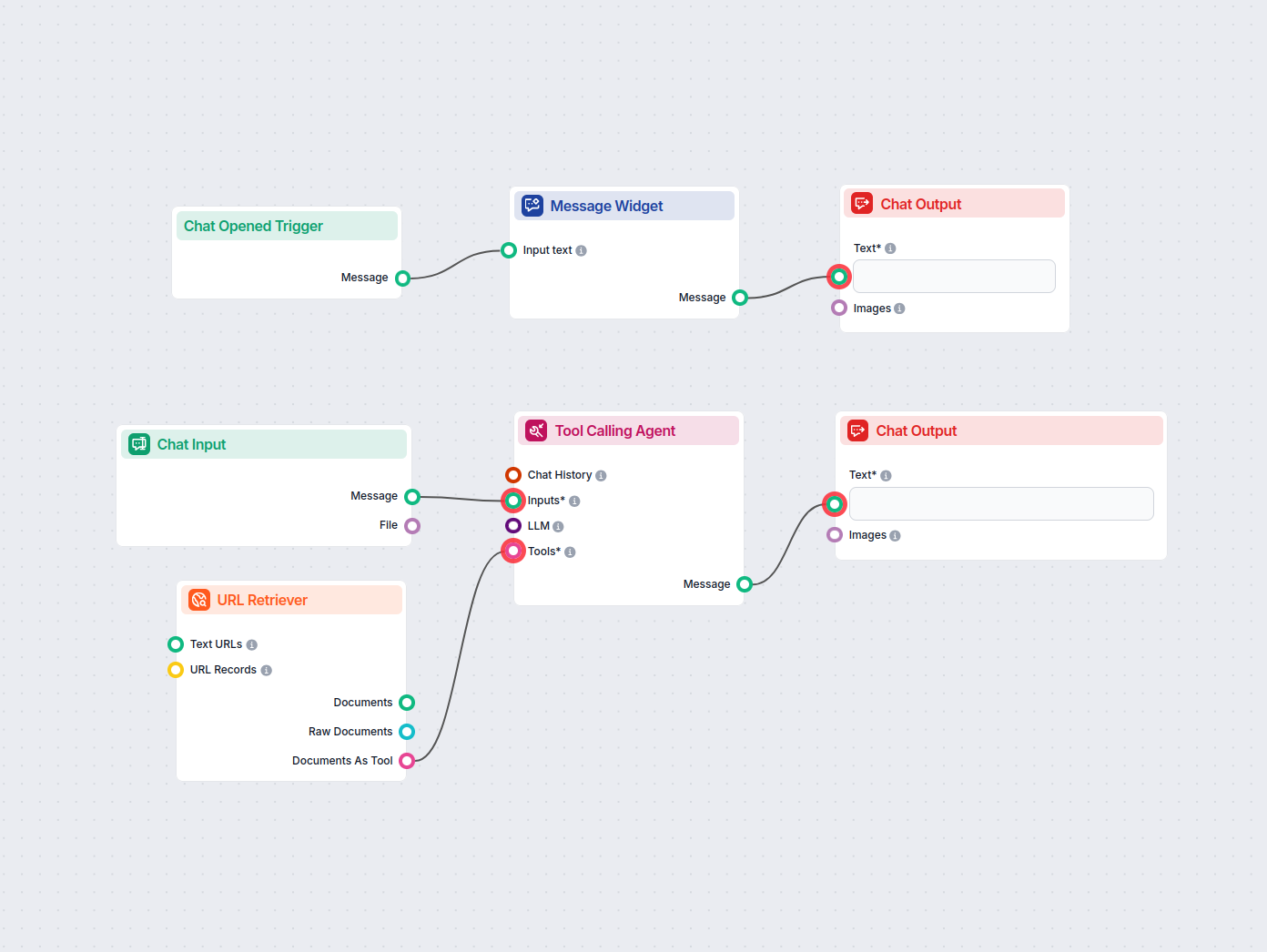
Konvertor Sitemap na llms.txt AI
Premeňte akýkoľvek sitemap.xml na dobre štruktúrovaný formát llms.txt pomocou AI. Tento workflow načíta URL adresy zo sitemapu, získa a spracuje ich obsah a vyu...
4 min čítania
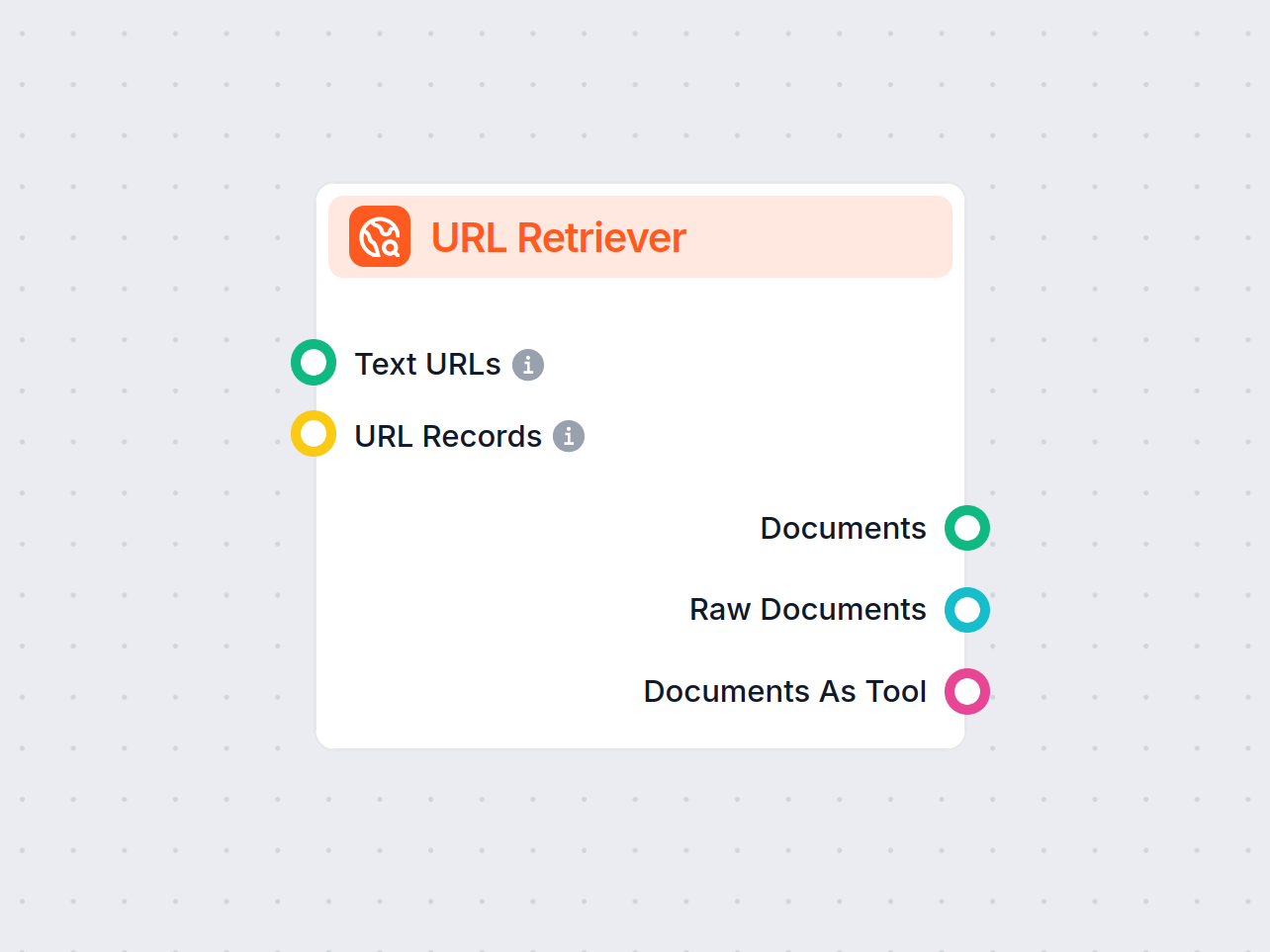
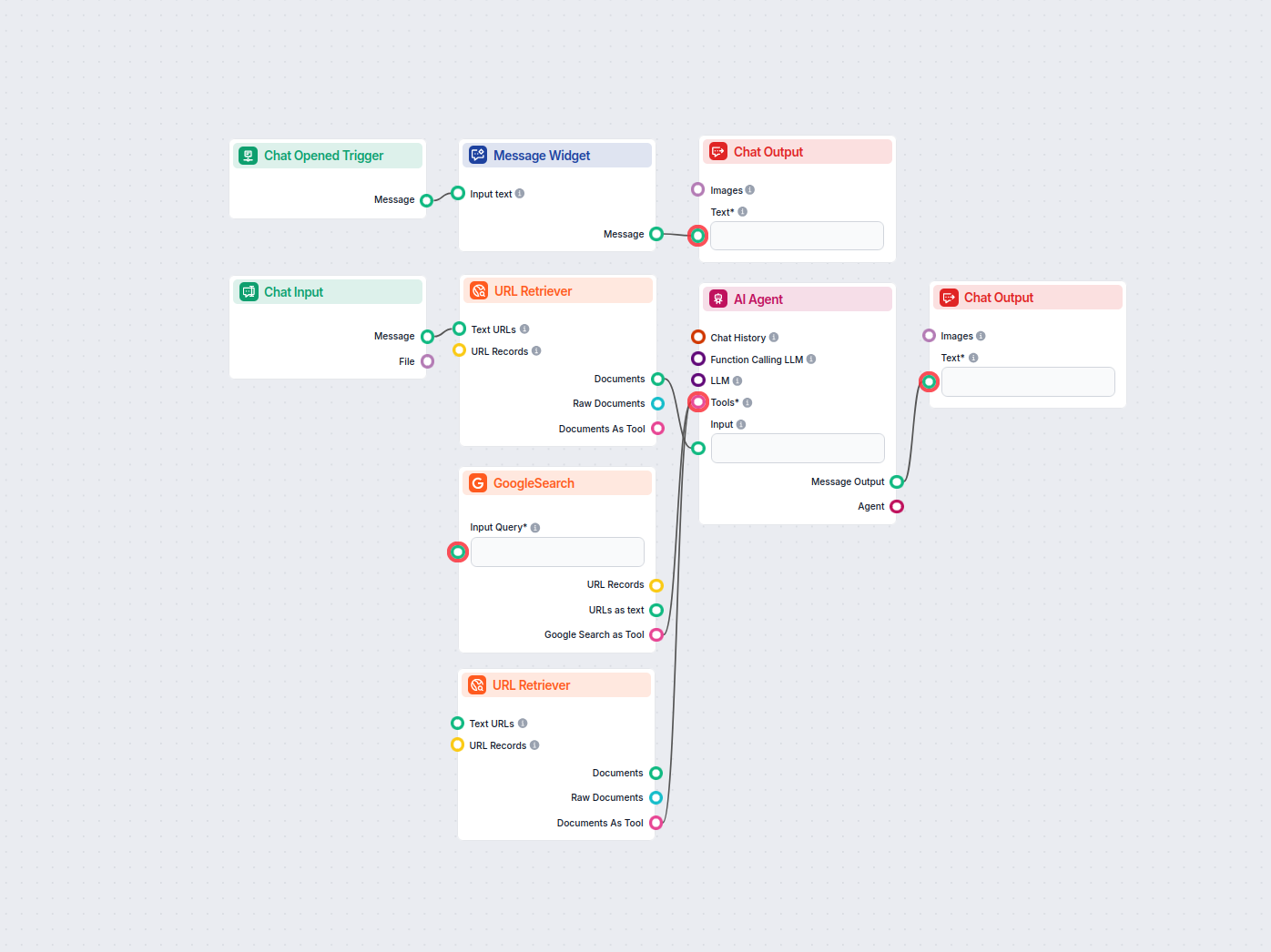
URL Retriever vám umožňuje získavať a spracovávať obsah z webových odkazov, s podporou OCR, extrakcie metaúdajov a flexibilného výstupu pre poháňanie AI pracovných tokov.
Opis komponentu
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Aby sme vám pomohli rýchlo začať, pripravili sme niekoľko ukážkových flow šablón, ktoré demonštrujú efektívne využitie komponentu URL Retriever. Tieto šablóny prezentujú rôzne prípady použitia a osvedčené postupy, čo vám uľahčí pochopenie a implementáciu komponentu vo vašich vlastných projektoch.
Premeňte akýkoľvek sitemap.xml na dobre štruktúrovaný formát llms.txt pomocou AI. Tento workflow načíta URL adresy zo sitemapu, získa a spracuje ich obsah a vyu...
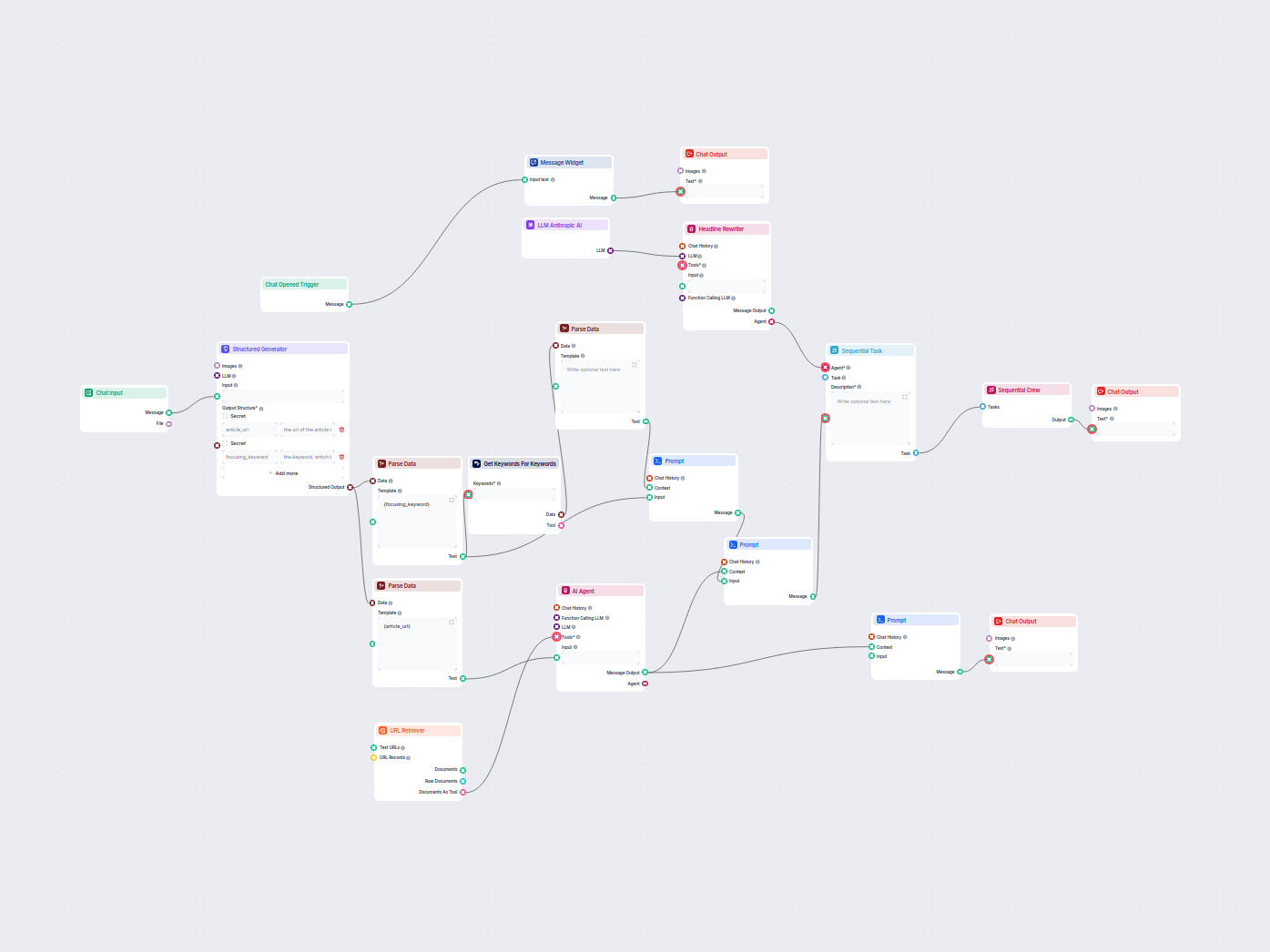
Premeňte technickú dokumentáciu z URL na pútavý, SEO optimalizovaný článok pre váš web. Tento flow analyzuje obsah najlepších konkurentov, vytvára štruktúrovanú...
Automaticky optimalizujte nadpisy a titulok vášho článku pre konkrétne kľúčové slovo alebo klaster kľúčových slov s cieľom zlepšiť SEO výkonnosť. Tento pracovný...
Tento AI workflow vyhľadáva najlepšie SEO kľúčové slová pre váš blogový článok a automaticky prepisuje titulky tak, aby cielili na tieto kľúčové slová, čím zlep...
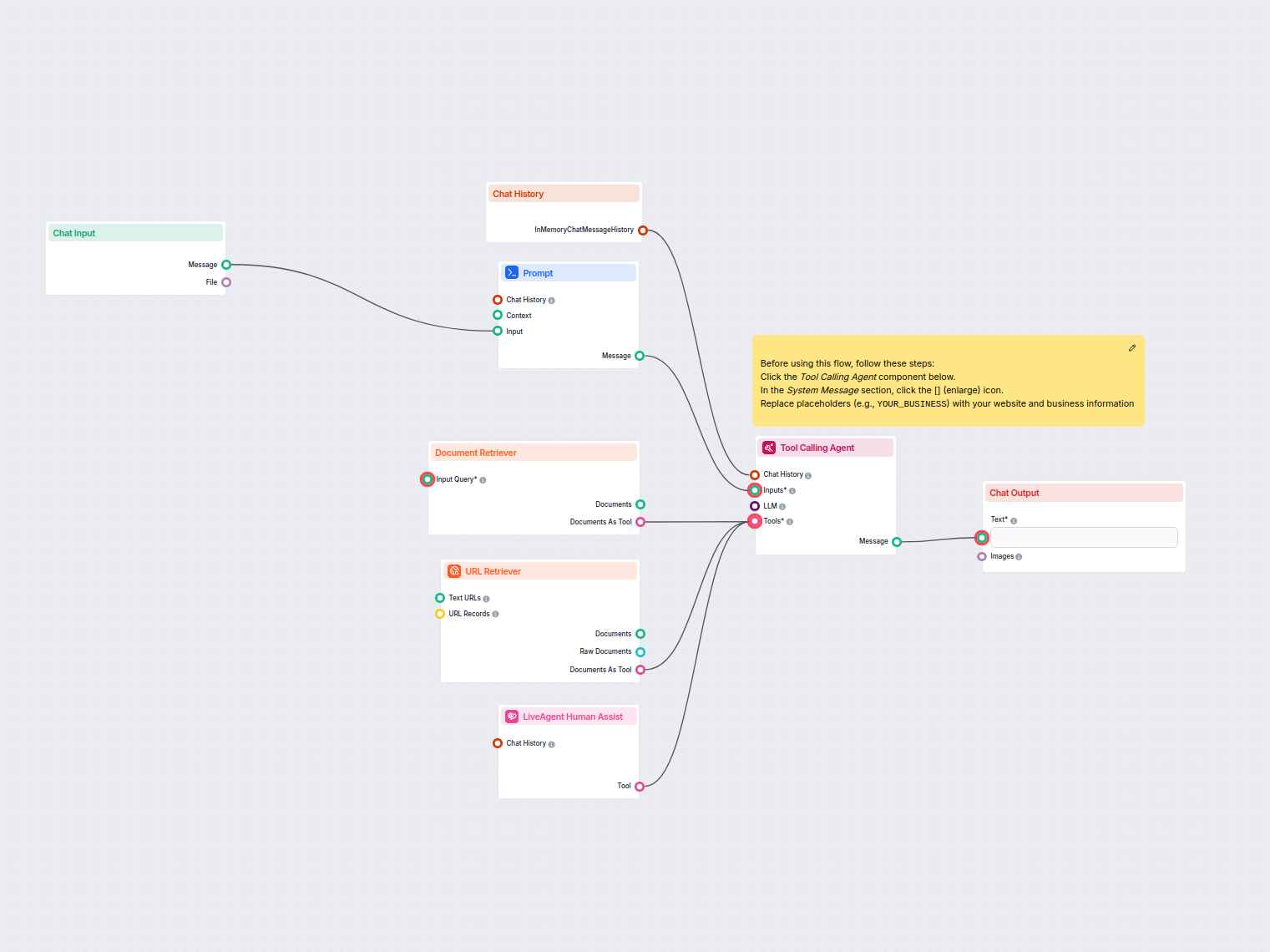
Automatizujte zákaznícku podporu v LiveAgent s AI chatbotom, ktorý odpovedá na otázky pomocou vašej internej znalostnej bázy, vyhľadáva relevantné dokumenty a v...
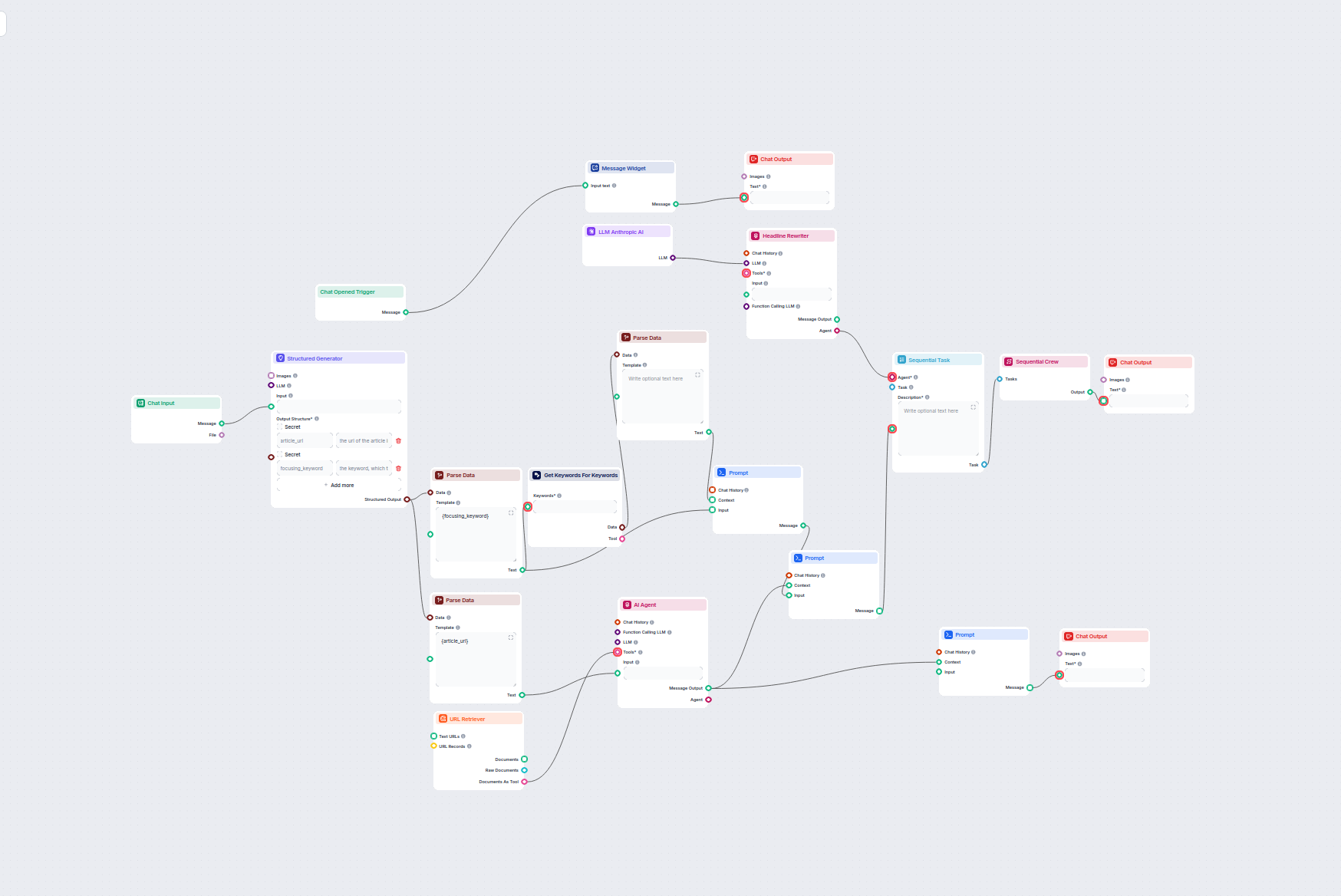
Generujte komplexné, SEO-optimalizované blogové príspevky s pokročilou štruktúrou a vysokým počtom slov pomocou viacerých AI agentov. Pracovný postup zahŕňa aut...
Automaticky premení obsah ľubovoľnej zadanej URL na stručný, pútavý príspevok vhodný pre X (Twitter), čo pomáha marketérom a tvorcom rýchlo zvýšiť svoju prítomn...
Tento pracovný postup poháňaný umelou inteligenciou analyzuje štruktúru obsahu vašej webovej stránky, porovnáva ju s najlepšie hodnotenými konkurenčnými stránka...
Automaticky generujte profesionálne pitch decky v Google Slides pomocou AI a živého webového výskumu. Tento pracovný postup zhromažďuje vstupy od používateľa, v...
Tento pracovný postup poháňaný AI vylepšuje popisy produktov pre Shopify na základe názvu produktu alebo URL, ktoré zadá používateľ. Využíva LLM, získava obsah ...
Interagujte s akýmkoľvek YouTube videom prostredníctvom rozhovoru s jeho prepisom. Okamžite extrahujte a vyhľadávajte obsah videa, aby ste získali stručné odpov...
Automaticky vytvára pútavý, SEO-friendly meta popis pre akúkoľvek webovú stránku, PDF, YouTube video alebo odkaz na dokument analýzou jeho obsahu a generovaním ...
Rýchlo vygenerujte stručné zhrnutia akejkoľvek webovej stránky jednoducho zadaním URL. Tento AI-poháňaný pracovný postup získa obsah z poskytnutého odkazu a vyt...
Zobrazené 61 až 73 z 73 výsledkov
URL Retriever získava a spracováva obsah zo zadaných webových odkazov, čím sprístupňuje text a metaúdaje z online dokumentov pre váš pracovný tok alebo AI agenta.
Áno, po zapnutí voľby OCR dokáže komponent extrahovať text z obrázkových dokumentov alebo skenovaných PDF.
Výstupy sú spracované dokumenty ako textové správy, surové objekty dokumentov alebo ako nástroj pre pracovné toky agentov, podľa vášho nastavenia.
Môžete nastaviť, ako dlho sa získaný obsah ukladá do vyrovnávacej pamäte, čím sa zníži opakované sťahovanie a zrýchli vaše toky.
Áno, môžete určiť, ktoré nadpisy, odseky alebo metaúdaje sa majú zahrnúť do výstupu, čo umožňuje cielenú extrakciu.
Určite. URL Retriever je nevyhnutný pre akúkoľvek automatizáciu alebo chatbota, ktorý potrebuje čítať, spracovávať alebo sumarizovať živý webový obsah.
Zvýšte výkon svojich pracovných tokov integráciou živého webového obsahu. Extrahujte, spracovávajte a využívajte dáta z URL jednoducho.
Integrujte svoje pracovné postupy s Google Docs pomocou komponentu Google Docs Retriever—jednoducho načítajte obsah dokumentov na použitie v automatizáciách, ch...
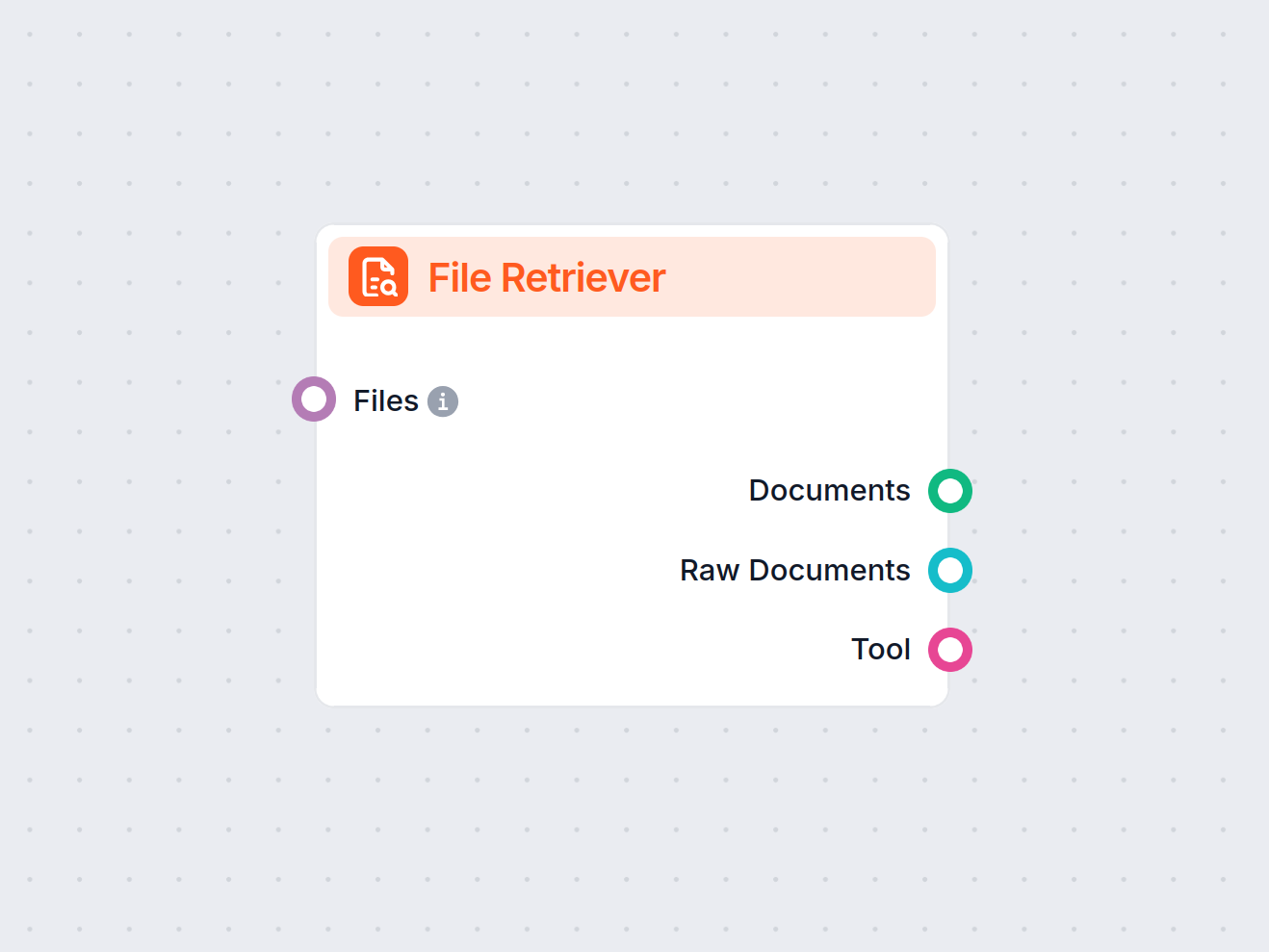
Komponent Vyhľadávač súborov vo FlowHunt vám umožňuje priniesť súbory do vášho pracovného toku a konvertovať ich na dokumenty na ďalšie spracovanie. Podporuje s...
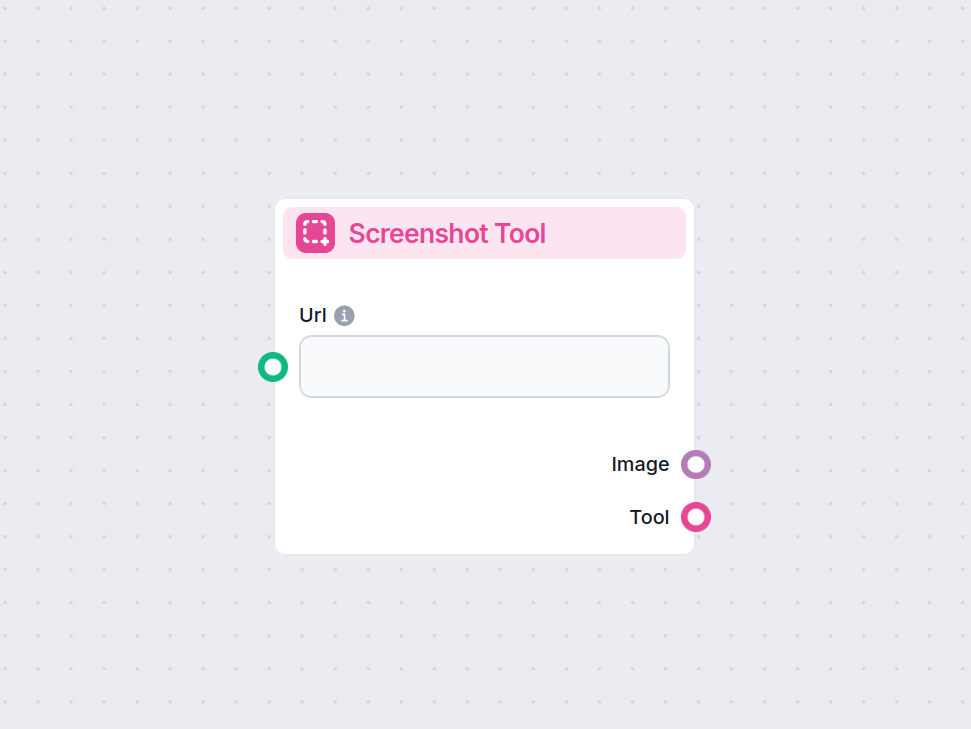
Zachytávajte snímky webových stránok okamžite pomocou komponentu Screenshot Tool. Jednoducho automatizujte vytváranie snímok ľubovoľnej URL adresy vo vašom prac...