Integrácia Neo4j MCP Servera
Neo4j MCP Server prepája AI asistentov s grafovou databázou Neo4j a umožňuje bezpečné, prirodzeným jazykom riadené operácie s grafmi, dopyty Cypher a automatizo...
4 min čítania
AI
Graph Database
+5
Neo4j MCP Server prepája AI asistentov s grafovou databázou Neo4j a umožňuje bezpečné, prirodzeným jazykom riadené operácie s grafmi, dopyty Cypher a automatizo...
NASA MCP Server poskytuje jednotné rozhranie pre AI modely a vývojárov na prístup k viac než 20 NASA dátovým zdrojom. Štandardizuje získavanie, spracovanie a sp...
MCP Code Executor MCP Server umožňuje FlowHunt a ďalším nástrojom poháňaným LLM bezpečne vykonávať Python kód v izolovaných prostrediach, spravovať závislosti a...
Server Data Exploration MCP Server prepája AI asistentov s externými dátovými súbormi pre interaktívnu analýzu. Umožňuje používateľom skúmať CSV a Kaggle datase...
Reexpress MCP Server prináša štatistické overovanie do LLM workflowov. Pomocou odhadovača Similarity-Distance-Magnitude (SDM) poskytuje robustné odhady dôveryho...
Databricks Genie MCP Server umožňuje veľkým jazykovým modelom interagovať s prostrediami Databricks cez Genie API, podporuje konverzačné skúmanie dát, automatiz...
JupyterMCP umožňuje bezproblémovú integráciu Jupyter Notebooku (6.x) s AI asistentmi prostredníctvom Model Context Protocol. Automatizujte spúšťanie kódu, sprav...
AI dátový analytik synergizuje tradičné zručnosti v oblasti dátovej analýzy s umelou inteligenciou (AI) a strojovým učením (ML), aby získal poznatky, predpoveda...
BigML je platforma strojového učenia navrhnutá na zjednodušenie tvorby a nasadenia prediktívnych modelov. Bola založená v roku 2011 a jej poslaním je sprístupni...
Čistenie dát je kľúčový proces detekcie a opravy chýb alebo nezrovnalostí v dátach s cieľom zvýšiť ich kvalitu a zabezpečiť presnosť, konzistentnosť a spoľahliv...
Dátová ťažba je sofistikovaný proces analýzy veľkých množín surových údajov s cieľom odhaliť vzory, vzťahy a poznatky, ktoré môžu ovplyvniť obchodné stratégie a...
Google Colaboratory (Google Colab) je cloudová platforma Jupyter notebookov od spoločnosti Google, ktorá umožňuje používateľom písať a spúšťať Python kód v preh...
Gradient Boosting je výkonná ensemble technika strojového učenia pre regresiu a klasifikáciu. Modely buduje sekvenčne, typicky pomocou rozhodovacích stromov, ab...
Preskúmajte, ako inžinierstvo a extrakcia príznakov zlepšujú výkon AI modelov transformáciou surových dát na cenné poznatky. Objavte kľúčové techniky ako tvorba...
Jupyter Notebook je open-source webová aplikácia, ktorá umožňuje používateľom vytvárať a zdieľať dokumenty so živým kódom, rovnicami, vizualizáciami a popisným ...
K-Means zhlukovanie je populárny algoritmus neřízeného strojového učenia na rozdelenie dátových súborov do vopred stanoveného počtu odlišných, neprekrývajúcich ...
Algoritmus k-najbližších susedov (KNN) je neparametrický, supervidovaný učebný algoritmus používaný na klasifikáciu a regresiu v strojovom učení. Predpovedá výs...
Kaggle je online komunita a platforma pre dátových vedcov a strojových inžinierov, kde môžu spolupracovať, učiť sa, súťažiť a zdieľať poznatky. Kaggle, ktoré v ...
Kauzálna inferencia je metodologický prístup používaný na určovanie príčinných vzťahov medzi premennými, ktorý je kľúčový vo vede na pochopenie kauzálnych mecha...
AI klasifikátor je algoritmus strojového učenia, ktorý priraďuje vstupným údajom triedy, čím kategorizuje informácie do vopred definovaných tried na základe nau...
Anaconda je komplexná, open-source distribúcia Pythonu a R, navrhnutá na zjednodušenie správy balíkov a nasadzovania pre vedecké výpočty, dátovú vedu a strojové...
Lineárna regresia je základná analytická technika v štatistike a strojovom učení, ktorá modeluje vzťah medzi závislými a nezávislými premennými. Je známa svojou...
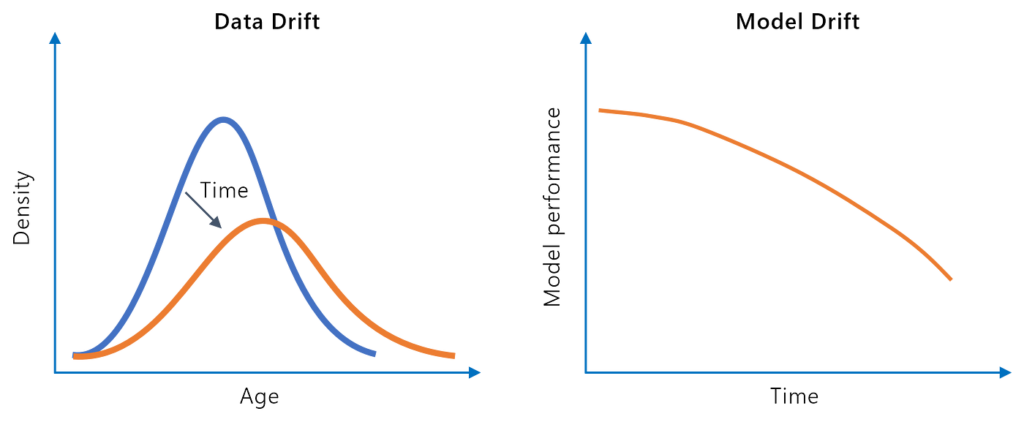
Model drift, alebo úpadok modelu, označuje pokles prediktívnej výkonnosti modelu strojového učenia v priebehu času v dôsledku zmien v reálnom svete. Zistite via...
NumPy je open-source knižnica pre Python, ktorá je kľúčová pre numerické výpočty, poskytuje efektívne operácie s poľami a matematické funkcie. Je základom vedec...
Pandas je open-source knižnica pre manipuláciu a analýzu dát v Pythone, známa svojou univerzálnosťou, robustnými dátovými štruktúrami a jednoduchosťou používani...
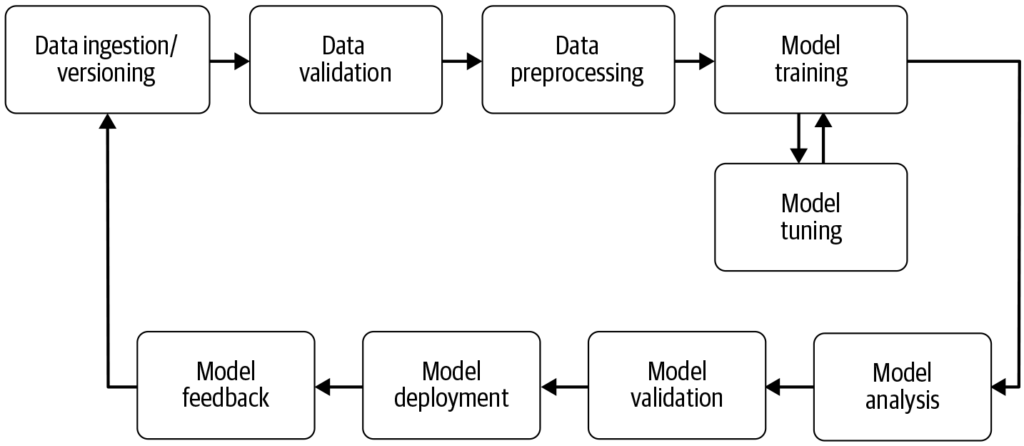
Pipeline strojového učenia je automatizovaný pracovný postup, ktorý zefektívňuje a štandardizuje vývoj, trénovanie, vyhodnocovanie a nasadenie modelov strojovéh...
Plocha pod krivkou (AUC) je základná metrika v strojovom učení, ktorá sa používa na hodnotenie výkonnosti binárnych klasifikačných modelov. Kvantifikuje celkovú...
Polonadzorované učenie (SSL) je technika strojového učenia, ktorá využíva označené aj neoznačené dáta na trénovanie modelov, čo je ideálne v prípadoch, keď je o...
Prediktívne modelovanie je sofistikovaný proces v dátovej vede a štatistike, ktorý predpovedá budúce výsledky analýzou vzorcov z historických dát. Využíva štati...
Redukcia dimenzií je kľúčová technika v spracovaní dát a strojovom učení, ktorá znižuje počet vstupných premenných v datasete pri zachovaní podstatných informác...
Reťazenie modelov je technika strojového učenia, pri ktorej sú viaceré modely navzájom prepojené sekvenčne, pričom výstup jedného modelu slúži ako vstup pre nas...
Rozhodovací strom je výkonný a intuitívny nástroj na rozhodovanie a prediktívnu analýzu, používaný pri klasifikačných aj regresných úlohách. Jeho stromová štruk...
Scikit-learn je výkonná open-source knižnica strojového učenia pre Python, poskytujúca jednoduché a efektívne nástroje na prediktívnu analýzu dát. Je široko vyu...
Upravené R-kvadrát je štatistická miera používaná na hodnotenie kvality prispôsobenia regresného modelu, pričom zohľadňuje počet prediktorov, aby sa predišlo pr...
Preskúmajte zaujatosti v AI: pochopte ich zdroje, vplyv na strojové učenie, príklady z praxe a stratégie na ich zmiernenie pre vytváranie spravodlivých a spoľah...