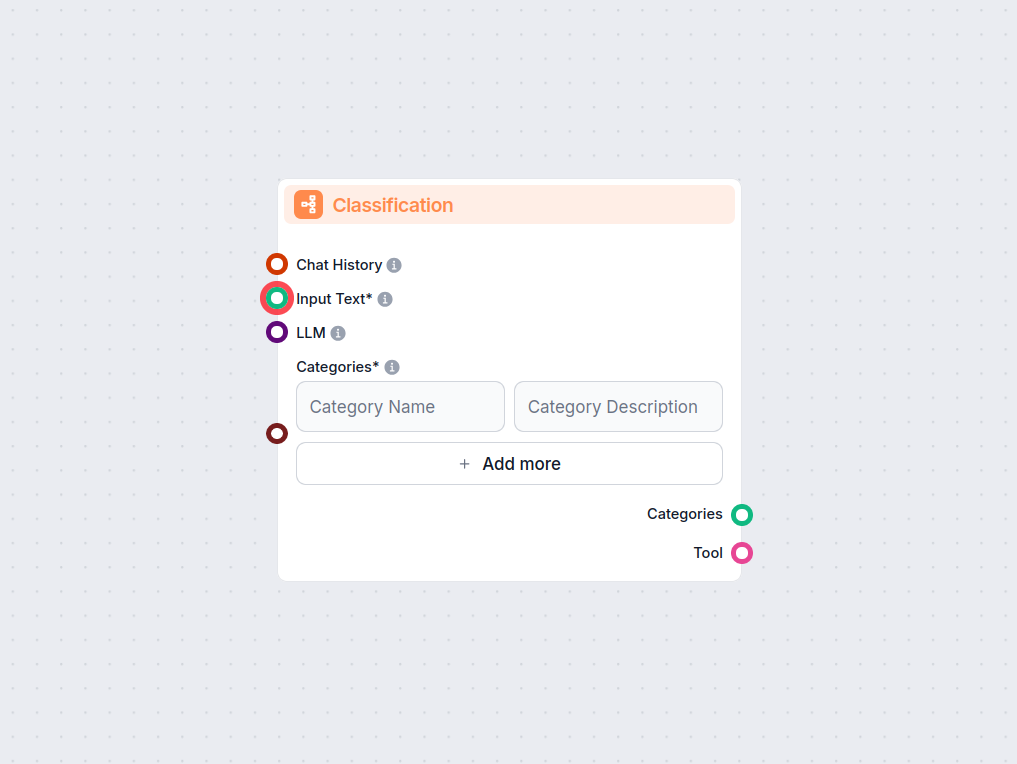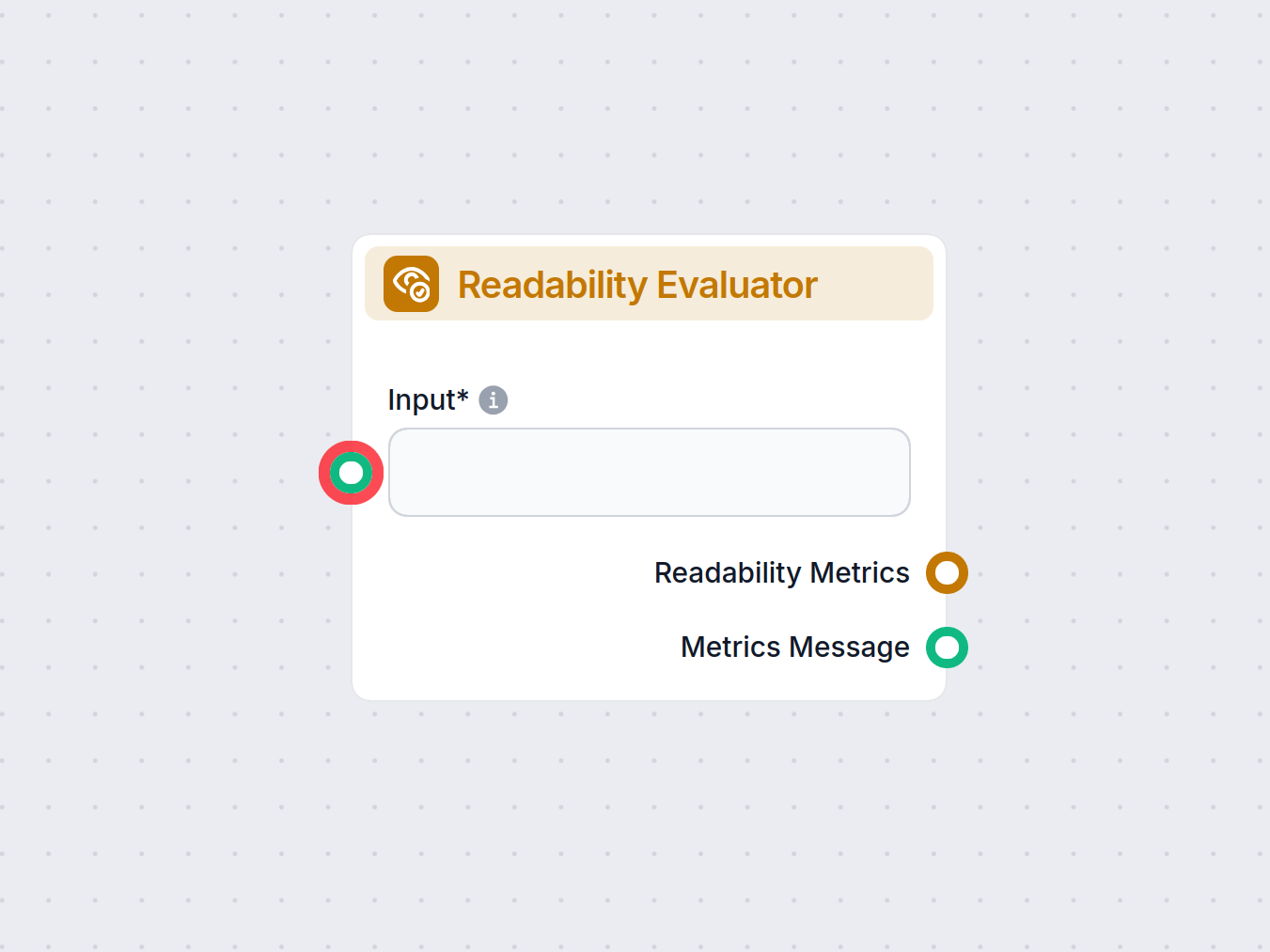
Hodnotiteľ čitateľnosti
Posúďte čitateľnosť akéhokoľvek textu vo vašom pracovnom postupe pomocou komponentu Hodnotiteľ čitateľnosti. Okamžite analyzujte vstup s využitím overených metr...
3 min čítania
AI
Automation
+4
Posúďte čitateľnosť akéhokoľvek textu vo vašom pracovnom postupe pomocou komponentu Hodnotiteľ čitateľnosti. Okamžite analyzujte vstup s využitím overených metr...
Odomknite automatizované triedenie textu vo vašich workflowoch s komponentom Klasifikácia textu pre FlowHunt. Jednoducho klasifikujte vstupný text do užívateľom...
Objavte dôležitosť hodnotiteľa čitateľnosti z textu pri posudzovaní zložitosti textu a zabezpečení vhodnosti obsahu pre rôzne cieľové skupiny. Preskúmajte nástr...
Vyskúšajte naše nástroje na hodnotenie čitateľnosti podľa Dale-Chall. Analyzujte obyčajný text, skontrolujte čitateľnosť z URL alebo generujte nový, ľahšie poch...
Natural Language Toolkit (NLTK) je komplexná sada knižníc a programov v Pythone pre symbolické a štatistické spracovanie prirodzeného jazyka (NLP). Široko použí...
Rozpoznávanie pomenovaných entít (NER) je kľúčová podoblasť spracovania prirodzeného jazyka (NLP) v AI, zameraná na identifikáciu a klasifikáciu entít v texte d...
spaCy je robustná open-source knižnica pre pokročilé spracovanie prirodzeného jazyka (NLP) v Pythone, známa svojou rýchlosťou, efektívnosťou a produkčnými funkc...
Spracovanie prirodzeného jazyka (NLP) je pododvetvie umelej inteligencie (AI), ktoré umožňuje počítačom porozumieť, interpretovať a generovať ľudský jazyk. Obja...
Tagovanie častí reči (POS tagging) je kľúčová úloha v počítačovej lingvistike a spracovaní prirodzeného jazyka (NLP). Zahŕňa priraďovanie každej slovnej jednotk...
Skontrolujte všetky priemyselné štandardy čitateľnosti. Vyskúšajte náš bezplatný nástroj na hodnotenie čitateľnosti a naučte sa, ako si vytvoriť vlastný!...
Závislostné parsovanie je metóda syntaktickej analýzy v NLP, ktorá identifikuje gramatické vzťahy medzi slovami a vytvára stromové štruktúry, ktoré sú nevyhnutn...