Textgenerering
Textgenerering med stora språkmodeller (LLMs) avser den avancerade användningen av maskininlärningsmodeller för att producera text som liknar mänskligt språk ut...
6 min läsning
AI
Text Generation
+5

FlowHunt testar och rankar ledande LLM:er—inklusive GPT-4, Claude 3, Llama 3 och Grok—för innehållsskrivande, och utvärderar läsbarhet, ton, originalitet och nyckelordsanvändning för att hjälpa dig välja den bästa modellen för dina behov.
Stora språkmodeller (LLM:er) är banbrytande AI-verktyg som förändrar hur vi skapar och konsumerar innehåll. Innan vi går djupare in på skillnaderna mellan olika LLM:er bör du förstå vad som gör att dessa modeller så enkelt kan skapa text som liknar mänsklig.
LLM:er tränas på enorma datamängder, vilket hjälper dem att förstå kontext, semantik och syntax. Beroende på mängden data kan de korrekt förutsäga nästa ord i en mening och sätta ihop orden till begriplig text. En anledning till deras effektivitet är transformer-arkitekturen. Denna självuppmärksamhetsmekanism använder neurala nätverk för att behandla texts syntax och semantik. Det innebär att LLM:er kan hantera ett brett spann av komplexa uppgifter med lätthet.
Stora språkmodeller (LLM:er) har förändrat sättet företag närmar sig innehållsskapande. Med sin förmåga att skapa personliga och optimerade texter genererar LLM:er innehåll som mejl, landningssidor och inlägg i sociala medier utifrån mänskliga språkprompter.
Här är vad LLM:er kan hjälpa innehållsskribenter med:
Dessutom ser framtiden för LLM:er ljus ut. Framsteg inom teknologin kommer sannolikt förbättra deras noggrannhet och multimodala möjligheter. Denna utvidgning av användningsområden kommer påverka flera branscher avsevärt.
Här är en snabb översikt över de populära LLM:er vi kommer att testa:
| Modell | Unika styrkor |
|---|---|
| GPT-4 | Mångsidig i olika skrivstilar |
| Claude 3 | Utmärker sig vid kreativa och kontextuella uppgifter |
| Llama 3.2 | Känd för effektiv textsammanfattning |
| Grok | Känd för avslappnad och humoristisk ton |
När du väljer en LLM är det viktigt att utgå från dina behov för innehållsskapande. Varje modell erbjuder något unikt, från att hantera komplexa uppgifter till att skapa AI-drivet kreativt innehåll. Innan vi testar dem, låt oss kort sammanfatta varje modell och se hur de kan gynna din process.
Nyckelfunktioner:
Prestandamått:
Styrkor:
Utmaningar:
Sammanfattningsvis är GPT-4 ett kraftfullt verktyg för företag som vill förbättra sitt innehållsskapande och sin dataanalys.
Nyckelfunktioner:
Styrkor:
Utmaningar:
Nyckelfunktioner:
Styrkor:
Utmaningar:
Llama 3 utmärker sig som en robust och mångsidig öppen LLM, med löften om AI-framsteg men även vissa utmaningar för användarna.
Nyckelfunktioner:
Styrkor:
Utmaningar:
Sammanfattningsvis erbjuder xAI Grok intressanta funktioner och har fördelen av medieexponering, men står inför stora utmaningar i fråga om popularitet och prestanda bland språkmodeller.
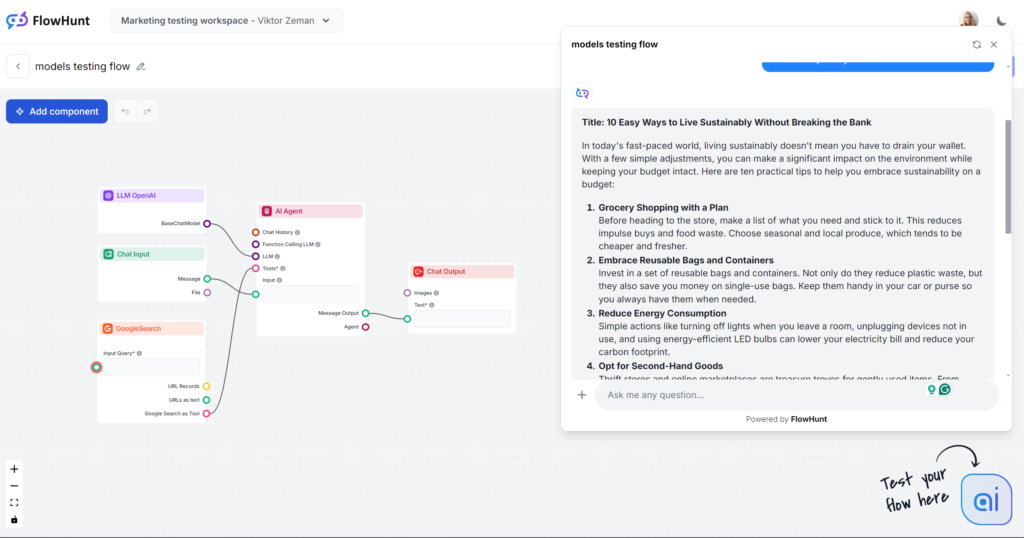
Nu hoppar vi direkt in i testerna. Vi rankar modellerna med hjälp av ett grundläggande bloggskrivande. Alla tester utfördes i FlowHunt, där endast LLM-modellen ändrades.
Fokusområden:
Testprompt:
Skriv ett blogginlägg med titeln “10 enkla sätt att leva hållbart utan att spräcka budgeten”. Tonen ska vara praktisk och lättillgänglig, med fokus på handfasta tips som är rimliga för upptagna personer. Lyft fram “hållbarhet på budget” som huvudnyckelord. Inkludera exempel för vardagssituationer som matinköp, energianvändning och personliga vanor. Avsluta med en uppmuntrande uppmaning till läsaren att testa ett tips redan idag.
Obs: Flödet är begränsat till en utdata på cirka 500 ord. Om utdata känns stressad eller ytlig är det avsiktligt.
Om detta vore ett blindtest skulle frasen “I dagens snabba värld…” avslöja modellen direkt. Du är troligen bekant med denna skribentstil, eftersom den inte bara är det populäraste valet utan även grunden för de flesta AI-skrivverktyg från tredje part. GPT-4o är alltid ett säkert val för allmänt innehåll, men var beredd på vaghet och ordrikedom.
Ton och språk
Ser man förbi den smärtsamt uttjatade inledningsmeningen gjorde GPT-4o precis vad vi förväntade oss. Ingen skulle tro att en människa skrivit detta, men det är ändå en hyfsat strukturerad artikel som tydligt följer prompten. Tonen är faktiskt praktisk och lättillgänglig, med direkt fokus på handfasta tips istället för vaga resonemang.
Nyckelordsanvändning
GPT-4o lyckades bra i testet för nyckelordsanvändning. Modellen använde inte bara det angivna nyckelordet utan även liknande fraser och andra relevanta ord.
Läsbarhet
På Flesch-Kincaid-skalan hamnar denna utdata på årskurs 10–12 (ganska svår) med poängen 51,2. Ett poäng lägre och den hade varit på universitetsnivå. Med så kort utdata påverkar kanske till och med ordet “hållbarhet” läsbarheten. Det finns ändå klart utrymme för förbättring.
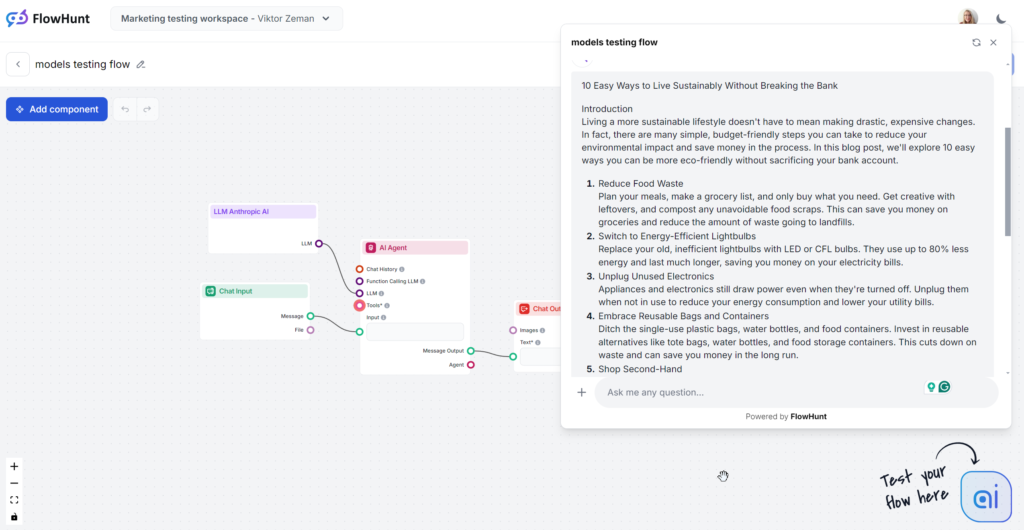
Den analyserade Claude-utdatan är mellanmodellen Sonnet, som sägs vara bäst för innehåll. Texten flyter bra och känns märkbart mer mänsklig än GPT-4o eller Llama. Claude är den perfekta lösningen för ren och enkel text som levererar information effektivt utan att bli för ordrik som GPT eller för “flashig” som Grok.
Ton och språk
Claude utmärker sig genom enkla, relaterbara och mänskliga svar. Tonen är praktisk och lättillgänglig, med direkt fokus på handfasta tips istället för vaga resonemang.
Nyckelordsanvändning
Claude var den enda modellen som ignorerade nyckelordsdelen av prompten och använde det bara i 1 av 3 utdata. När det användes dök det upp i slutsatsen och kändes något påklistrat.
Läsbarhet
Claude Sonnet fick höga poäng på Flesch-Kincaid-skalan, årskurs 8–9 (lätt engelska), bara några poäng bakom Grok. Grok ändrade hela ton och vokabulär för att nå detta, medan Claude använde liknande vokabulär som GPT-4o. Vad gjorde läsbarheten så bra? Kortare meningar, vardagliga ord och inget vagt innehåll.
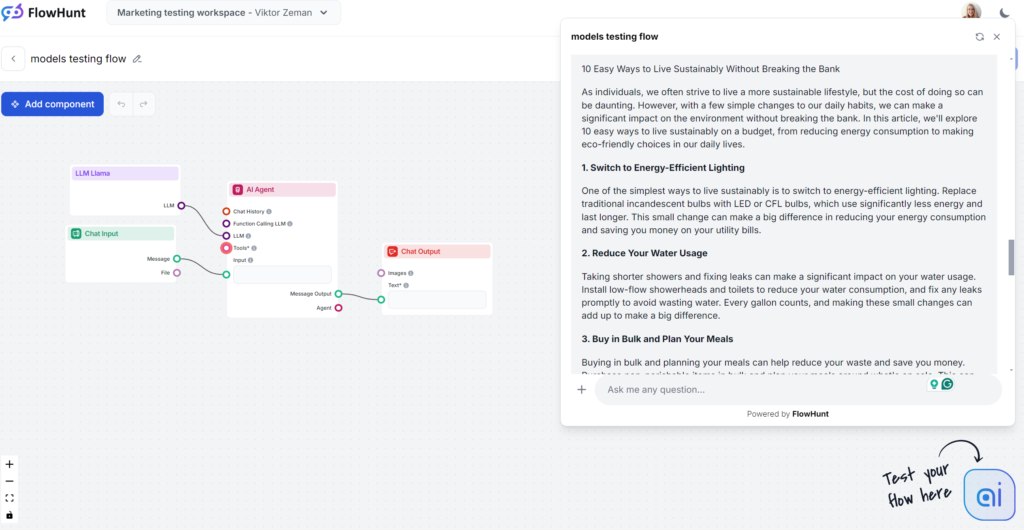
Llamas starkaste sida var nyckelordsanvändningen. Å andra sidan var skrivstilen oinspirerad och lite ordrik, men ändå mindre tråkig än GPT-4o. Llama är som GPT-4o:s kusin – ett säkert innehållsval med något ordrik och vag skrivstil. Det är ett bra val om du gillar skrivstilen hos OpenAI:s modeller men vill slippa typiska GPT-fraser.
Ton och språk
Llama-genererade artiklar påminner mycket om GPT-4o:s. Ordrikedomen och vagheten är jämförbar, men tonen är praktisk och lättillgänglig.
Nyckelordsanvändning
Meta vinner i testet för nyckelordsanvändning. Llama använde nyckelordet flera gånger, även i inledningen, och inkluderade naturligt liknande fraser och andra relevanta nyckelord.
Läsbarhet
På Flesch-Kincaid-skalan hamnar denna utdata på årskurs 10–12 (ganska svår), med poäng 53,4, något bättre än GPT-4o (51,2). Med så kort utdata påverkar kanske till och med ordet “hållbarhet” läsbarheten. Det finns fortfarande utrymme för förbättring.
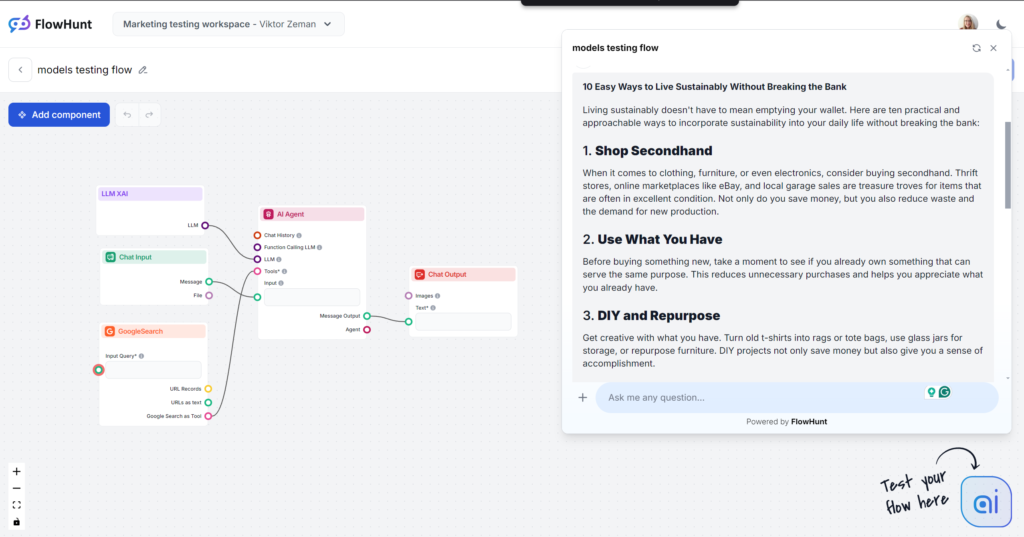
Grok var en stor överraskning, särskilt vad gäller ton och språk. Med en mycket naturlig och avslappnad ton kändes det som att få snabba tips från en nära vän. Om avslappnat och rappt är din stil är Grok definitivt valet för dig.
Ton och språk
Utdata är mycket lättläst. Språket är naturligt, meningarna rappa och Grok använder idiom på ett skickligt sätt. Modellen håller sig till sin primära ton och pressar gränserna för mänskligt liknande text. Notera: Groks avslappnade ton passar inte alltid B2B- och SEO-inriktat innehåll.
Nyckelordsanvändning
Grok använde nyckelordet vi bad om, men endast i slutsatsen. Andra modeller placerade nyckelordet bättre och lade till fler relevanta ord, medan Grok fokuserade mer på flytet i texten.
Läsbarhet
Med det lättsamma språket klarade Grok Flesch-Kincaid-testet galant. Den fick poäng 61,4, vilket motsvarar årskurs 7–8 (lätt engelska). Det är optimalt för att göra ämnen tillgängliga för allmänheten. Det stora lyftet i läsbarhet är nästan påtagligt.
LLM:ers styrka beror på kvaliteten på deras träningsdata, som ibland kan vara partisk eller felaktig, och därmed sprida desinformation. Det är avgörande att faktagranska och granska AI-genererat innehåll för rättvisa och inkludering. När du provar olika modeller, kom ihåg att varje modell har olika synsätt kring datasekretess och begränsning av skadligt innehåll.
För att styra etisk användning måste organisationer skapa ramar för dataskydd, biasminskning och innehållsmoderering. Detta inkluderar regelbunden dialog mellan AI-utvecklare, skribenter och juridiska experter. Tänk på denna lista över etiska frågor:
Valet av LLM bör vara etiskt förenligt med organisationens riktlinjer för innehåll. Både öppna och proprietära modeller bör utvärderas för potentiell missanvändning.
Bias, felaktigheter och hallucinationer är fortfarande stora problem med AI-genererat innehåll. Tack vare inbyggda riktlinjer blir LLM:ers utdata ofta vag och av låg kvalitet. Företag behöver ofta extra träning och säkerhetsåtgärder för att hantera dessa frågor. För småföretag är tid och resurser för anpassad träning ofta otillgängliga. Ett alternativ är att lägga till dessa funktioner via generella modeller och tredjepartsverktyg som FlowHunt.
Med FlowHunt kan du ge specifik kunskap, internetåtkomst och nya funktioner till klassiska basmodeller. På så sätt kan du välja rätt modell för uppgiften utan basmodellens begränsningar eller otaliga abonnemang.
En annan stor utmaning är modellernas komplexitet. Med miljarder parametrar kan de vara svåra att hantera, förstå och felsöka. FlowHunt ger dig mycket mer kontroll än vanliga promptar i en chatt. Du kan lägga till separata funktioner som block och justera dem för att skapa ditt egna bibliotek av AI-verktyg.
Framtiden för språkmodeller (LLM:er) inom innehållsskrivande är lovande och spännande. När dessa modeller utvecklas utlovas ökad noggrannhet och mindre bias i innehållsgenereringen. Det innebär att skribenter kan skapa pålitliga, mänskliga texter med AI-genererat innehåll.
LLM:er kommer inte bara hantera text utan även bli skickliga på multimodalt innehåll. Det innebär att de kan hantera både text och bilder och därigenom stärka kreativt innehåll för olika branscher. Med större och bättre filtrerade datamängder kommer LLM:er skapa mer tillförlitligt material och förfina skrivstilar.
Men än så länge klarar inte LLM:er detta på egen hand, och dessa möjligheter är utspridda mellan olika företag och modeller, som alla tävlar om din uppmärksamhet och dina pengar. FlowHunt samlar dem alla och låter
GPT-4 är den mest populära och mångsidiga för allmänna texter, men Metas Llama erbjuder en fräschare skrivstil. Claude 3 är bäst för ren, enkel text, medan Grok utmärker sig med en avslappnad, mänsklig ton. Det bästa valet beror på dina innehållsmål och stilpreferenser.
Tänk på läsbarhet, ton, originalitet, nyckelordsanvändning och hur varje modell passar dina innehållsbehov. Väg även in styrkor som kreativitet, genrespridning eller integrationsmöjligheter, och var medveten om utmaningar som bias, ordrikedom eller resurskrav.
FlowHunt låter dig testa och jämföra flera ledande LLM:er i en och samma miljö, vilket ger kontroll över utdata och gör det möjligt att hitta den bästa modellen för just ditt innehållsflöde – utan flera olika prenumerationer.
Ja. LLM:er kan förstärka bias, skapa felaktig information och väcka frågor om dataintegritet. Det är viktigt att faktagranska AI-utdata, utvärdera modellerna ur ett etiskt perspektiv och upprätta ramar för ansvarsfull användning.
Framtidens LLM:er kommer erbjuda förbättrad noggrannhet, mindre bias och multimodal innehållsgenerering (text, bilder osv.), vilket gör det möjligt för skribenter att skapa mer pålitligt och kreativt innehåll. Enade plattformar som FlowHunt kommer att förenkla tillgången till dessa avancerade möjligheter.
Upplev toppmoderna LLM:er sida vid sida och förbättra din arbetsprocess för innehållsskrivande med FlowHunt:s enade plattform.
Textgenerering med stora språkmodeller (LLMs) avser den avancerade användningen av maskininlärningsmodeller för att producera text som liknar mänskligt språk ut...
En stor språkmodell (LLM) är en typ av AI som tränats på enorma textmängder för att förstå, generera och bearbeta mänskligt språk. LLM:er använder djupinlärning...
Upptäck kostnaderna som är förknippade med att träna och driftsätta stora språkmodeller (LLM) som GPT-3 och GPT-4, inklusive beräknings-, energi- och hårdvaruut...