


AI-agenter: Hur GPT 4o Tänker
Utforska tankeprocesserna hos AI-agenter i denna omfattande utvärdering av GPT-4o. Upptäck hur den presterar inom uppgifter som innehållsgenerering, problemlösn...
7 min läsning
AI
GPT-4o
+6

En djupdykning i GPT-4.1:s prestation över standardiserade AI-uppgifter, med fokus på dess resonemang, effektivitet, praktiska tillämpningar och konsekvent outputkvalitet.
OpenAI:s GPT-4.1 representerar ett betydande framsteg inom AI-kapabiliteter, med förbättringar inom resonemang, verktygsanvändning och outputkvalitet. Denna analys granskar GPT-4.1:s prestation över fem grundläggande uppgiftstyper för att ge insikt i dess praktiska kapacitet och begränsningar.
Följande analys baseras på dokumenterad prestanda för GPT-4.1 över fem standardiserade benchmarkuppgifter:
För varje uppgift utvärderar vi GPT-4.1:s angreppssätt på problemlösning, verktygsanvändning, bearbetningstid och outputkvalitet.
När modellen ombads generera innehåll om bästa praxis för delegering inom projektledning visade GPT-4.1 ett effektivt tillvägagångssätt:
Denna prestation antyder att GPT-4.1 prioriterar effektivitet vid innehållsgenerering och snabbt går från informationsinsamling till syntes utan att visa mellanliggande resonemangssteg.
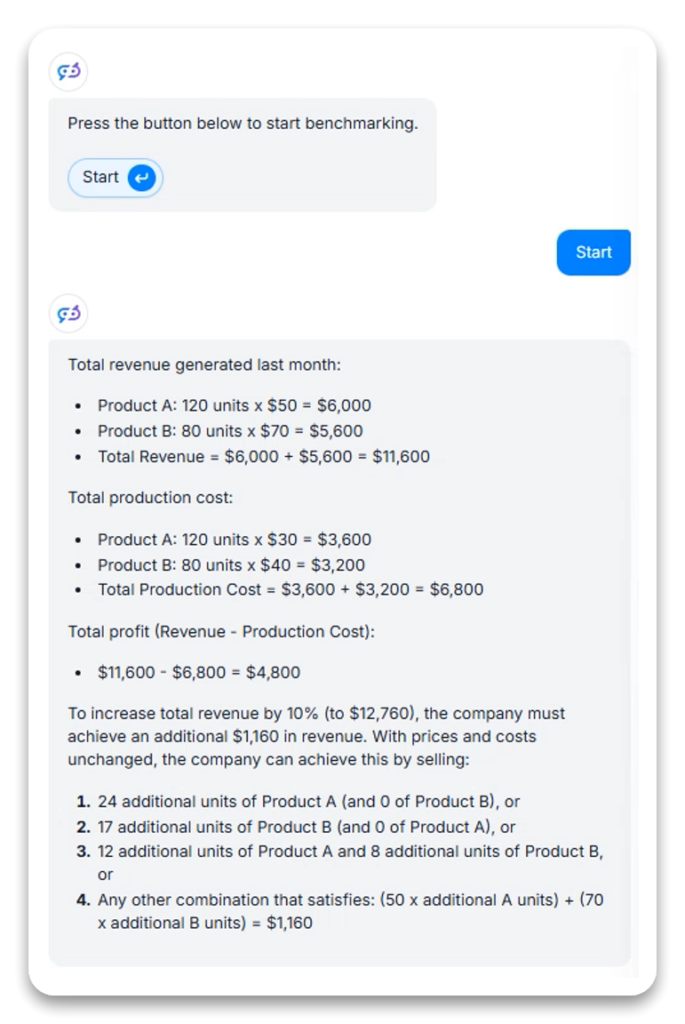
Beräkningsuppgiften testade GPT-4.1:s förmåga att lösa ett flerdelat affärsproblem som omfattade intäkter, vinst och strategisk planering.
GPT-4.1:s angreppssätt på matematiskt resonemang verkar fokusera på praktiska affärstillämpningar snarare än abstrakta matematiska samband och ger specifika lösningar snarare än generaliserade ekvationer.
Sammanfattningsuppgiften visade GPT-4.1:s effektivitet i informationsdestillering:
Denna prestation visar GPT-4.1:s förmåga att snabbt extrahera och konsolidera viktig information utan att behöva uttryckliga resonemangssteg för enklare textbearbetningsuppgifter.
Vid jämförelsen mellan el- och vätgasdrivna fordon använde GPT-4.1 sin mest omfattande forskningsprocess:
Denna prestation antyder att GPT-4.1 avsätter betydligt mer bearbetningstid till uppgifter som kräver djupgående forskning och nyanserad jämförelse, där omfattande informationsinsamling prioriteras över snabbhet.
Uppgiften kreativt skrivande visade GPT-4.1:s angreppssätt på fantasifullt innehållsskapande:
GPT-4.1:s angreppssätt på kreativt skrivande tycks bygga på systematisk forskning och organisering innan den kreativa processen tar vid, vilket antyder en analytisk grund för fantasifulla uppgifter.
Analys av dessa fem uppgifter visar flera konsekventa mönster i hur GPT-4.1 angriper olika problemtyper:
GPT-4.1 visar sällan sitt interna resonemang, utan visar istället:
Detta angreppssätt prioriterar effektivitet men minskar insynen i hur slutsatserna dras.
Bearbetningstiden varierar kraftigt beroende på uppgiftens komplexitet:
Detta tyder på intelligent resurshantering utifrån uppgiftens krav.
Trots variationer i bearbetningssätt bibehåller GPT-4.1 konsekvent outputkvalitet över olika uppgiftstyper:
För uppgifter som kräver specialiserad kunskap:
Dessa prestandaegenskaper antyder flera optimala användningsområden för GPT-4.1:
Modellens snabba bearbetning av enklare uppgifter gör den lämplig för:
Modellens villighet att lägga tid på informationsinsamling ger tillämpningar inom:
Fokus på praktiska tillämpningar och flera lösningsvägar innebär värde för:
GPT-4.1 visar ett balanserat angreppssätt över olika uppgiftstyper, med särskilda styrkor inom effektiv informationshantering och praktisk tillämpning. Dess förmåga att anpassa bearbetningstiden efter uppgiftens komplexitet samtidigt som outputkvaliteten bibehålls gör den väl lämpad för ett brett spektrum av affärs- och professionella tillämpningar.
Modellens “black box”-angreppssätt för resonemang—att visa åtgärder men inte mellanliggande tankar—utgör både en begränsning i transparens och en fördel i bearbetningseffektivitet. För de flesta praktiska tillämpningar tycks outputens kvalitet och relevans kompensera för den minskade insynen i resonemangsprocessen.
När organisationer i allt högre grad integrerar AI-stöd i arbetsflöden positionerar GPT-4.1:s kombination av effektivitet, anpassningsförmåga och outputkvalitet den som ett värdefullt verktyg för kunskapsarbetare inom olika domäner—särskilt för dem som prioriterar praktiska resultat framför processynlighet.
GPT-4.1 utmärker sig i effektiv informationsbearbetning, konsekvent outputkvalitet och praktisk tillämpning inom innehållsgenerering, beräkningar, sammanfattning, jämförande analys och kreativt skrivande. Den anpassar bearbetningstiden utifrån uppgiftens komplexitet och levererar handlingsbara, välstrukturerade resultat.
Ja, GPT-4.1 använder ofta en 'black-box'-metod—den visar åtgärder och resultat men avslöjar inte sina interna resonemangssteg. Detta ökar effektiviteten men minskar insynen i hur slutsatserna dras.
GPT-4.1 är idealisk för effektivitetkritiska uppgifter som innehållsskapande, sammanfattning, rutinmässiga affärsberäkningar, förstautkast av kreativt skrivande samt forskningsintensiva uppgifter såsom jämförande analys och marknadsundersökningar, samt strategiskt affärsstödsbeslut.
För komplexa forsknings- och jämförelseuppgifter lägger GPT-4.1 betydligt mer bearbetningstid och använder sekventiella verktyg (som sökningar och URL-crawling) för att samla in och syntetisera information, vilket säkerställer omfattande och balanserade resultat.
Arshia är en AI-arbetsflödesingenjör på FlowHunt. Med en bakgrund inom datavetenskap och en passion för AI, specialiserar han sig på att skapa effektiva arbetsflöden som integrerar AI-verktyg i vardagliga uppgifter, vilket förbättrar produktivitet och kreativitet.
Upplev kraften hos AI-modeller som GPT-4.1 i ditt arbetsflöde. Bygg chattbottar, automatisera uppgifter och snabba upp din verksamhet med FlowHunt.
Utforska tankeprocesserna hos AI-agenter i denna omfattande utvärdering av GPT-4o. Upptäck hur den presterar inom uppgifter som innehållsgenerering, problemlösn...
Utforska de viktigaste funktionerna, tekniska framstegen och den verkliga påverkan av GPT-5. Denna guide täcker styrkor, begränsningar, prissättning, etiska frå...
Utforska AI-agentmodellernas värld med en omfattande analys av 20 banbrytande system. Upptäck hur de tänker, resonerar och presterar inom olika uppgifter, och f...

