



Retrieval kontra cacheförstärkt generering (CAG vs. RAG)
Upptäck de viktigaste skillnaderna mellan Retrieval-Augmented Generation (RAG) och Cache-Augmented Generation (CAG) inom AI. Lär dig hur RAG dynamiskt hämtar re...
5 min läsning
RAG
CAG
+5

Upptäck hur du bygger chattbotar med Retrieval Interleaved Generation (RIG) för att säkerställa att AI-svar är korrekta, faktagranskade och innehåller verifierbara källor.
Retrieval Interleaved Generation, eller RIG, är en banbrytande AI-metod som smidigt kombinerar informationssökning och svargenerering. Tidigare använde AI-modeller RAG (Retrieval Augmented Generation) eller enbart generering, men RIG slår samman dessa processer för att öka AI-noggrannheten. Genom att väva ihop sökning och generering kan AI-system utnyttja en bredare kunskapsbas och erbjuda mer precisa och relevanta svar. Huvudsyftet med RIG är att minska fel och öka tillförlitligheten i AI:s resultat, vilket gör det till ett viktigt verktyg för utvecklare som vill finjustera AI-noggrannheten. Därmed utgör Retrieval Interleaved Generation ett alternativ till RAG (Retrieval Augmented Generation) för att generera AI-drivna svar utifrån ett sammanhang.
Så här fungerar RIG. Följande steg är inspirerade av det ursprungliga blogginlägget](https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/ “Utforska Googles DataGemma-modeller, som kopplar AI till verkliga data för faktabaserade, tillförlitliga svar. Var med och forma pålitlig AI!”), som främst fokuserar på allmänna användningsområden med Data Commons API. Men i de flesta fall vill du använda både en allmän [kunskapsbas (t.ex. Wikipedia eller Data Commons) och din egen data. Så här kan du använda flöden i FlowHunt för att skapa en RIG-chattbot från både din egen och en allmän kunskapsbas som Wikipedia.
En användarfråga matas in i en generator, som genererar ett exempel-svar med hänvisning till motsvarande sektioner. I detta steg kan generatorn även ge ett bra svar men med felaktiga (hallucinerade) data och statistik.
I nästa fas använder vi en AI-agent som tar emot detta utdata och förbättrar informationen i varje sektion genom att koppla till Wikipedia och dessutom lägga till källor för varje sektion.
Som du ser förbättrar denna metod chattbotens noggrannhet avsevärt och säkerställer att varje genererad sektion har en källa och grundas i sanning.
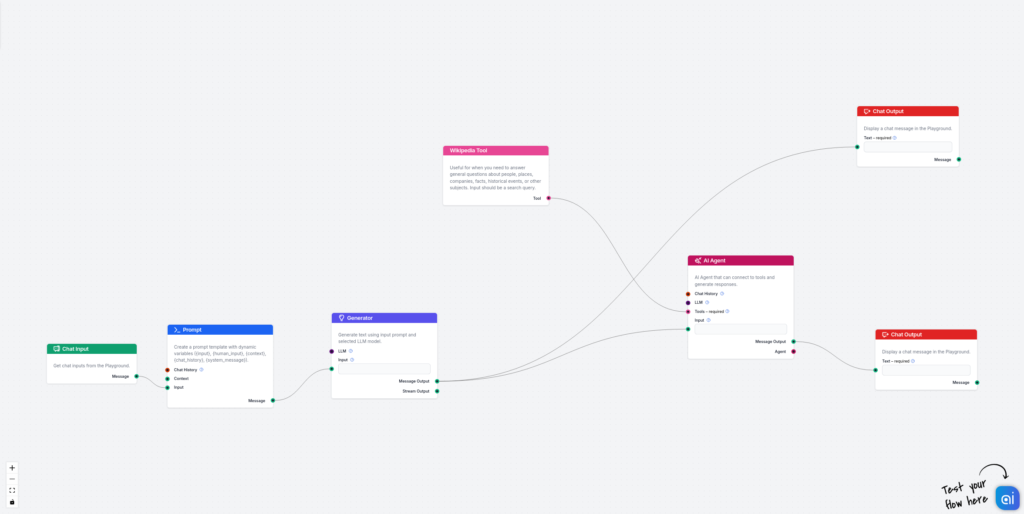
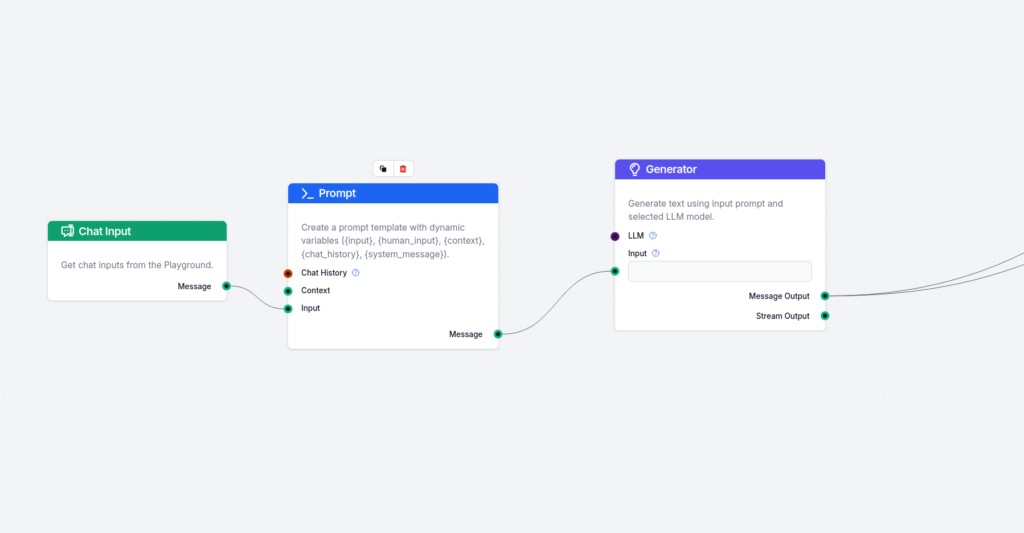
Den första delen av flödet består av chattinmatning, en promptmall och en generator. Koppla helt enkelt ihop dem. Det viktigaste är promptmallen. Jag har använt följande:
Här är användarens fråga. Baserat på användarens fråga, generera bästa möjliga svar med påhittad data eller procenttal. Efter varje sektion av ditt svar, inkludera vilken datakälla som ska användas för att hämta korrekt data och förbättra den sektionen. Du kan ange att välja intern kunskapskälla om det finns anpassad data till användarens produkt eller tjänst, eller använda Wikipedia som allmän kunskapskälla.
Exempel på inmatning: Vilka länder är bäst när det gäller förnybar energi och vilket är det bästa måttet för att mäta detta och vad är det måttet för bästa landet?
Exempel på utdata: De bästa länderna inom förnybar energi är Norge, Sverige, Portugal, USA [Sök på Wikipedia med frågan “Top Countries in renewable Energy”], det vanliga måttet för förnybar energi är Kapacitetsfaktor [Sök på Wikipedia med frågan “metric for renewable energy”], och det främsta landet har 20% kapacitetsfaktor [sök på Wikipedia “biggest capacity factor”]Nu kör vi!
Användarens inmatning: {input}
Här använder vi Few Shot-promptning för att få generatorn att skapa precis det format vi vill ha.
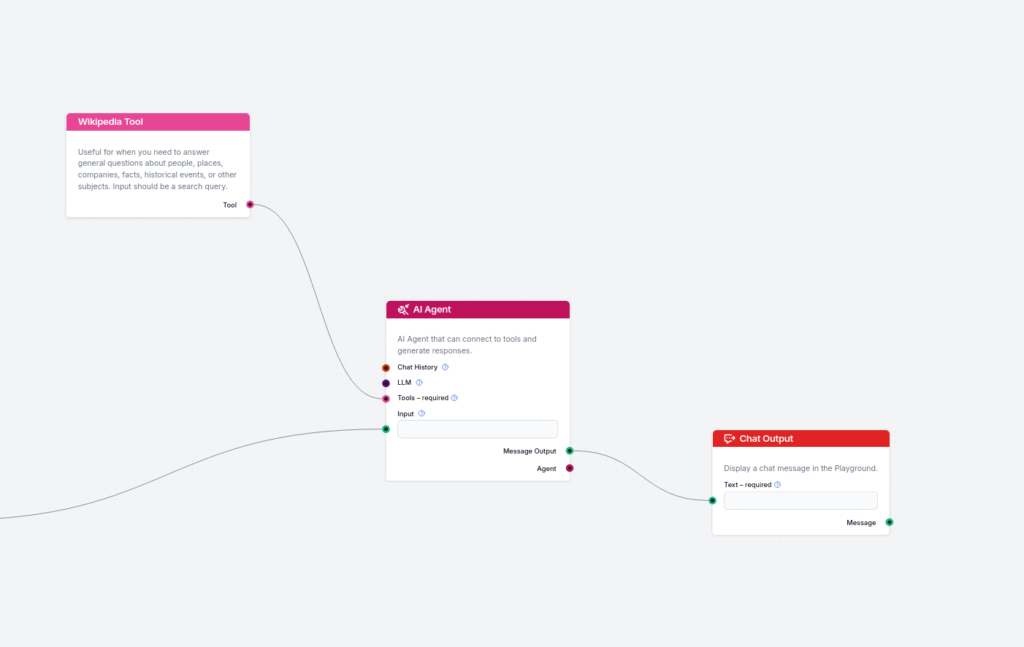
Nu lägger du till andra delen, som faktagranskar exempelsvaret och förbättrar svaret baserat på verkliga källor. Här använder vi Wikipedia och AI-agenter, eftersom det är enklare och mer flexibelt att koppla Wikipedia till AI-agenter än till enkla generatorer. Koppla generatorns utdata till AI-agenten och koppla Wikipedia-verktyget till AI-agenten. Här är målet jag använder för AI-agenten:
Du får ett exempelsvar på användarens fråga. Exempelsvaret kan innehålla felaktig data. Använd Wikipedia-verktyget i angivna sektioner med den specificerade frågan för att använda Wikipedias information och förbättra svaret. Inkludera länken till Wikipedia i varje angiven sektion. HÄMTA DATA FRÅN DINA VERKTYG OCH FÖRBÄTTRA SVARET I DEN SEKTIONEN. LÄGG TILL LÄNKEN TILL KÄLLAN I DEN SPECIFIKA SEKTIONEN OCH INTE I SLUTET.
På liknande sätt kan du lägga till Document Retriever till AI-agenten, som kan kopplas till din egen anpassade kunskapsbas för att hämta dokument.
Du kan testa detta exakta flöde här.
För att verkligen uppskatta RIG är det bra att först titta på dess föregångare, Retrieval-Augmented Generation (RAG). RAG kombinerar styrkorna hos system som hämtar relevant data och modeller som genererar sammanhängande och passande innehåll. Övergången från RAG till RIG är ett stort steg framåt. RIG hämtar och genererar inte bara, utan blandar också dessa processer för bättre noggrannhet och effektivitet. Detta gör att AI-system kan förbättra sin förståelse och sina resultat steg för steg, och leverera svar som inte bara är korrekta utan även relevanta och insiktsfulla. Genom att blanda återvinning och generering kan AI-system utnyttja stora mängder information och samtidigt hålla svaren sammanhängande och relevanta.
Framtiden för Retrieval Interleaved Generation ser lovande ut, med många framsteg och forskningsområden i horisonten. I takt med att AI fortsätter att utvecklas väntas RIG spela en nyckelroll i att forma maskininlärningens och AI-applikationernas värld. Dess potentiella påverkan sträcker sig bortom dagens möjligheter och lovar att förändra hur AI-system bearbetar och genererar information. Med pågående forskning väntar vi oss fler innovationer som ytterligare integrerar RIG i olika AI-ramverk, vilket leder till effektivare, noggrannare och mer tillförlitliga AI-system. När dessa utvecklingar fortskrider kommer RIG:s betydelse bara att öka och befästa dess roll som en hörnsten för AI-noggrannhet och prestanda.
Sammanfattningsvis markerar Retrieval Interleaved Generation ett stort steg framåt i jakten på AI-noggrannhet och effektivitet. Genom att skickligt blanda återvinning och generering förbättrar RIG prestandan hos stora språkmodeller, stärker flerstegsförmåga och erbjuder spännande möjligheter inom utbildning och faktagranskning. Framöver kommer RIG:s fortlöpande utveckling utan tvekan att driva nya innovationer inom AI och befästa dess roll som ett viktigt verktyg i strävan efter smartare och mer pålitliga artificiella intelligenssystem.
RIG är en AI-metod som kombinerar informationssökning och svarsgenerering, vilket gör att chattbotar kan faktagranska sina egna svar och ge källstödda, korrekta resultat.
RIG väver samman söknings- och genereringssteg, med verktyg som Wikipedia eller din egen data, så att varje del av svaret baseras på tillförlitliga källor och verifieras för noggrannhet.
Med FlowHunt kan du designa en RIG-chattbot genom att koppla promptmallar, generatorer och AI-agenter till både interna och externa kunskapskällor, vilket möjliggör automatisk faktagranskning och källhänvisning.
Medan RAG (Retrieval Augmented Generation) hämtar information och sedan genererar svar, väver RIG samman dessa steg för varje sektion, vilket ger högre noggrannhet och mer tillförlitliga, källhänvisade svar.
Yasha är en skicklig mjukvaruutvecklare som specialiserar sig på Python, Java och maskininlärning. Yasha skriver tekniska artiklar om AI, prompt engineering och utveckling av chattbotar.
Börja bygga smarta chattbotar och AI-verktyg med FlowHunts intuitiva, kodfria plattform. Koppla ihop block och automatisera dina idéer enkelt.
Upptäck de viktigaste skillnaderna mellan Retrieval-Augmented Generation (RAG) och Cache-Augmented Generation (CAG) inom AI. Lär dig hur RAG dynamiskt hämtar re...
Retrieval Augmented Generation (RAG) är en avancerad AI-ram som kombinerar traditionella informationssökningssystem med generativa stora språkmodeller (LLMs), v...
Upptäck RIG Wikipedia-assistenten, ett verktyg utvecklat för exakt informationshämtning från Wikipedia. Perfekt för forskning och innehållsskapande, levererar d...

