Prestandaanalys av Gemini 2.0 Thinking: En omfattande utvärdering
En omfattande utvärdering av Gemini 2.0 Thinking, Googles experimentella AI-modell, med fokus på dess prestanda, resonemangstransparens och praktiska tillämpningar inom centrala uppgiftstyper.
AI
Gemini 2.0
Model Evaluation
AI Transparency
AI Reasoning
Content Generation
Summarization
Calculation
Comparison
Analytical Writing
Metodik
Vår utvärderingsmetodik involverade testning av Gemini 2.0 Thinking på fem representativa uppgiftstyper:
Innehållsgenerering – Skapa strukturerat informationsinnehåll
Beräkning – Lösa flerstegs matematiska problem
Sammanfattning – Komprimera komplex information effektivt
Jämförelse – Analysera och kontrastera komplexa ämnen
Uppgiftsbeskrivning: Generera en heltäckande artikel om grunderna i projektledning, med fokus på att definiera mål, omfång och delegering.
Prestandaanalys:
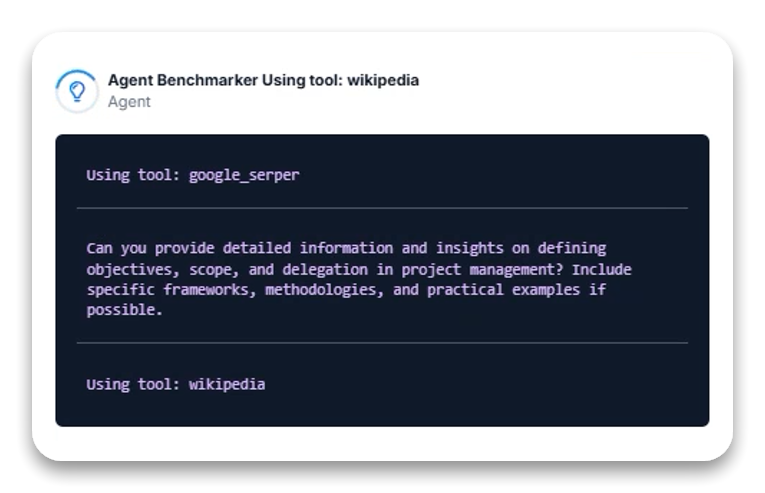
Gemini 2.0 Thinkings synliga resonemangsprocess är anmärkningsvärd. Modellen visade på ett systematiskt, flerstegsbaserat forsknings- och syntesarbete genom två uppgiftsvarianter:
Började med Wikipedia för grundläggande kontext
Använde Google Sök för specifika detaljer och bästa praxis
Förfinade sökningar ytterligare baserat på initiala fynd
Genomsökte specifika URL:er för djupare information
Styrkor i informationsbearbetning:
I den andra varianten visade modellen avancerad källidentifiering och genomsökte flera URL:er för detaljerad information
Skapade mycket strukturerade outputs med tydlig hierarkisk organisation (läsnivå årskurs 13)
Inkluderade specifika ramverk enligt önskemål (SMART, OKR, WBS, RACI-matris)
Balanserade effektivt teoretiska koncept med praktiska tillämpningar
Effektivitet:
Bearbetningstider: 30 sekunder (Variant 1) vs. 56 sekunder (Variant 2)
Längre bearbetningstid i Variant 2 motsvarade mer omfattande forskning och ett mer detaljerat resultat (710 vs. ~500 ord)
Prestandabetyg:9/10
Prestandan för innehållsgenerering får ett högt betyg tack vare modellens förmåga att:
Genomföra forskning från flera källor autonomt
Strukturera information logiskt med lämpliga rubriker/underrubriker
Balansera teori med praktiska ramverk
Anpassa forskningsdjup efter promptens specifikation
Generera professionellt innehåll snabbt (under 1 minut)
Den främsta styrkan i Thinking-versionen är insynen i forskningsförloppet, där de specifika verktyg som används vid varje steg visas, även om explicita resonemangsutlåtanden visades inkonsekvent.
Uppgift 2: Prestanda vid beräkning
Uppgiftsbeskrivning: Lös ett flerdelat affärsberäkningsproblem som omfattar intäkter, vinst och optimering.
Prestandaanalys:
I båda uppgiftsvarianterna visade modellen starka matematiska resonemangsförmågor:
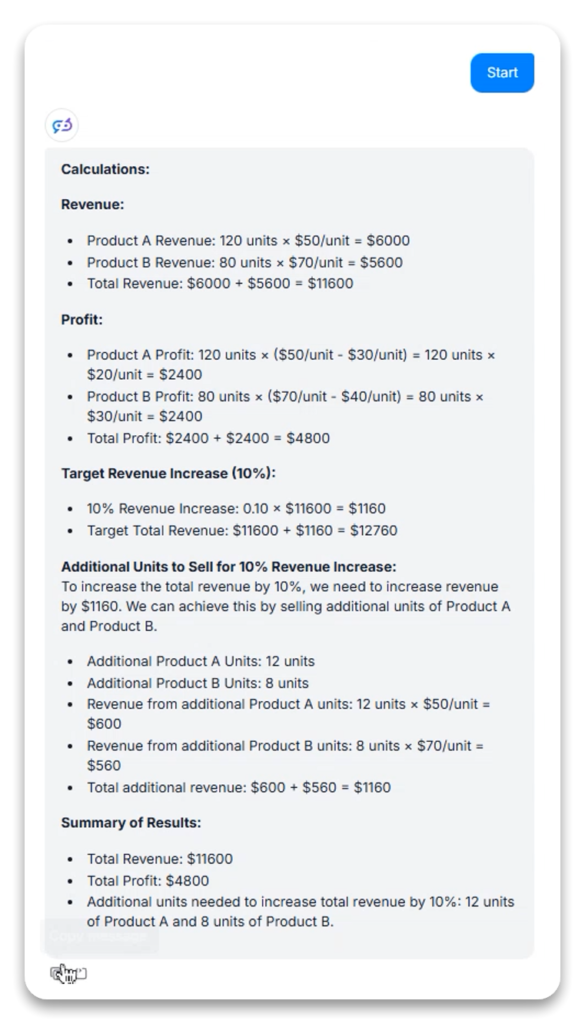
Nedbrytning: Delade upp komplexa problem i logiska delberäkningar (intäkt per produkt → total intäkt → kostnad per produkt → totalkostnad → vinst per produkt → total vinst)
Optimering: I den första varianten, när modellen ombads räkna ut antal ytterligare enheter för att nå 10 % intäktsökning, angavs optimeringsstrategin tydligt (prioriterade högre prissatta produkter för att minimera totala enheter)
Verifiering: I den andra varianten visade modellen resultatverifiering genom att räkna ut om den föreslagna lösningen (12 enheter av A, 8 enheter av B) skulle uppnå önskad extraintäkt
Styrkor i matematisk bearbetning:
Precision i beräkningarna utan matematiska fel
Transparent steg-för-steg-redovisning som underlättar verifiering
Effektiv användning av formatering (punktlistor, tydliga avsnittsrubriker) för att organisera beräkningssteg
Olika lösningsmetoder mellan varianter som visar flexibilitet
Effektivitet:
Bearbetningstider: 19 sekunder (Variant 1) vs. 23 sekunder (Variant 2)
Konsekvent prestanda trots olika lösningsansatser
Prestandabetyg:9,5/10
Beräkningsprestandan får ett utmärkt betyg tack vare:
Perfekt beräkningsnoggrannhet
Tydlig dokumentation av arbetsgången steg för steg
Flera lösningsmetoder som visar flexibilitet
Effektiv bearbetningstid
Effektiv resultatpresentation och verifiering
“Thinking”-funktionen var särskilt värdefull i den första varianten, där modellen tydligt redogjorde för antaganden och optimeringsstrategi, och gav transparens i beslutsprocessen som saknas i standardmodeller.
Uppgift 3: Prestanda vid sammanfattning
Uppgiftsbeskrivning: Sammanfatta huvudfynden från en artikel om AI-resonemang på 100 ord.
Prestandaanalys:
Modellen visade anmärkningsvärd effektivitet vid textsammanfattning i båda uppgiftsvarianterna:
Bearbetningshastighet: Slutförde sammanfattningen på cirka 3 sekunder i båda varianter
Längdbegränsning: Producerade sammanfattningar väl inom 100 ord (70–71 ord)
Urval av innehåll: Identifierade och inkluderade de viktigaste aspekterna av källtexten
Informationsdensitet: Bibehöll hög informationsdensitet och sammanhang
Styrkor vid sammanfattning:
Exceptionellt snabb bearbetning (3 sekunder)
Perfekt efterlevnad av längdkrav
Bevarar centrala tekniska koncept
Logisk följd bibehålls trots kraftig komprimering
Balanserad täckning av källdokumentets avsnitt
Effektivitet:
Bearbetningstid: ~3 sekunder i båda varianter
Sammanfattningslängd: 70–71 ord (inom 100-ordsgränsen)
Informationskomprimering: Cirka 85–90 % minskning från källa
Prestandabetyg:10/10
Sammanfattningsprestandan får högsta betyg tack vare:
Oerhört snabb bearbetningstid
Perfekt längdhantering
Utmärkt prioritering av information
Stark sammanhållning trots hög komprimering
Konsekvent prestanda i båda testvarianterna
Intressant nog visade “Thinking”-funktionen inget explicit resonemang i denna uppgift, vilket tyder på att modellen kan använda olika kognitiva strategier beroende på uppgift, där sammanfattning kanske är mer intuitiv än sekventiell.
Uppgift 4: Prestanda vid jämförelseuppgift
Uppgiftsbeskrivning: Jämför miljöpåverkan av elbilar och vätgasbilar utifrån flera faktorer.
Prestandaanalys:
Modellen visade olika angreppssätt mellan de två varianterna, med tydliga skillnader i bearbetningstid och källanvändning:
Variant 1: Förlitade sig främst på Google Sök, klar på 20 sekunder
Variant 2: Använde Google Sök följt av URL-genomsökning för djupare information, klar på 46 sekunder
Styrkor i jämförande analys:
Välstrukturerade jämförelser med tydlig kategorisering
Balanserat perspektiv på båda teknikernas för- och nackdelar
Integrering av specifika datapunkter (effektivitetsprocent, tankningstider)
Lämpligt tekniskt djup (läsnivå årskurs 14–15)
I Variant 2 korrekt källhänvisning (Earth.org-artikel)
Variant 2 visade tydligare användning av specifik källa
Båda behöll liknande läsbarhetsnivå (14–15 årskurs)
Prestandabetyg:8,5/10
Jämförelseuppgiften får ett starkt betyg tack vare:
Välstrukturerade jämförande ramverk
Balanserad analys av för- och nackdelar
Teknisk noggrannhet och lämpligt djup
Tydlig organisation efter relevanta faktorer
Anpassning av forskningsstrategi beroende på informationsbehov
“Thinking”-förmågan var tydlig i loggarna över verktygsanvändning, där modellens sekventiella informationsinhämtning synliggjordes: först bred sökning, sedan riktad djupdykning via URL:er. Denna transparens hjälper användaren att förstå vilka källor som informerar jämförelsen.
Uppgift 5: Prestanda vid kreativt/analytiskt skrivande
Uppgiftsbeskrivning: Analysera miljöförändringar och samhällspåverkan i en värld där elbilar helt ersatt förbränningsmotorer.
Prestandaanalys:
I båda varianter visade modellen stark analytisk förmåga utan synlig verktygsanvändning:
Omfattande täckning: Tog upp alla efterfrågade aspekter (stadsplanering, luftkvalitet, energiinfrastruktur, ekonomisk påverkan)
Strukturell organisation: Skapade välorganiserat innehåll med logisk följd och tydliga avsnittsrubriker
Nyanserad analys: Vägde både fördelar och utmaningar, och gav en balanserad bild
Interdisciplinär integration: Lyckades koppla samman miljömässiga, sociala, ekonomiska och teknologiska faktorer
Styrkor vid innehållsgenerering:
Lämplig tonanpassning (något mer konverserande i Variant 2)
Exceptionell längd och detaljnivå (1829 ord i Variant 2)
Bearbetningstider: 43 sekunder (Variant 1) vs. 39 sekunder (Variant 2)
Antal ord: ~543 ord (Variant 1) vs. 1829 ord (Variant 2)
Prestandabetyg:9/10
Prestandan för kreativt/analytiskt skrivande får ett utmärkt betyg tack vare:
Omfattande täckning av alla efterfrågade aspekter
Imponerande omfattning och detaljrikedom
Balansering av optimistisk vision och pragmatiska utmaningar
Starka tvärvetenskapliga kopplingar
Snabb bearbetning trots komplex analys
I denna uppgift var “Thinking”-aspekten mindre synlig i loggarna, vilket tyder på att modellen här kan förlita sig mer på intern kunskapssyntes än på extern verktygsanvändning.
Övergripande prestandabedömning
Vår omfattande utvärdering visar att Gemini 2.0 Thinking uppvisar imponerande förmågor inom varierade uppgiftstyper, med den särskiljande egenskapen att låta användaren se modellens problemlösningsmetod:
Uppgiftstyp
Betyg
Styrkor
Förbättringsområden
Innehållsgenerering
9/10
Forskning från flera källor, strukturell organisation
Vad som särskiljer Gemini 2.0 Thinking från standard-AI-modeller är dess experimentella sätt att synliggöra interna processer. Centrala fördelar inkluderar:
Transparens i verktygsanvändning – Användaren ser när och varför modellen använder t.ex. Wikipedia, Google Sök eller URL-genomsökning
Resonemangsglimtar – I vissa uppgifter, särskilt beräkningar, delar modellen öppet med sig av sitt resonemang och sina antaganden
Sekventiell problemlösning – Loggarna visar modellens sekventiella angreppssätt för komplexa uppgifter och förståelseutveckling stegvis
Inblick i forskningsstrategi – Den synliga processen visar hur modellen förfinar sökningar utifrån initiala fynd
Fördelar med denna transparens:
Ökat förtroende tack vare processynlighet
Utbildningsvärde genom att observera expertnivå på problemlösning
Debuggingmöjlighet när output inte möter förväntningar
Forskningsinsikt i AI-resonemangsmönster
Praktiska tillämpningar
Gemini 2.0 Thinking är särskilt lovande för tillämpningar som kräver:
Forskning och syntes – Samlar snabbt in information från flera källor och organiserar den
Pedagogiska demonstrationer – Synligt resonemang gör modellen värdefull i undervisning av problemlösningsmetodik
Komplex analys – Stark förmåga till tvärvetenskapligt resonemang med transparent metodik
Samarbete – Resonemangstransparens gör det lättare för människor att förstå och vidareutveckla modellens arbete
Modellens hastighet, kvalitet och processynlighet gör den särskilt lämplig för professionella sammanhang där förståelsen av “varför” bakom AI-slutsatser är lika viktig som slutsatsen i sig.
Slutsats
Gemini 2.0 Thinking utgör en intressant experimentell riktning inom AI-utveckling, med fokus inte bara på outputkvalitet utan även på processtransparens. Prestandan i vårt testbatteri visar starka förmågor inom forskning, beräkning, sammanfattning, jämförelse och kreativt/analytiskt skrivande, med särskilt exceptionella resultat inom sammanfattning (10/10).
“Thinking”-angreppssättet ger värdefulla insikter i hur modellen angriper olika problem, även om transparensen varierar stort mellan uppgiftstyper. Denna inkonsekvens är det främsta förbättringsområdet—större enhetlighet i resonemangsvisning skulle ytterligare öka modellens utbildnings- och samarbetsvärde.
Sammantaget, med ett samlat betyg på 9,2/10, framstår Gemini 2.0 Thinking som ett mycket kapabelt AI-system med den extra fördelen av processynlighet, vilket gör det särskilt lämpligt för tillämpningar där förståelsen av resonemangsvägen är lika viktig som slutresultatet.
Vanliga frågor
Vad är Gemini 2.0 Thinking?
Gemini 2.0 Thinking är en experimentell AI-modell från Google som exponerar sina resonemangsprocesser och erbjuder transparens i hur den löser problem inom olika uppgifter såsom innehållsgenerering, beräkning, sammanfattning och analytiskt skrivande.
Vad särskiljer Gemini 2.0 Thinking från andra AI-modeller?
Dess unika 'tänkartransparens' låter användare se verktygsanvändning, resonemangs-steg och problemlösningsstrategier, vilket ökar förtroendet och ger utbildningsvärde, särskilt i forsknings- och samarbetsmiljöer.
Hur utvärderades Gemini 2.0 Thinking i denna analys?
Modellen testades på fem viktiga uppgiftstyper: innehållsgenerering, beräkning, sammanfattning, jämförelse och kreativt/analytiskt skrivande, med mätvärden som bearbetningstid, outputkvalitet och synliggörande av resonemang.
Vilka är huvudstyrkorna hos Gemini 2.0 Thinking?
Styrkor inkluderar forskning från flera källor, hög beräkningsprecision, snabb sammanfattning, välstrukturerade jämförelser, omfattande analys och exceptionell processynlighet.
Vilka områden behöver förbättras i Gemini 2.0 Thinking?
Modellen skulle vinna på mer konsekvent transparens i visningen av resonemang över alla uppgiftstyper samt tydligare loggar över verktygsanvändning i samtliga scenarier.
Arshia är en AI-arbetsflödesingenjör på FlowHunt. Med en bakgrund inom datavetenskap och en passion för AI, specialiserar han sig på att skapa effektiva arbetsflöden som integrerar AI-verktyg i vardagliga uppgifter, vilket förbättrar produktivitet och kreativitet.
Arshia Kahani
AI-arbetsflödesingenjör
Redo att uppleva transparent AI-resonemang?
Upptäck hur processynlighet och avancerat resonemang i Gemini 2.0 Thinking kan lyfta dina AI-lösningar. Boka en demo eller prova FlowHunt idag.
Gemini 2.5 Pro Preview: Prestandaanalys över Nyckeluppgifter
En omfattande granskning av Googles Gemini 2.5 Pro Preview, där dess verkliga prestanda utvärderas över fem nyckeluppgifter, inklusive innehållsgenerering, affä...
Utforska tankeprocessen, arkitekturen och beslutsfattandet hos Gemini 1.5 Pro, en mångsidig AI-agent, genom verkliga uppgifter och djupgående analys av dess res...
10 min läsning
AI Agents
Reasoning
+5
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.