

Promptteknik
Promptteknik är praxis att utforma och förfina indata för generativa AI-modeller för att producera optimala resultat. Detta innebär att skapa precisa och effekt...
2 min läsning
Prompt Engineering
AI
+4

Bemästra promptoptimering för AI genom att skapa tydliga, kontextuella prompts som höjer outputkvaliteten, minskar kostnader och kortar bearbetningstiden. Utforska tekniker för smartare AI-arbetsflöden.
Promptoptimering innebär att förfina det input du ger till en AI-modell så att den levererar så exakta och effektiva svar som möjligt. Det handlar inte bara om tydlig kommunikation—optimerade prompts minskar också den beräkningsmässiga belastningen, vilket leder till snabbare bearbetningstider och lägre kostnader. Oavsett om du skriver frågor till kundsupport-chatbots eller genererar komplexa rapporter spelar det roll hur du strukturerar och formulerar dina prompts.
Har du någonsin försökt få AI att skriva en metabeskrivning? Troligtvis såg din första prompt ut ungefär så här:
Skriv en metabeskrivning om ämnet promptoptimering.
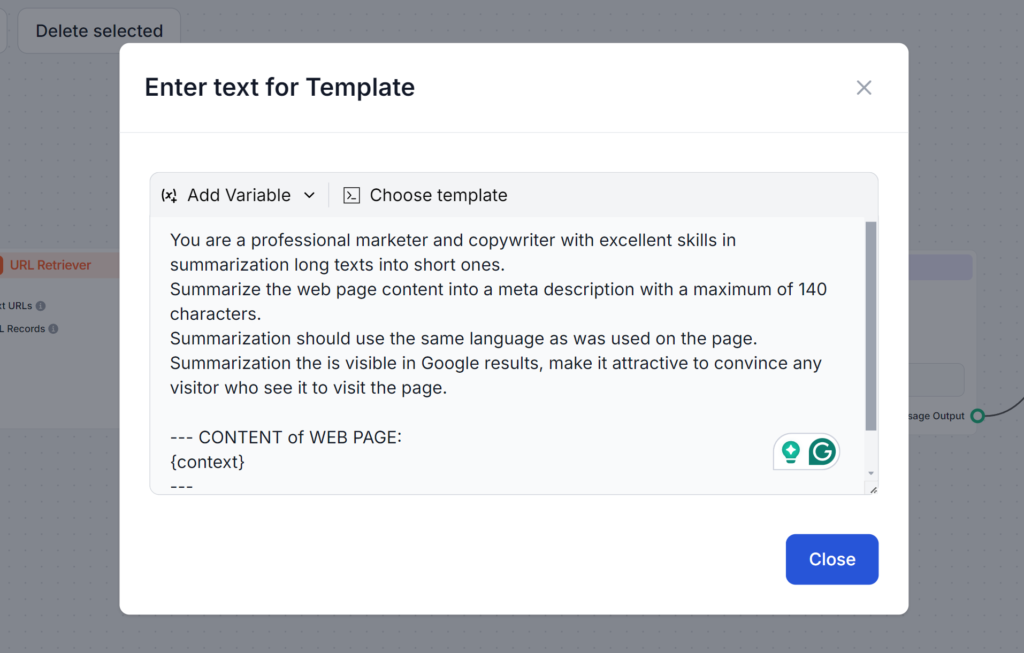
Den här prompten är fel av flera skäl. Om du inte specificerar längden på 140 tecken som Google kräver kommer AI:n gå långt över. Om den ändå får rätt längd använder den ofta en annan stil eller gör den för beskrivande och tråkig för att någon ska klicka. Slutligen, utan att få läsa din artikel kan den bara producera vaga metabeskrivningar.
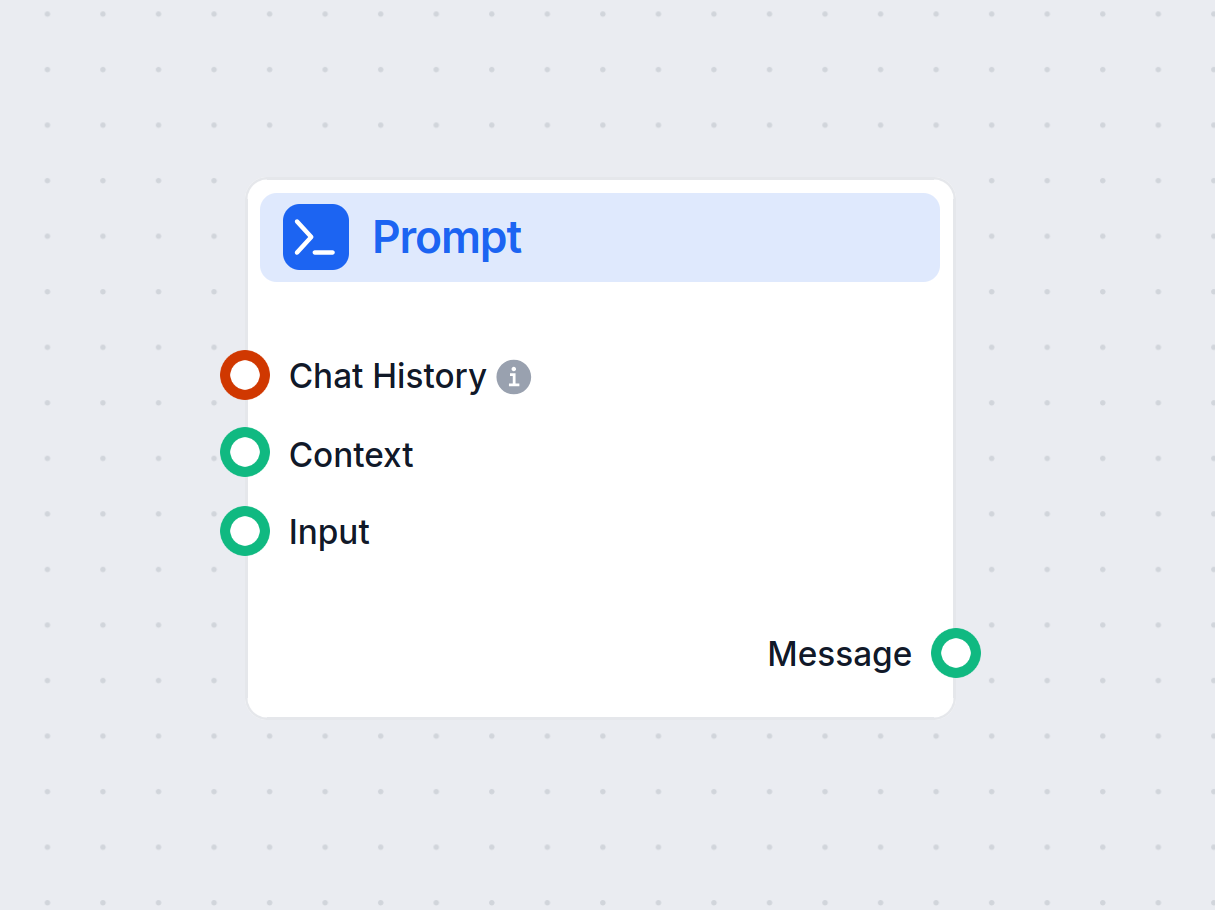
Se prompten nedan. Den är längre och använder flera tekniker som vi kommer lära oss om i denna blogg. Det som är bra med denna prompt är att den tar upp alla möjliga problem, vilket säkerställer att du får exakt det resultat du behöver på första försöket:
Tokens är byggstenarna i texten som AI-modeller bearbetar. Modellerna delar upp texten i dessa tokens. En token kan vara ett ord, flera ord eller till och med en del av ett ord. Fler tokens innebär vanligtvis långsammare svar och högre beräkningskostnader. Därför är det viktigt att förstå hur tokens fungerar för att göra prompts bättre och se till att de är kostnadseffektiva och snabba att köra.
Varför tokens är viktiga:
Till exempel:
I prompten med många tokens ombeds AI:n att gå in på alla möjliga alternativ, medan prompten med få tokens ber om en enkel översikt. Med översikten kan du sedan fördjupa dig efter behov och snabbare samt billigare nå ditt önskade resultat.
Att skapa effektiva prompts kräver en blandning av tydlighet, kontext och kreativitet. Det rekommenderas att testa olika format för att upptäcka de mest effektiva sätten att prompta AI. Här är några viktiga tekniker:
Otydliga prompts kan förvirra modellen. En välstrukturerad prompt försäkrar att AI:n förstår din avsikt.
Exempel:
Att inkludera relevanta detaljer hjälper AI:n att generera svar som är anpassade efter dina behov.
Exempel:
Att lägga till exempel guidar AI:n att förstå vilket format eller vilken ton du vill ha.
Exempel:
Att använda standardiserade mallar för liknande uppgifter ger konsekvens och sparar tid.
Exempel på mall för blogginlägg:
“Skriv ett blogginlägg på [antal ord] om [ämne], med fokus på [specifika detaljer]. Använd en vänlig ton och inkludera [nyckelord].”
Flera avancerade strategier kan hjälpa dig att ta dina prompts till nästa nivå. Dessa tekniker går utöver grundläggande tydlighet och struktur, och låter dig hantera mer komplexa uppgifter, integrera dynamisk data och anpassa AI-svar till specifika områden eller behov. Här är en kort översikt över hur varje teknik fungerar, med praktiska exempel som vägledning.
Few-shot learning handlar om att ge ett fåtal exempel i din prompt för att hjälpa AI:n att förstå det mönster eller format du vill ha. Det gör att modellen kan generalisera effektivt med minimal data, vilket är perfekt för nya eller obekanta uppgifter.
Ge helt enkelt några exempel i din prompt för att hjälpa modellen att förstå dina förväntningar.
Exempel på prompt:
Översätt följande fraser till franska:
Prompt chaining innebär att bryta ned komplexa uppgifter i mindre, hanterbara steg som bygger på varandra. Denna metod gör att AI:n kan ta sig an flerstegsproblem på ett systematiskt sätt, vilket ger tydlighet och precision i resultatet.
Exempel på prompt:
Kontextuell hämtning integrerar relevant, uppdaterad information i prompten genom att hänvisa till externa källor eller sammanfatta viktiga detaljer. På så sätt ger du AI:n tillgång till korrekt och aktuell data för mer informerade svar.
Exempel:
“Använd data från denna rapport [infoga länk], och sammanfatta de viktigaste resultaten om förnybar energi [trender.”
Finjustering med embeddings anpassar AI-modellen till specifika uppgifter eller områden med hjälp av specialanpassade datarepresentationer. Denna anpassning ökar relevansen och noggrannheten i svaren för nischade eller branschspecifika tillämpningar.
Att hantera tokenanvändning gör att du kan styra hur snabbt och kostnadseffektivt AI hanterar in- och utdata. Genom att minska antalet bearbetade tokens kan du spara kostnader och få snabbare svarstider utan att tumma på kvaliteten. Här är tekniker för att hantera tokens effektivt:
Optimering slutar inte vid att skriva bättre prompts. Följ regelbundet upp prestandan och iterera baserat på feedback. Denna kontinuerliga uppföljning möjliggör stadig förbättring och ger dig chansen att fatta välgrundade beslut.
Fokusera på dessa nyckelområden:
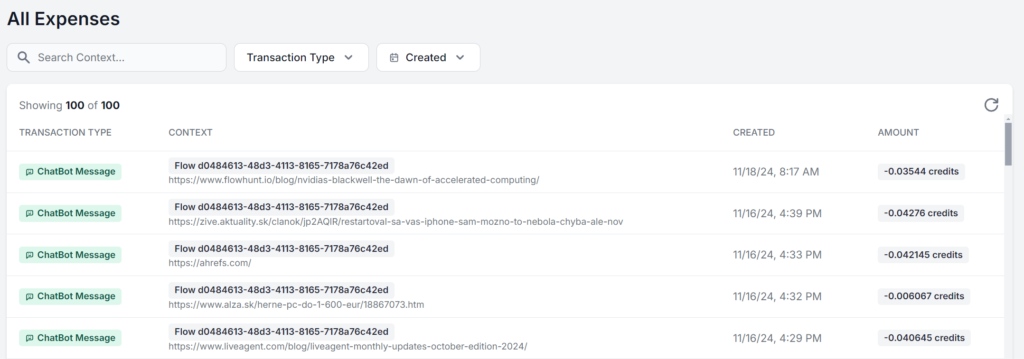
Det bästa är att arbeta i ett gränssnitt där du kan se och analysera din exakta användning för varje prompt. Här körs samma FlowHunt AI-arbetsflöde 5 gånger med endast källmaterialet förändrat. Skillnaden i kostnad är bara några ören, men när nya avgifter ackumuleras blir skillnaden snabbt märkbar:
Oavsett om du vill få ut det mesta av den fria AI-gränsen eller bygger din AI-strategi i stor skala är promptoptimering avgörande för alla som använder AI. Dessa tekniker gör att du kan använda AI effektivt, få exakta resultat och sänka kostnaderna.
I takt med att AI-teknologin utvecklas kommer vikten av tydlig och optimerad kommunikation med modeller bara att öka. Börja experimentera med dessa strategier redan idag – helt gratis. Med FlowHunt kan du bygga med olika AI-modeller och funktioner i en och samma dashboard, vilket ger optimerade och effektiva AI-arbetsflöden för alla uppgifter. Prova 14 dagars gratisperiod!
Promptoptimering innebär att förfina det input du ger till en AI-modell så att den levererar så exakta och effektiva svar som möjligt. Optimerade prompts minskar den beräkningsmässiga belastningen, vilket leder till snabbare bearbetningstider och lägre kostnader.
Antalet tokens påverkar både hastigheten och kostnaden för AI-resultat. Färre tokens ger snabbare svar och lägre kostnader, medan koncisa prompts hjälper modellerna att fokusera på relevanta detaljer.
Avancerade tekniker inkluderar few-shot learning, prompt chaining, kontextuell hämtning och finjustering med embeddings. Dessa metoder hjälper till att lösa komplexa uppgifter, integrera dynamisk data och anpassa svar till särskilda behov.
Övervaka svarens exakthet, tokenanvändning och bearbetningstider. Regelbunden uppföljning och iteration baserat på feedback hjälper till att förfina prompts och bibehålla effektivitet.
FlowHunt erbjuder verktyg och en dashboard för att bygga, testa och optimera AI-prompter, så att du kan experimentera med olika modeller och strategier för effektiva AI-arbetsflöden.
Maria är copywriter på FlowHunt. En språkentusiast aktiv i litterära kretsar, hon är fullt medveten om att AI förändrar hur vi skriver. Istället för att motarbeta utvecklingen vill hon hjälpa till att definiera den perfekta balansen mellan AI-arbetsflöden och det oersättliga värdet av mänsklig kreativitet.
Börja bygga optimerade AI-arbetsflöden med FlowHunt. Experimentera med prompt engineering och öka din produktivitet.
Promptteknik är praxis att utforma och förfina indata för generativa AI-modeller för att producera optimala resultat. Detta innebär att skapa precisa och effekt...
En metaprompt inom artificiell intelligens är en hög-nivå-instruktion utformad för att generera eller förbättra andra prompts för stora språkmodeller (LLM), vil...
Lär dig hur FlowHunts Prompt-komponent låter dig definiera din AI-bots roll och beteende, vilket säkerställer relevanta och personliga svar. Anpassa prompts och...