Wan 2.1: Den öppna AI-videogenereringens revolution
Wan 2.1 är en kraftfull öppen AI-videogenereringsmodell från Alibaba som levererar studiokvalitet på videor från text eller bilder, fritt för alla att använda lokalt.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Vad är Wan 2.1?
Wan 2.1 (även kallad WanX 2.1) bryter ny mark som en helt öppen AI-videogenereringsmodell utvecklad av Alibabas Tongyi Lab. Till skillnad från många proprietära videogenereringssystem som kräver dyra prenumerationer eller API-åtkomst, levererar Wan 2.1 jämförbar eller överlägsen kvalitet samtidigt som den är helt gratis och tillgänglig för utvecklare, forskare och kreativa yrkespersoner.
Det som gör Wan 2.1 verkligt speciell är dess kombination av tillgänglighet och prestanda. Den mindre T2V-1.3B-varianten kräver bara ~8,2 GB GPU-minne, vilket gör den kompatibel med de flesta moderna konsument-GPU:er. Samtidigt levererar den större 14B-varianten topprestanda som överträffar både öppna alternativ och många kommersiella modeller på standardiserade benchmarktester.
Nyckelfunktioner som särskiljer Wan 2.1
Stöd för flera uppgifter
Wan 2.1 är inte bara begränsad till text-till-video-generering. Dess mångsidiga arkitektur stöder:
Text-till-video (T2V)
Bild-till-video (I2V)
Video-till-video-redigering
Text-till-bild-generering
Video-till-ljud-generering
Denna flexibilitet innebär att du kan börja med en textprompt, en stillbild eller till och med en befintlig video och omvandla den efter din kreativa vision.
Flerspråkig textgenerering
Som den första videomodellen som kan rendera läsbar engelsk och kinesisk text i genererade videor, öppnar Wan 2.1 nya möjligheter för internationella innehållsskapare. Denna funktion är särskilt värdefull för att skapa undertexter eller scen-text i flerspråkiga videor.
Revolutionerande Video VAE (Wan-VAE)
Kärnan i Wan 2.1:s effektivitet är dess 3D-kausala Video Variational Autoencoder. Detta teknologiska genombrott komprimerar effektivt rumslig och tidsmässig information, vilket gör att modellen kan:
Komprimera videor hundratals gånger i storlek
Bevara rörelse- och detaljtrohet
Stödja högupplösta utdata upp till 1080p
Enastående effektivitet och tillgänglighet
Den mindre 1.3B-modellen kräver bara 8,19 GB VRAM och kan producera en 5-sekunders, 480p-video på ungefär 4 minuter med en RTX 4090. Trots denna effektivitet matchar eller överträffar dess kvalitet betydligt större modeller, vilket gör den till den perfekta balansen mellan hastighet och visuell trohet.
Branschledande benchmark och kvalitet
I offentliga utvärderingar uppnådde Wan 14B det högsta totala resultatet i Wan-Bench-tester och överträffade konkurrenter inom:
Rörelsekvalitet
Stabilitet
Precision i promptuppföljning
Hur Wan 2.1 står sig jämfört med andra videogenereringsmodeller
Till skillnad från slutna system som OpenAI:s Sora eller Runways Gen-2 är Wan 2.1 fritt tillgänglig att köra lokalt. Den överträffar generellt tidigare öppna modeller (som CogVideo, MAKE-A-VIDEO och Pika) och till och med många kommersiella lösningar i kvalitetsbenchmark.
En nyligen genomförd branschundersökning noterade att ”bland många AI-videomodeller utmärker sig Wan 2.1 och Sora” – Wan 2.1 för sin öppenhet och effektivitet, och Sora för sin proprietära innovation. I communitytester har användare rapporterat att Wan 2.1:s bild-till-video-förmåga överträffar konkurrenterna vad gäller skärpa och filmkänsla.
Teknologin bakom Wan 2.1
Wan 2.1 bygger på en diffusion-transformer-backbone med en ny spatio-temporal VAE. Så här fungerar det:
En inmatning (text och/eller bild/video) kodas till en latent videorepresentation av Wan-VAE
En diffusionstransformer (baserad på DiT-arkitekturen) avbrusar successivt denna latenta
Processen styrs av textkodaren (en flerspråkig T5-variant kallad umT5)
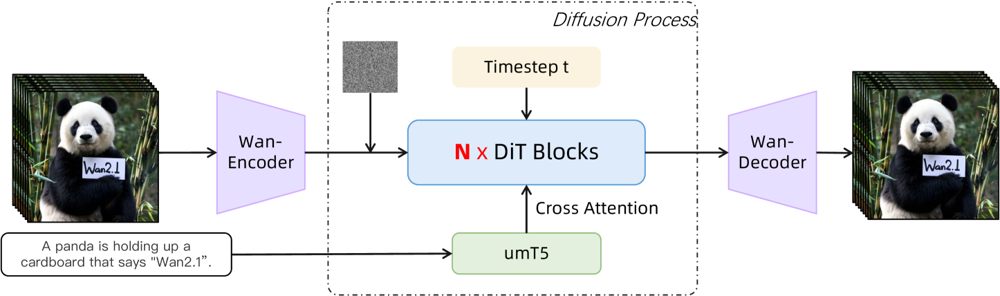
Figur: Wan 2.1:s övergripande arkitektur (text-till-video-fallet). En video (eller bild) kodas först av Wan-VAE-kodaren till en latent. Denna latenta skickas sedan genom N diffusionstransformerblock, som uppmärksammar textinbäddningen (från umT5) via cross-attention. Slutligen rekonstruerar Wan-VAE-dekodern videoramarna. Denna design – med en ”3D-kausal VAE-kodare/dekoder runt en diffusionstransformer” (ar5iv.org) – möjliggör effektiv komprimering av spatio-temporala data och stödjer högkvalitativ videooutput.
Denna innovativa arkitektur — med en ”3D-kausal VAE-kodare/dekoder runt en diffusionstransformer” — möjliggör effektiv komprimering av spatio-temporala data och stödjer högkvalitativ videooutput.
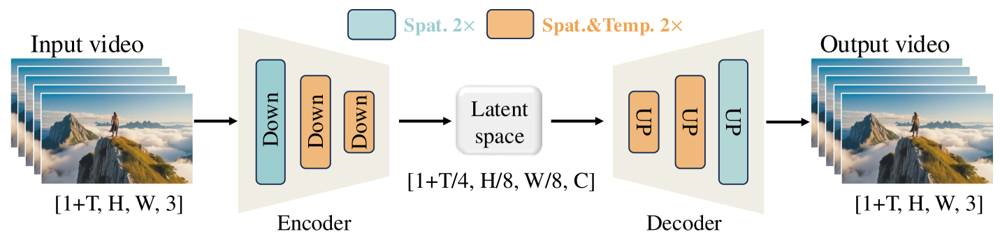
Wan-VAE är särskilt utformad för videor. Den komprimerar inmatningen med imponerande faktorer (temporalt 4× och rumsligt 8×) till en kompakt latent innan den dekodas tillbaka till full video. Användningen av 3D-konvolutioner och kausala (tidsbevarande) lager säkerställer koherent rörelse genom hela det genererade innehållet.
Figur: Wan 2.1:s Wan-VAE-ramverk (kodare-dekoder). Wan-VAE-kodaren (vänster) tillämpar en serie nedskalningslager (“Down”) på inmatningsvideon (form [1+T, H, W, 3] ramar) tills den når en kompakt latent ([1+T/4, H/8, W/8, C]). Wan-VAE-dekodern (höger) uppsamplar (“UP”) denna latent symmetriskt tillbaka till ursprungliga videoramar. Blå block indikerar rumslig komprimering och orange block kombinerad rumslig+temporal komprimering (ar5iv.org). Genom att komprimera videon 256× (i spatio-temporal volym) gör Wan-VAE högupplöst videomodellering möjlig för den efterföljande diffusionsmodellen.
Så kör du Wan 2.1 på din egen dator
Redo att prova Wan 2.1 själv? Så här kommer du igång:
Systemkrav
Python 3.8+
PyTorch ≥2.4.0 med CUDA-stöd
NVIDIA-GPU (8GB+ VRAM för 1.3B-modellen, 16-24GB för 14B-modeller)
Ytterligare bibliotek från repot
Installationssteg
Klona repot och installera beroenden:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
Prestandatips
För maskiner med begränsat GPU-minne, testa den lättare t2v-1.3B-modellen
Använd flaggorna --offload_model True --t5_cpu för att flytta delar av modellen till CPU
Styr bildförhållandet med parametern --size (t.ex. 832*480 för 16:9 480p)
Wan 2.1 erbjuder promptförlängning och ”inspirationsläge” via ytterligare alternativ
Till referens kan en RTX 4090 generera en 5-sekunders 480p-video på cirka 4 minuter. Multi-GPU-installationer och olika prestandaoptimeringar (FSDP, kvantisering, etc.) stöds för storskalig användning.
Därför är Wan 2.1 viktig för framtidens AI-video
Som en öppen kraftmätare som utmanar jättarna inom AI-videogenerering representerar Wan 2.1 ett betydande skifte i tillgänglighet. Dess fria och öppna natur innebär att alla med ett hyfsat GPU kan utforska den senaste videoteknologin utan abonnemangsavgifter eller API-kostnader.
För utvecklare möjliggör den öppna licensen anpassning och förbättring av modellen. Forskare kan utöka dess kapabiliteter, medan kreativa yrkespersoner snabbt och effektivt kan skapa videoinnehåll.
I en tid där proprietära AI-modeller alltmer låses bakom betalväggar visar Wan 2.1 att topprestanda kan demokratiseras och delas med det bredare samhället.
Vanliga frågor
Vad är Wan 2.1?
Wan 2.1 är en helt öppen AI-videogenereringsmodell utvecklad av Alibabas Tongyi Lab, kapabel att skapa högkvalitativa videor från textpromptar, bilder eller befintliga videor. Den är gratis att använda, stöder flera uppgifter och körs effektivt på konsument-GPU:er.
Vilka funktioner gör Wan 2.1 unik?
Wan 2.1 stöder multitask-videogenerering (text-till-video, bild-till-video, videoredigering m.m.), flerspråkig textrendering i videor, hög effektivitet med sin 3D-kausala Video VAE, och överträffar många kommersiella och öppna modeller i benchmarktester.
Hur kan jag köra Wan 2.1 på min egen dator?
Du behöver Python 3.8+, PyTorch 2.4.0+ med CUDA och ett NVIDIA-GPU (8GB+ VRAM för den mindre modellen, 16-24GB för den stora modellen). Klona GitHub-repot, installera beroenden, ladda ner modellvikterna och använd de medföljande skripten för att generera videor lokalt.
Varför är Wan 2.1 viktig för AI-videogenerering?
Wan 2.1 demokratiserar tillgången till den senaste videoteknologin genom att vara öppen och gratis, vilket gör det möjligt för utvecklare, forskare och kreatörer att experimentera och innovera utan betalväggar eller proprietära begränsningar.
Hur står sig Wan 2.1 jämfört med modeller som Sora eller Runway Gen-2?
Till skillnad från slutna alternativ som Sora eller Runway Gen-2 är Wan 2.1 helt öppen källkod och kan köras lokalt. Den överträffar generellt tidigare öppna modeller och matchar eller överträffar många kommersiella lösningar i kvalitetsbenchmark.
Arshia är en AI-arbetsflödesingenjör på FlowHunt. Med en bakgrund inom datavetenskap och en passion för AI, specialiserar han sig på att skapa effektiva arbetsflöden som integrerar AI-verktyg i vardagliga uppgifter, vilket förbättrar produktivitet och kreativitet.
Arshia Kahani
AI-arbetsflödesingenjör
Testa FlowHunt och bygg AI-lösningar
Börja bygga egna AI-verktyg och videogenereringsflöden med FlowHunt eller boka en demo för att se plattformen i aktion.
Gemini Flash 2.0 sätter nya standarder inom AI med förbättrad prestanda, hastighet och multimodala möjligheter. Utforska dess potential i verkliga applikationer...
Integrera FlowHunt med WavespeedMCP för att automatisera avancerade AI-baserade arbetsflöden för bild- och videoproduktion. Lås upp text-till-bild, bild-till-bi...
Integrera FlowHunt med json2video-mcp-servern för att automatisera programmatisk videogenerering, hantera anpassade mallar och koppla videoflöden till agenter, ...
4 min läsning
AI
Video Automation
+3
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.