Insight Engine
Upptäck vad en Insight Engine är—en avancerad, AI-driven plattform som förbättrar datasökning och analys genom att förstå kontext och avsikt. Lär dig hur Insigh...
10 min läsning
AI
Insight Engine
+5

AI-sökning utnyttjar maskininlärning och vektorembeddings för att förstå sökavsikt och kontext, och levererar mycket relevanta resultat bortom exakta nyckelordsöverensstämmelser.
AI-sökning använder maskininlärning för att förstå kontext och avsikt bakom sökfrågor, och omvandlar dem till numeriska vektorer för mer exakta resultat. Till skillnad från traditionella nyckelordssökningar tolkar AI-sökning semantiska relationer, vilket gör den effektiv för olika datatyper och språk.
AI-sökning, ofta kallad semantisk eller vektorsökning, är en sökmetodologi som utnyttjar maskininlärningsmodeller för att förstå avsikten och den kontextuella betydelsen bakom sökfrågor. Till skillnad från traditionell sökning baserad på nyckelord omvandlar AI-sökning data och frågor till numeriska representationer som kallas vektorer eller embeddings. Detta gör att sökmotorn kan förstå de semantiska relationerna mellan olika datadelar, och levererar mer relevanta och exakta resultat även när exakta nyckelord saknas.
AI-sökning representerar en betydande utveckling inom sökteknologier. Traditionella sökmotorer förlitar sig starkt på nyckelordsöverensstämmelser, där förekomsten av specifika termer i både frågan och dokumenten avgör relevansen. AI-sökning använder däremot maskininlärningsmodeller för att förstå den underliggande kontexten och betydelsen i frågor och data.
Genom att omvandla text, bilder, ljud och annan ostrukturerad data till högdimensionella vektorer kan AI-sökning mäta likheten mellan olika innehållsdelar. Detta tillvägagångssätt gör det möjligt för sökmotorn att leverera resultat som är kontextuellt relevanta, även om de inte innehåller de exakta nyckelorden som används i sökfrågan.
Nyckelkomponenter:
I hjärtat av AI-sökning ligger begreppet vektorembeddings. Vektorembeddings är numeriska representationer av data som fångar den semantiska betydelsen av text, bilder eller andra datatyper. Dessa embeddings placerar liknande datadelar nära varandra i ett mångdimensionellt vektorrum.
Så fungerar det:
Exempel:
Traditionella sökmotorer baserade på nyckelord fungerar genom att matcha termer i sökfrågan med dokument som innehåller dessa termer. De förlitar sig på tekniker som inverterade index och termfrekvens för att ranka resultaten.
Begränsningar med nyckelordsbaserad sökning:
Fördelar med AI-sökning:
| Aspekt | Nyckelordsbaserad sökning | AI-sökning (Semantisk/Vektor) |
|---|---|---|
| Matchning | Exakta nyckelordsöverensstämmelser | Semantisk likhet |
| Kontextmedvetenhet | Begränsad | Hög |
| Hantering av synonymer | Kräver manuella synonymlistor | Automatiskt via embeddings |
| Stavfel | Kan misslyckas utan fuzzy search | Mer tolerant tack vare semantisk kontext |
| Förståelse av avsikt | Minimal | Betydande |
Semantisk sökning är en kärnapplikation av AI-sökning som fokuserar på att förstå användarens avsikt och den kontextuella betydelsen av frågor.
Process:
Nyckeltekniker:
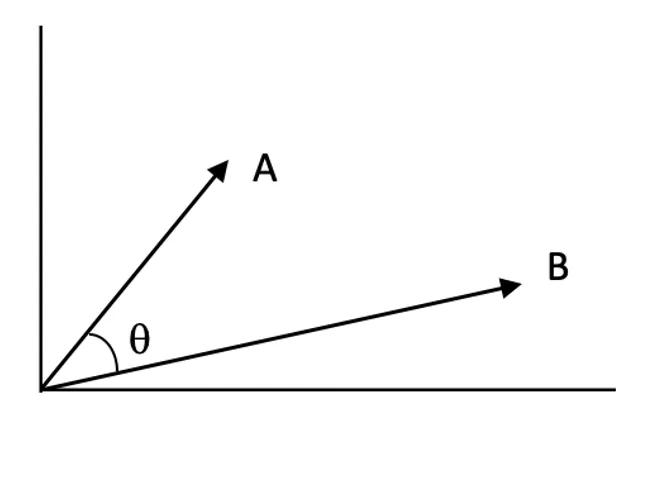
Likhetspoäng:
Likhetspoäng kvantifierar hur nära två vektorer är varandra i vektorrummet. Högre poäng indikerar högre relevans mellan frågan och ett dokument.
Approximate Nearest Neighbor (ANN)-algoritmer:
Att hitta exakta närmaste grannar i högdimensionella rum är beräkningsintensivt. ANN-algoritmer ger effektiva approximationer.
AI-sökning öppnar ett brett utbud av applikationer inom olika branscher tack vare dess förmåga att förstå och tolka data bortom enkel nyckelordsöverensstämmelse.
Beskrivning: Semantisk sökning förbättrar användarupplevelsen genom att tolka avsikten bakom frågor och leverera kontextuellt relevanta resultat.
Exempel:
Beskrivning: Genom att förstå användarpreferenser och beteende kan AI-sökning ge personliga innehålls- eller produktrekommendationer.
Exempel:
Beskrivning: AI-sökning gör det möjligt för system att förstå och besvara användarfrågor med exakt information hämtad från dokument.
Exempel:
Beskrivning: AI-sökning kan indexera och söka i ostrukturerade datatyper som bilder, ljud och video genom att omvandla dem till embeddings.
Exempel:
Att integrera AI-sökning i AI-automation och chattbottar höjer deras kapacitet avsevärt.
Fördelar:
Implementeringssteg:
Användningsexempel:
Även om AI-sökning erbjuder många fördelar finns det utmaningar att ta hänsyn till:
Åtgärdsstrategier:
Semantisk och vektorsökning inom AI har blivit kraftfulla alternativ till traditionell nyckelordsbaserad och fuzzy-sökning, vilket avsevärt förbättrar relevansen och noggrannheten i sökresultat genom att förstå kontext och betydelse bakom frågor.
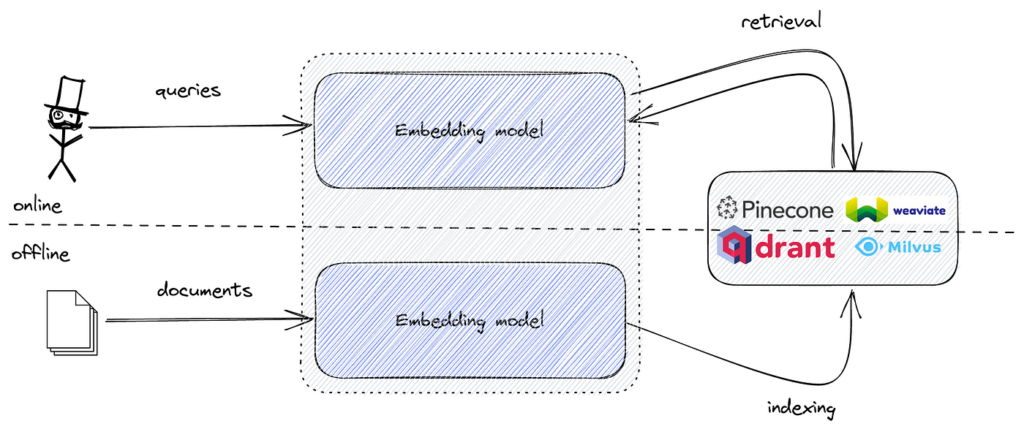
Vid implementering av semantisk sökning omvandlas textdata till vektorembeddings som fångar den semantiska betydelsen av texten. Dessa embeddings är högdimensionella numeriska representationer. För att effektivt kunna söka bland dessa embeddings och hitta de mest liknande till en frågeembedding behövs ett verktyg som är optimerat för likhetssökning i högdimensionella rum.
FAISS tillhandahåller nödvändiga algoritmer och datastrukturer för att utföra denna uppgift effektivt. Genom att kombinera semantiska embeddings med FAISS kan vi skapa en kraftfull semantisk sökmotor som klarar stora datamängder med låg latens.
Att implementera semantisk sökning med FAISS i Python innebär flera steg:
Låt oss gå igenom varje steg i detalj.
Förbered din datamängd (t.ex. artiklar, supportärenden, produktbeskrivningar).
Exempel:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Rensa och formatera textdatan vid behov.
Omvandla textdatan till vektorembeddings med hjälp av förtränade Transformer-modeller från bibliotek som Hugging Face (transformers eller sentence-transformers).
Exempel:
from sentence_transformers import SentenceTransformer
import numpy as np
# Ladda en förtränad modell
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generera embeddings för alla dokument
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 enligt FAISS:s krav.Skapa ett FAISS-index för att lagra embeddings och möjliggöra effektiv likhetssökning.
Exempel:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 utför brute-force-sökning med L2 (euklidiskt avstånd).Omvandla användarens fråga till en embedding och hitta de närmaste grannarna.
Exempel:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Använd indexen för att visa de mest relevanta dokumenten.
Exempel:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Förväntad utdata:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS erbjuder flera typer av index:
Använda ett inverterat filindex (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalisering och innerproduktssökning:
Att använda cosinuslikhet kan vara mer effektivt för textdata
AI-sökning är en modern sökmetod som använder maskininlärning och vektorembeddings för att förstå avsikten och den kontextuella betydelsen av frågor, vilket ger mer exakta och relevanta resultat än traditionell sökning baserad på nyckelord.
Till skillnad från nyckelordsbaserad sökning, som förlitar sig på exakta överensstämmelser, tolkar AI-sökning de semantiska relationerna och avsikten bakom frågor, vilket gör den effektiv för naturligt språk och tvetydiga indata.
Vektorembeddings är numeriska representationer av text, bilder eller andra datatyper som fångar deras semantiska betydelse och gör det möjligt för sökmotorn att mäta likhet och kontext mellan olika datadelar.
AI-sökning driver semantisk sökning inom e-handel, personliga rekommendationer inom streaming, frågesvarssystem inom kundsupport, bläddring i ostrukturerad data och dokumentåtervinning inom forskning och företag.
Populära verktyg inkluderar FAISS för effektiv vektorsimilaritetssökning, samt vektordatabaser som Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch och Pgvector för skalbar lagring och hämtning av embeddings.
Genom att integrera AI-sökning kan chattbottar och automatiseringssystem förstå användarfrågor djupare, hämta kontextuellt relevanta svar och leverera dynamiska, personliga svar.
Utmaningar inkluderar höga beräkningskrav, komplexitet i modelltolkning, behov av högkvalitativa data och att säkerställa integritet och säkerhet för känslig information.
FAISS är ett öppen källkods-bibliotek för effektiv likhetssökning på högdimensionella vektorembeddings, och används i stor utsträckning för att bygga semantiska sökmotorer som kan hantera stora datamängder.
Upptäck hur AI-driven semantisk sökning kan förändra din informationssökning, chattbottar och automatiseringsflöden.
Upptäck vad en Insight Engine är—en avancerad, AI-driven plattform som förbättrar datasökning och analys genom att förstå kontext och avsikt. Lär dig hur Insigh...
Facetterad sökning är en avancerad teknik som gör det möjligt för användare att förfina och navigera i stora datamängder genom att använda flera filter baserade...
Informationsåtervinning använder AI, NLP och maskininlärning för att effektivt och noggrant hämta data som uppfyller användarens krav. Grundläggande för webbsök...