MLflow
MLflow är en öppen plattform utformad för att effektivisera och hantera hela maskininlärningslivscykeln. Den erbjuder verktyg för experimentuppföljning, kodpake...
5 min läsning
MLflow
Machine Learning
+3
Kubeflow är en öppen ML-plattform byggd på Kubernetes som effektiviserar implementering, hantering och skalning av maskininlärningsarbetsflöden över olika infrastrukturer.
Kubeflows uppdrag är att göra skalning av ML-modeller och deras driftsättning i produktion så enkel som möjligt genom att utnyttja Kubernetes kapaciteter. Detta inkluderar enkla, repeterbara och portabla implementationer över olika infrastrukturer. Plattformen började som ett sätt att köra TensorFlow-jobb på Kubernetes och har sedan utvecklats till ett mångsidigt ramverk som stöder en mängd olika ML-ramverk och verktyg.
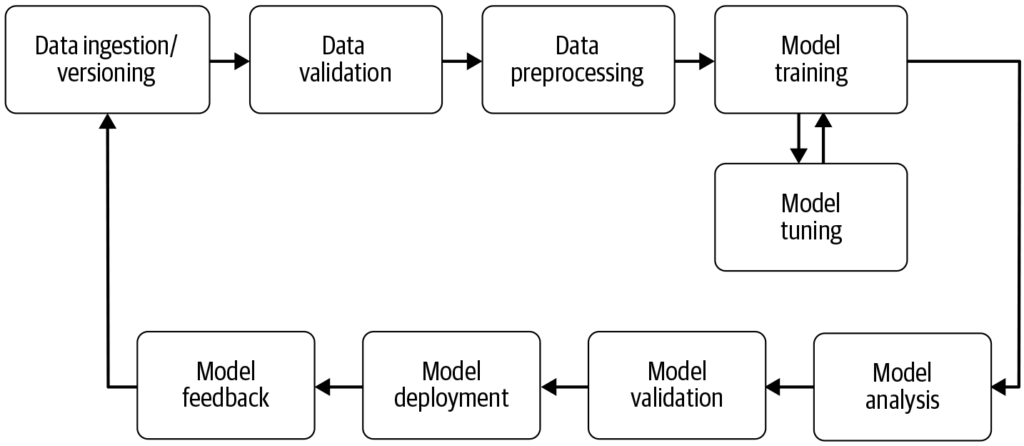
Kubeflow Pipelines är en kärnkomponent som gör det möjligt för användare att definiera och köra ML-arbetsflöden som riktade acykliska grafer (DAG). Den tillhandahåller en plattform för att bygga portabla och skalbara maskininlärningsarbetsflöden med Kubernetes. Pipelines-komponenten består av:
Dessa funktioner gör det möjligt för datavetare att automatisera hela processen från datapreprocessering, modellträning, utvärdering till driftsättning, vilket främjar reproducerbarhet och samarbete i ML-projekt. Plattformen stödjer återanvändning av komponenter och pipelines och effektiviserar därmed skapandet av ML-lösningar.
Kubeflows centrala dashboard fungerar som huvudgränssnittet för att komma åt Kubeflow och dess ekosystem. Den samlar användargränssnitten för olika verktyg och tjänster inom klustret och erbjuder en enhetlig åtkomstpunkt för att hantera maskininlärningsaktiviteter. Dashboarden erbjuder funktioner som användarautentisering, multi-användarisolering och resursstyrning.
Kubeflow integreras med Jupyter Notebooks och erbjuder en interaktiv miljö för datautforskning, experiment och modellutveckling. Notebooks stöder flera programmeringsspråk och gör det möjligt för användare att skapa och köra ML-arbetsflöden tillsammans.
Kubeflow Metadata är ett centraliserat register för att spåra och hantera metadata kopplade till ML-experiment, körningar och artefakter. Det säkerställer reproducerbarhet, samarbete och styrning över ML-projekt genom att erbjuda en konsekvent vy av ML-metadata.
Katib är en komponent för automatiserad maskininlärning (AutoML) inom Kubeflow. Den stöder hyperparametertuning, tidig stoppning och neurala arkitektursökningar och optimerar ML-modellernas prestanda genom att automatisera sökningen efter optimala hyperparametrar.
Kubeflow används av organisationer inom olika branscher för att effektivisera sina ML-processer. Några vanliga användningsområden är:
Spotify använder Kubeflow för att ge sina datavetare och ingenjörer möjlighet att utveckla och driftsätta maskininlärningsmodeller i stor skala. Genom att integrera Kubeflow med deras befintliga infrastruktur har Spotify effektiviserat sina ML-arbetsflöden, minskat tiden till marknad för nya funktioner och förbättrat effektiviteten i sina rekommendationssystem.
Kubeflow gör det möjligt för organisationer att skala sina ML-arbetsflöden upp eller ner efter behov och implementera dem över olika infrastrukturer, inklusive lokalt, i molnet och i hybrida miljöer. Denna flexibilitet undviker inlåsning till leverantör och möjliggör smidiga övergångar mellan olika beräkningsmiljöer.
Kubeflows komponentbaserade arkitektur underlättar reproduktion av experiment och modeller. Den tillhandahåller verktyg för versionshantering och spårning av datamängder, kod och modellparametrar, vilket säkerställer konsekvens och samarbete mellan datavetare.
Kubeflow är utformat för att vara utbyggbart och möjliggör integration med olika andra verktyg och tjänster, inklusive molnbaserade ML-plattformar. Organisationer kan anpassa Kubeflow med ytterligare komponenter och dra nytta av befintliga verktyg och arbetsflöden för att förbättra sitt ML-ekosystem.
Genom att automatisera många av de uppgifter som är förknippade med implementering och hantering av ML-arbetsflöden frigör Kubeflow tid för datavetare och ingenjörer att fokusera på mer värdeskapande arbete, såsom modellutveckling och optimering, vilket leder till ökad produktivitet och effektivitet.
Kubeflows integration med Kubernetes möjliggör mer effektivt resursutnyttjande, optimerar tilldelning av hårdvaruresurser och minskar kostnaderna för att köra ML-arbetslaster.
För att börja använda Kubeflow kan användare implementera det på ett Kubernetes-kluster, antingen lokalt eller i molnet. Olika installationsguider finns tillgängliga och vänder sig till olika kunskapsnivåer och infrastrukturkrav. För den som är ny på Kubernetes erbjuder hanterade tjänster som Vertex AI Pipelines en mer lättillgänglig startpunkt, där infrastrukturhanteringen tas om hand och användarna kan fokusera på att bygga och köra ML-arbetsflöden.
Denna detaljerade genomgång av Kubeflow ger insikter i dess funktionalitet, fördelar och användningsområden och erbjuder en heltäckande förståelse för organisationer som vill förbättra sina maskininlärningsmöjligheter.
Kubeflow är ett öppen-källkodsprojekt utformat för att underlätta implementering, orkestrering och hantering av maskininlärningsmodeller på Kubernetes. Det tillhandahåller en komplett end-to-end-stack för arbetsflöden inom maskininlärning, vilket gör det enklare för datavetare och ingenjörer att bygga, implementera och hantera skalbara maskininlärningsmodeller.
Deployment of ML Models using Kubeflow on Different Cloud Providers
Författare: Aditya Pandey m.fl. (2022)
Denna artikel undersöker driftsättning av maskininlärningsmodeller med Kubeflow på olika molnplattformar. Studien ger insikter i installationsprocessen, driftsättningsmodeller och prestandamått för Kubeflow och fungerar som en användbar guide för nybörjare. Författarna lyfter fram verktygets funktioner och begränsningar samt demonstrerar dess användning för att skapa kompletta ML-pipelines. Artikeln syftar till att hjälpa användare med minimal Kubernetes-erfarenhet att utnyttja Kubeflow för modellimplementering.
Läs mer
CLAIMED, a visual and scalable component library for Trusted AI
Författare: Romeo Kienzler och Ivan Nesic (2021)
Detta arbete fokuserar på integration av pålitliga AI-komponenter med Kubeflow. Det behandlar frågor som förklarbarhet, robusthet och rättvisa i AI-modeller. Artikeln introducerar CLAIMED, ett återanvändbart komponentramverk som införlivar verktyg som AI Explainability360 och AI Fairness360 i Kubeflow-pipelines. Denna integration underlättar utvecklingen av produktionsklara ML-applikationer med visuella redigerare som ElyraAI.
Läs mer
Jet energy calibration with deep learning as a Kubeflow pipeline
Författare: Daniel Holmberg m.fl. (2023)
Kubeflow används för att skapa en ML-pipeline för kalibrering av jetenergi vid CMS-experimentet. Författarna använder djupa inlärningsmodeller för att förbättra kalibreringen av jetenergi och visar hur Kubeflows kapacitet kan utvidgas till tillämpningar inom högenergifysik. Artikeln diskuterar pipeline:ens effektivitet vid skalning av hyperparametertuning och servering av modeller effektivt på molnresurser.
Läs mer
Kubeflow är en öppen plattform byggd på Kubernetes som är utformad för att effektivisera implementering, hantering och skalning av arbetsflöden för maskininlärning. Den tillhandahåller en komplett uppsättning verktyg för hela ML-livscykeln.
Viktiga komponenter inkluderar Kubeflow Pipelines för orkestrering av arbetsflöden, en central dashboard, integration med Jupyter Notebooks, distribuerad modellträning och -servering, metadatahantering samt Katib för hyperparametertuning.
Genom att utnyttja Kubernetes möjliggör Kubeflow skalbara ML-arbetslaster över olika miljöer och tillhandahåller verktyg för experimentspårning och komponentåteranvändning, vilket säkerställer reproducerbarhet och effektivt samarbete.
Organisationer inom olika branscher använder Kubeflow för att hantera och skala sina ML-operationer. Användare som Spotify har integrerat Kubeflow för att effektivisera modellutveckling och implementering.
För att komma igång, implementera Kubeflow på ett Kubernetes-kluster – antingen lokalt eller i molnet. Installationsguider och hanterade tjänster finns tillgängliga för att hjälpa användare på alla kunskapsnivåer.
Upptäck hur Kubeflow kan förenkla dina maskininlärningsarbetsflöden på Kubernetes, från skalbar träning till automatiserad driftsättning.
MLflow är en öppen plattform utformad för att effektivisera och hantera hela maskininlärningslivscykeln. Den erbjuder verktyg för experimentuppföljning, kodpake...
En maskininlärningspipeline är ett automatiserat arbetsflöde som effektiviserar och standardiserar utveckling, träning, utvärdering och driftsättning av maskini...
Integrera FlowHunt med Metoro MCP Server för att ge AI-agenter realtidsövervakning av Kubernetes. Utnyttja eBPF-driven telemetri, Model Context Protocol och söm...