Textgenerering
Textgenerering med stora språkmodeller (LLMs) avser den avancerade användningen av maskininlärningsmodeller för att producera text som liknar mänskligt språk ut...
6 min läsning
AI
Text Generation
+5
llms.txt är en Markdown-fil som förenklar webbplatsinnehåll för LLM:er och förbättrar AI-drivna interaktioner genom att tillhandahålla ett strukturerat, maskinläsbart index.
Filen llms.txt är en standardiserad textfil i Markdown-format utformad för att förbättra hur stora språkmodeller (LLM:er) får åtkomst till, förstår och bearbetar information från webbplatser. Filen placeras i webbplatsens rot (t.ex. /llms.txt) och fungerar som ett kurerat index som tillhandahåller strukturerat och sammanfattat innehåll speciellt optimerat för maskinell konsumtion vid inferens. Det primära målet är att kringgå komplexiteten i traditionellt HTML-innehåll—såsom navigationsmenyer, annonser och JavaScript—genom att presentera tydliga, mänskliga och maskinläsbara data.
Till skillnad från andra webbstandarder som robots.txt eller sitemap.xml är llms.txt särskilt anpassad för resonemangsmotorer, såsom ChatGPT, Claude eller Google Gemini, snarare än sökmotorer. Den hjälper AI-system att hämta endast den mest relevanta och värdefulla informationen inom begränsningarna av deras kontextfönster, vilka ofta är för små för att hantera hela webbplatsens innehåll.
Konceptet föreslogs av Jeremy Howard, medgrundare av Answer.AI, i september 2024. Det uppstod som en lösning på ineffektiviteten som LLM:er möter vid interaktion med komplexa webbplatser. Traditionella metoder för bearbetning av HTML-sidor leder ofta till slöseri med beräkningsresurser och feltolkning av innehåll. Genom att skapa en standard som llms.txt kan webbplatsägare säkerställa att deras innehåll tolkas korrekt och effektivt av AI-system.
Filen llms.txt tjänar flera praktiska syften, främst inom artificiell intelligens och LLM-drivna interaktioner. Dess strukturerade format möjliggör effektiv hämtning och bearbetning av webbplatsinnehåll av LLM:er och övervinner begränsningar i kontextfönster och processhastighet.
Filen llms.txt följer ett specifikt Markdown-baserat schema för att säkerställa kompatibilitet för både människor och maskiner. Strukturen inkluderar:
Exempel:
# Exempelwebbplats
> En plattform för att dela kunskap och resurser om artificiell intelligens.
## Dokumentation
- [Snabbstartsguide](https://example.com/docs/quickstart.md): En nybörjarvänlig guide för att komma igång.
- [API-referens](https://example.com/docs/api.md): Detaljerad API-dokumentation.
## Policys
- [Användarvillkor](https://example.com/terms.md): Juridiska riktlinjer för användning av plattformen.
- [Integritetspolicy](https://example.com/privacy.md): Information om datahantering och användarens integritet.
## Optional
- [Företagets historia](https://example.com/history.md): En tidslinje över viktiga milstolpar och prestationer.
llms.txt för att dirigera AI-system till produkttaxonomier, returpolicys och storleksguider.FastHTML, ett Python-bibliotek för att bygga serverrenderade webbapplikationer, använder llms.txt för att förenkla åtkomsten till sin dokumentation. Filen inkluderar länkar till snabbstartsguider, HTMX-referenser och exempelapplikationer, vilket säkerställer att utvecklare snabbt kan hitta specifika resurser.
Exempelsnutt:
# FastHTML
> Ett Python-bibliotek för att skapa serverrenderade hypermedia-applikationer.
## Docs
- [Snabbstart](https://fastht.ml/docs/quickstart.md): Översikt över viktiga funktioner.
- [HTMX-referens](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Kompletta HTMX-attribut och metoder.
En e-handelsjätte som Nike skulle kunna använda en llms.txt-fil för att ge AI-system information om deras produktlinjer, hållbarhetsinitiativ och kundsupportspolicys.
Exempelsnutt:
# Nike
> Världsledande inom sportskor och kläder med fokus på hållbarhet och innovation.
## Produktlinjer
- [Löparskor](https://nike.com/products/running.md): Information om React-skum och Vaporweave-teknologier.
- [Hållbarhetsinitiativ](https://nike.com/sustainability.md): Mål för 2025 och miljövänliga material.
## Kundsupport
- [Returpolicy](https://nike.com/returns.md): 60 dagars returrätt och undantag.
- [Storleksguider](https://nike.com/sizing.md): Storlekstabeller för skor och kläder.
Även om alla tre standarder är utformade för att hjälpa automatiserade system skiljer sig deras syften och målgrupper avsevärt.
llms.txt:
robots.txt:
sitemap.xml:
robots.txt och sitemap.xml är llms.txt skapad för resonemangsmotorer, inte traditionella sökmotorer.llms.txt och llms-full.txt för hostad dokumentation.llms.txt.https://example.com/llms.txt).llms_txt2ctx för att säkerställa att standarden uppfylls.llms.txt eller llms-full.txt direkt (t.ex. Claude eller ChatGPT).llms.txt har fått genomslag bland utvecklare och mindre plattformar stöds den ännu inte officiellt av stora LLM-leverantörer som OpenAI eller Google.llms-full.txt överskrida vissa LLM:ers kontextfönster.Trots dessa utmaningar representerar llms.txt ett framåtblickande sätt att optimera innehåll för AI-drivna system. Genom att anta denna standard kan organisationer säkerställa att deras innehåll är tillgängligt, korrekt och prioriterat i en AI-först-värld.
Forskning: Stora språkmodeller (LLM:er)
Stora språkmodeller (LLM:er) har blivit en dominerande teknik för naturlig språkbehandling och driver applikationer som chattbottar, innehållsmoderering och sökmotorer. I “Lost in Translation: Large Language Models in Non-English Content Analysis” av Nicholas och Bhatia (2023) ger författarna en tydlig teknisk förklaring av hur LLM:er fungerar, lyfter fram skillnaden i datatillgång mellan engelska och andra språk samt diskuterar insatser för att överbrygga detta gap genom flerspråkiga modeller. Artikeln beskriver utmaningar med innehållsanalys med LLM:er, särskilt i flerspråkiga sammanhang, och ger rekommendationer till forskare, företag och beslutsfattare kring implementering och utveckling av LLM:er. Författarna betonar att även om framsteg har gjorts kvarstår betydande begränsningar för icke-engelska språk. Läs artikeln
Artikeln “Cedille: A large autoregressive French language model” av Müller och Laurent (2022) introducerar Cedille, en storskalig, franskspecifik språkmodell. Cedille är öppen källkod och visar överlägsen prestanda på franska zero-shot-benchmarks jämfört med befintliga modeller och rivaliserar till och med GPT-3 för flera uppgifter. Studien utvärderar även Cedilles säkerhet och visar förbättringar i toxicitet tack vare noggrann datasetfiltrering. Detta arbete belyser vikten av att utveckla LLM:er optimerade för specifika språk. Artikeln understryker behovet av språksspecifika resurser i LLM-landskapet. Läs artikeln
I “How Good are Commercial Large Language Models on African Languages?” av Ojo och Ogueji (2023) bedömer författarna kommersiella LLM:ers prestanda på afrikanska språk för både översättning och textklassificering. Resultaten visar att dessa modeller i allmänhet presterar sämre på afrikanska språk, med bättre resultat för klassificering än för översättning. Analysen omfattar åtta afrikanska språk från olika språkområden och familjer. Författarna efterlyser bättre representation av afrikanska språk i kommersiella LLM:er, med tanke på deras ökande användning. Studien belyser nuvarande brister och behovet av mer inkluderande språkmodellutveckling. Läs artikeln
“Goldfish: Monolingual Language Models for 350 Languages” av Chang m.fl. (2024) undersöker prestandan hos enspråkiga jämfört med flerspråkiga modeller för språk med begränsade resurser. Forskningen visar att stora flerspråkiga modeller ofta presterar sämre än enkla bigrammodeller för många språk, mätt med FLORES perplexity. Goldfish introducerar enspråkiga modeller tränade på 350 språk, vilket avsevärt förbättrar resultaten för språk med begränsade resurser. Författarna förespråkar mer riktad modellutveckling för underrepresenterade språk. Arbetet ger värdefulla insikter i nuvarande flerspråkiga LLM:ers begränsningar och potentialen hos enspråkiga alternativ. Läs artikeln
llms.txt är en standardiserad Markdown-fil som placeras i webbplatsens rot (t.ex. /llms.txt) och tillhandahåller ett kurerat index över innehåll optimerat för stora språkmodeller, vilket möjliggör effektiva AI-drivna interaktioner.
Till skillnad från robots.txt (för sökmotorcrawling) eller sitemap.xml (för indexering) är llms.txt utformad för LLM:er och erbjuder en förenklad, Markdown-baserad struktur för att prioritera värdefullt innehåll för AI-resonemang.
Den inkluderar en H1-rubrik (webbplatsens titel), en blockcitat-sammanfattning, detaljerade avsnitt för kontext, H2-avgränsade resurslistor med länkar och beskrivningar samt ett valfritt avsnitt för sekundära resurser.
llms.txt föreslogs av Jeremy Howard, medgrundare av Answer.AI, i september 2024 för att åtgärda ineffektiviteten i hur LLM:er bearbetar komplext webbplatsinnehåll.
llms.txt förbättrar LLM-effektiviteten genom att minska brus (t.ex. annonser, JavaScript), optimera innehållet för kontextfönster och möjliggöra korrekt tolkning för applikationer som teknisk dokumentation eller e-handel.
Den kan skrivas manuellt i Markdown eller genereras med verktyg som Mintlify eller Firecrawl. Valideringsverktyg som llms_txt2ctx säkerställer att standarden följs.
Lär dig implementera llms.txt med FlowHunt för att göra ditt innehåll AI-redo och förbättra interaktionen med stora språkmodeller.
Textgenerering med stora språkmodeller (LLMs) avser den avancerade användningen av maskininlärningsmodeller för att producera text som liknar mänskligt språk ut...
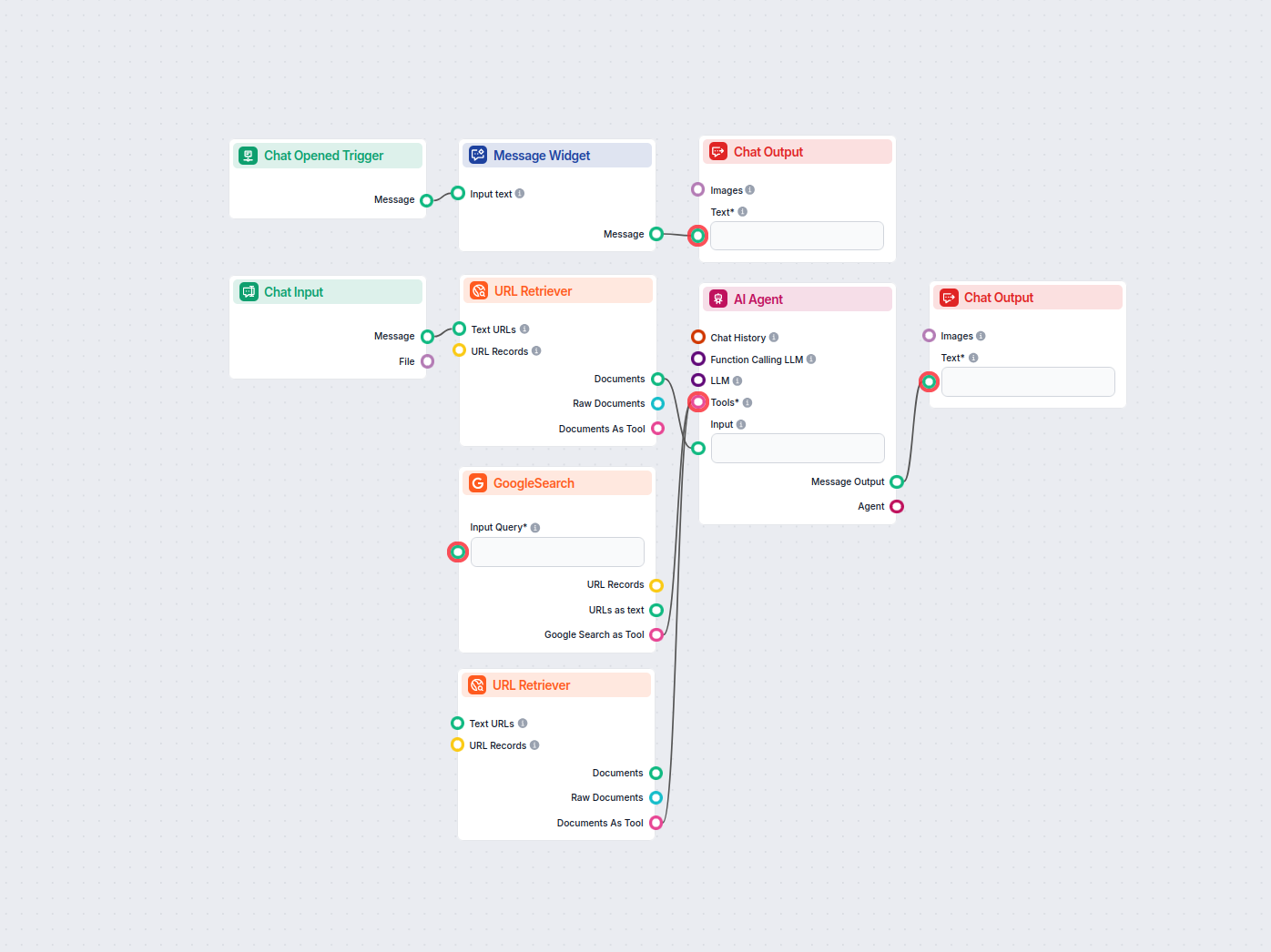
Omvandla valfri sitemap.xml till ett välstrukturerat llms.txt-format med hjälp av AI. Detta arbetsflöde hämtar URL:er från en sitemap, hämtar och bearbetar dera...
Omvandla din webbplats sitemap.xml till ett LLM-vänligt dokumentationsformat automatiskt. Denna AI-drivna konverterare extraherar, bearbetar och strukturerar di...